图论---DFS
图论---DFS
1. 图的遍历
在理解DFS算法之前,我们首先需要对什么是遍历进行了解,遍历的概念就是:从某一个点出发(一般是首或尾),依次将数据结构中的每一个数据访问且只访问一遍。
2. DFS简介
DFS(Depth-First-Search,深度优先搜索)算法的具体做法是:从某个点一直往深处走,走到不能往下走之后,就回退到上一步,直到找到解或把所有点走完。
在实现这一个依次的访问顺序时,操作动作存储与数据结构(栈)的思想及其相似,同时也由于栈的性质,我们可以通过递归来简化栈的创建,因此DFS算法的两种做法分别时利用栈或者递归实现。
算法步骤(递归或栈实现)
a)访问指定起始地点。
b)若当前访问顶点的邻接顶点有未被访问的顶点,就任选一个访问。如果没有就回退到最近访问的顶点,直到与起始顶点相通的所有点被遍历完。
c)若途中还有顶点未被访问,则再选一个点作为起始顶点,并重复前面的步骤。
3. 图的DFS
我们直接以案例进行讲解,就本图而言,其访问顺序可以是(不唯一):1-2-4-5-3
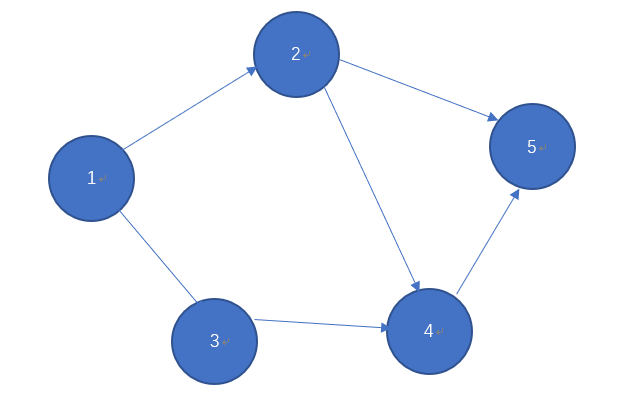
首先从1开始,1结点处可以访问2,3两个结点,那么按照我们自定义的优先顺序线访问2结点,此时,2结点有4,5两个结点访问,依旧按次序访问呢4结点,4结点可以访问5结点,5结点无法继续向下访问故结束访问,并回退4结点,4结点无法没有其他分支且自己已被访问故又退回2结点,2结点的两个分支4,5结点均已被访问,故再退回1结点,此时只有3结点未被访问,访问3结点,最终得到次序:1-2-4-5-3
4.相关代码
DFS算法的相关模板如下:
void dfs()//参数用来表示状态
{
if(到达终点状态)
{
...//根据需求添加
return;
}
if(越界或者是不合法状态)
return;
if(特殊状态)//剪枝,去除一些不需要访问的场景,不一定i俺家
return ;
for(扩展方式)
{
if(扩展方式所达到状态合法)
{
修改操作;//根据题意来添加
标记;
dfs();
(还原标记);
//是否还原标记根据题意
//如果加上(还原标记)就是 回溯法
} }
}
5. 图的DFS代码:
#include<iostream>
using namespace std;
#define matrix_size 20
typedef struct {
int weight;
}AdjMatrix[matrix_size][matrix_size]; struct MGraph{
int vex[matrix_size];
AdjMatrix arcs;
int vexnum,arcnum;
};
bool visited[matrix_size]; int LocateVex(MGraph *G ,int v){
int i;
for ( i = 0; i < G->vexnum; i++)
{
if (G->vex[i]==v)
{
break;
}
}
if (i>G->vexnum)
{
cout<<"not such vertex"<<endl;
return -1;
}
return i;
}
//构造无向图
void CreateDN(MGraph *G){
cin>>G->vexnum>>G->arcnum;
for (int i = 0; i < G->vexnum; i++)
{
cin>>G->vex[i];
}
for (int i=0; i<G->vexnum; i++) {
for (int j=0; j<G->vexnum; j++) {
G->arcs[i][j].weight=0;
}
}
for (int i = 0; i < G->arcnum; i++)
{
int v1,v2;
cin>>v1>>v2;
int n=LocateVex(G,v1);
int m=LocateVex(G,v2);
if (m==-1||n==-1)
{
cout<<"not this vertex"<<endl;
return ;
}
G->arcs[n][m].weight=1;
G->arcs[m][n].weight=1;
}
return ;
}
//输出函数
void PrintGrapth(MGraph G)
{
for (int i = 0; i < G.vexnum; i++)
{
for (int j = 0; j < G.vexnum; j++)
{
cout<<G.arcs[i][j].weight<<" ";
}
cout<<endl;
}
}
void visitVex(MGraph G,int v){
cout<<G.vex[v];
}
int FirstAdjVex(MGraph G,int v){
for (int i = 0; i < G.vexnum; i++)
{
//查找与数组下标为v的顶点之间有边的顶点,返回它在数组中的下标
if (G.arcs[v][i].weight)
{
return i;
}
}
return -1;
}
int NextAdjVex(MGraph G,int v,int w)
{
//从前一个访问位置w的下一个位置开始,查找之间有边的顶点
for(int i = w+1; i<G.vexnum; i++){
if(G.arcs[v][i].weight){
return i;
}
}
return -1;
} void DFS(MGraph G,int v){
visited[v]=true;
visitVex(G,v);
for (int w = FirstAdjVex(G,v); w >0; w= NextAdjVex(G,v,w))
{
if (!visited[w])
{
DFS(G,w);
}
}
}
//深度优先搜索
void DFSTraverse(MGraph G){//
int v;
//将用做标记的visit数组初始化为false
for( v = 0; v < G.vexnum; ++v){
visited[v] = false;
}
//对于每个标记为false的顶点调用深度优先搜索函数
for( v = 0; v < G.vexnum; v++){
//如果该顶点的标记位为false,则调用深度优先搜索函数
if(!visited[v]){
DFS( G, v);
}
}
}
int main() {
MGraph G;//建立一个图的变量
CreateDN(&G);//初始化图
DFSTraverse(G);//深度优先搜索图
return 0;
}
图论---DFS的更多相关文章
- 【做题】Codeforces Round #436 (Div. 2) F. Cities Excursions——图论+dfs
题意:给你一个有向图,多次询问从一个点到另一个点字典序最小的路径上第k个点. 考虑枚举每一个点作为汇点(记为i),计算出其他所有点到i的字典序最小的路径.(当然,枚举源点也是可行的) 首先,我们建一张 ...
- [LLL邀请赛]参观路线(图论+dfs)
emmmm....学校的oj被查水表了,扒不到原题面,所以.... 但是我还是扒到了题面... 题目大意:给定一个完全图,删掉其中一些边,然后求其字典序最小的遍历顺序 有点像去年day2T1啊.... ...
- 图论--DFS总结
1.Key word:①双向DFS ②回溯 今天就看到了这么多DFS,其实DFS更倾向于枚举所有情况. 对于双向DFS,我们考虑看看最短路,起点做一下搜索,记录一下到所有点的距离,终点做一下搜索,记 ...
- PJ可能会考的模拟与枚举-自学教程
PJ可能会考的模拟与枚举-自学教程 文/Pleiades_Antares 之前学校里看一个小可爱复习的时候偷偷听来着XD 简单记了一下重点吧,希望能对看官您有所帮助XD 以下⬇️是几个复习时讲过的题, ...
- NOIP提高组历年真题题解
2018 铺设道路 差分水题,推一下结论就好了. #include<cstdio> #include<algorithm> using namespace std; ],d[] ...
- $NOIp$提高组历年题目复习
写在前面 一个简略的\(NOIp\)题高组历年题目复习记录.大部分都有单独写题解,但懒得放\(link\)了\(QwQ\).对于想的时候兜了圈子的题打上\(*\). \(NOIp2018\ [4/6] ...
- 图论算法之DFS与BFS
概述(总) DFS是算法中图论部分中最基本的算法之一.对于算法入门者而言,这是一个必须掌握的基本算法.它的算法思想可以运用在很多地方,利用它可以解决很多实际问题,但是深入掌握其原理是我们灵活运用它的关 ...
- 用深度优先搜索(DFS)解决多数图论问题
前言 本文大概是作者对图论大部分内容的分析和总结吧,\(\text{OI}\)和语文能力有限,且部分说明和推导可能有错误和不足,希望能指出. 创作本文是为了提供彼此学习交流的机会,也算是作者在忙碌的中 ...
- # 「银联初赛第一场」自学图论的码队弟弟(dfs找环+巧解n个二元一次方程)
「银联初赛第一场」自学图论的码队弟弟(dfs找环+巧解n个二元一次方程) 题链 题意:n条边n个节点的连通图,边权为两个节点的权值之和,没有「自环」或「重边」,给出的图中有且只有一个包括奇数个结点的环 ...
随机推荐
- NTP 集群简略部署指南
NTP 集群简略部署指南 by 无若 1. NTP 简介 网络时间协议(英语:Network Time Protocol,简称NTP)是在数据网络潜伏时间可变的计算机系统之间通过分组交换进行时钟同步的 ...
- 10 个超棒的 JavaScript 简写技巧
今天我要分享的是10个超棒的JavaScript简写方法,可以加快开发速度,让你的开发工作事半功倍哦. 开始吧! 1. 合并数组 普通写法: 我们通常使用Array中的concat()方法合并两个数组 ...
- 跟我一起写 Makefile(十二)
隐含规则 ---- 在我们使用Makefile时,有一些我们会经常使用,而且使用频率非常高的东西,比如,我们编译C/C++的源程序为中间目标文件(Unix下是[.o]文件,Windows下是[.obj ...
- Dired Mode in Emacs
Start up Dired mode: C-x d; (List dirs: C-x C-d) Hide Dired mode window: q; Mark Mark (for group man ...
- Linux平台上转换文件编码
Linux系统的iconv指令是一个很好的文件编码转换工具,支持的编码范围广,使用方便,例如将一个utf-8编码的文件(名为tic)转换为gbk编码: iconv -f utf-8 -t gbk ti ...
- Golang语言系列-17-Gin框架
Gin框架 Gin框架简介 package main import ( "github.com/gin-gonic/gin" "io" "net/ht ...
- Windows内核开发-6-内核机制 Kernel Mechanisms
Windows内核开发-6-内核机制 Kernel Mechanisms 一部分Windows的内核机制对于驱动开发很有帮助,还有一部分对于内核理解和调试也很有帮助. Interrupt Reques ...
- 数据结构与算法-排序(九)基数排序(Radix Sort)
摘要 基数排序是进行整数序列的排序,它是将整数从个位开始,直到最大数的最后一位截止,每一个进位(比如个位.十位.百位)的数进行排序比较. 每个进位做的排序比较是用计数排序的方式处理,所以基数排序离不开 ...
- NOIP 模拟 $17\; \rm 时间机器$
题解 \(by\;zj\varphi\) 一道贪心的题目 我们先将节点和电阻按左边界排序,相同的按右边界排序 对于每一个节点,我们发现,选取左边界小于等于它的电阻中右边界大于它且最接近的它的一定是最优 ...
- 神州战神U盘安装windows10系统,启动项制作好后,在bios中识别不到自己的u盘问题
我笔记本是神州战神,启动盘做完了后,按快捷键F2,进入boot下进行设置,找了半天没找到自己的u盘,很郁闷,捣鼓了半天才搞定,以下是我修改之后的设置: 1.把Secure Boot设置为disable ...