手把手教会你远程Linux虚拟机连接以及配置pytorch环境。
出一期用于连接远程Ubuntu系统并配置pytorch环境的教学。2021-07-07 13:35:57-
现在的矿难导致显卡大幅度的涨价对很多要做深度学习领域的小伙伴们非常的不友好,配置设备固然要掏空钱包,那么租个云GPU变成个非常经济的选择!
但是用黑框命令行操控的Linux系统对很对习惯了用wingdows的同学显的十分不友好!
于是乎,我出了今天这期教程!
Xshell 7(win系统)是一个用于MS Windows平台的强大的SSH、TELNET和RLOGIN终端仿真软件。它使得用户能轻松和安全地从Windows PC上访问UniX/Linux主机。
简单地说,X shell就是一个终端模拟软件,就是模拟服务器所在的linux,在Xshell中可以输入命令,就像在服务器的linux中输入命令一样,从而实现远程控制服务器。
下面放上基础的Xshell 7使用教程,介绍一点Xshell使用技巧。
登录服务器
Xshell 7使用教程的第一部分当然是登录服务器了。
第一步,登录首先需要我们拥有一台服务器,这样你就有服务器的IP地址、账户和密码。
第二步,打开Xshell 7,这时会打开两个相叠的窗口,点击上面一个窗口的新建来新建一个新的会话。
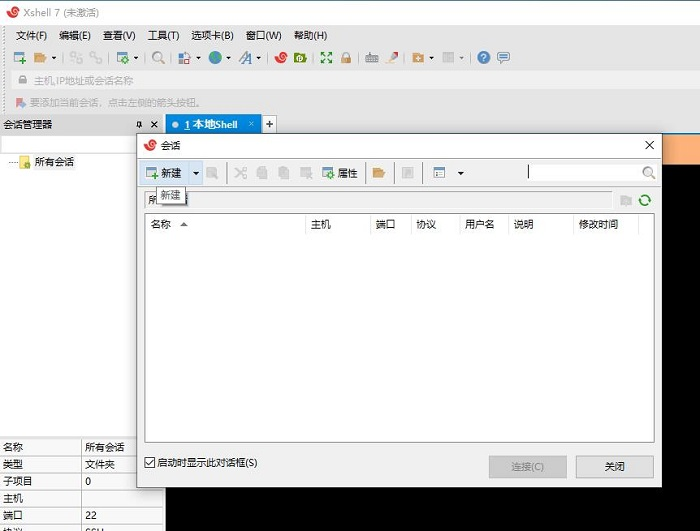
第三步,修改名称以区别主机,并在主机后面的方框中正确地输入你所拥有的服务器的IP地址。
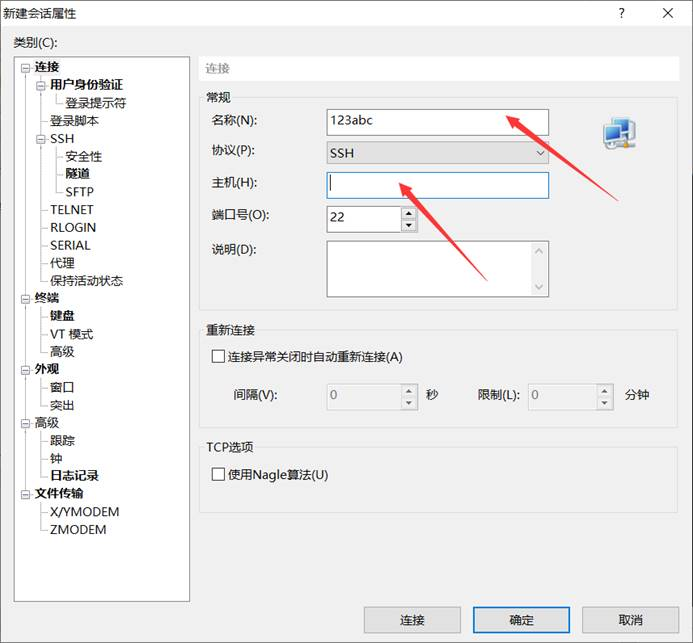
第四步,点击左侧类别中的用户身份验证,然后在对应位置输入你的服务器的用户名和密码。然后点击确认就可以登陆了。
常用快捷键
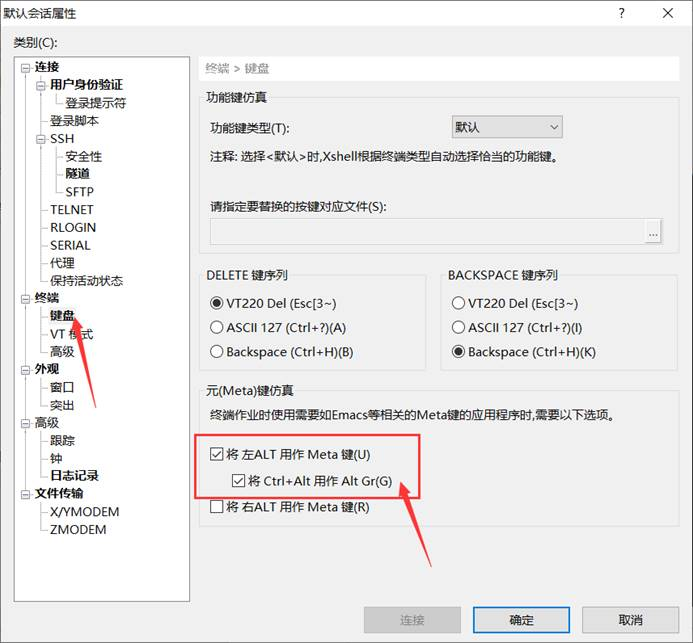
Xshell 7使用教程当然少不了介绍一些常用的快捷键。在介绍快捷键之前,我们首先要完成一个设置。在菜单栏文件中选择默认会话属性,在左侧选择键盘,将下图方框中的两个选项勾上,操作更加方便。
下面就进入Xshell 7使用教程快捷键的介绍。
Ctrl+f 向后移动一个字符
Ctrl+b 向前移动一个字符
Ctrl+a 将光标移至输入行头,相当于Home键
Ctrl+e 将光标移至输入行末,相当于End键
Alt+f 以单词为单位,向前移动
Alt+b 以单词为单位,向前移动
Shift+PgUp 将终端显示向上滚动
Shift+PgDn 将终端显示向下滚动
Alt+s 切换到简单版模式
Alt+Enter 切换至全屏
Ctrl+s 锁住终端,可用来停留在当前屏
Ctrl+q 解锁终端,恢复刷屏
Ctrl+d 键盘输入结束或退出终端
Ctrl+s 暂停当前程序,暂停后按下任意键恢复运行
Ctrl+z 将当前程序放到后台运行,恢复到前台为命令fg
Ctrl+Shift+r 重新连接
Ctrl+Insert 复制
Shift+Insert 粘贴
好了,Xshell 7使用教程就先介绍到这里
接下来是CUDA的安装教程!
查看显卡是否支持CUDA
基本的环境
首先了解自己服务器的操作系统内核版本等信息:
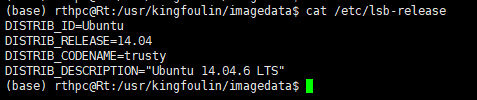
查看自己操作系统的版本信息:cat /etc/issue或者是 cat /etc/lsb-release等命令
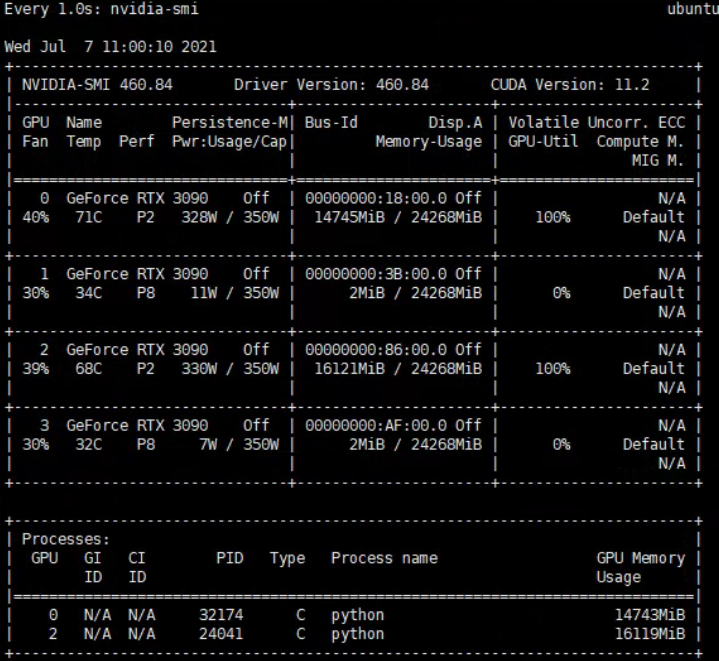
查看服务器显卡信息:
lspci | grep -i nvidia查看全部显卡信息。nvidia-smi如果已经安装了对应的显卡驱动的话可以采用这个命令。cat /proc/driver/nvidia/version查看安装的显卡的驱动信息。
CUDA驱动可以去英伟达官网自行下载安装。如果不会安装的同学可以看这个教程https://zhuanlan.zhihu.com/p/79059379
创建虚拟环境,构建pytorch环境!
1、进入官网选择要下载的版本和操作系统
https://www.anaconda.com/distribution/

安装
一、
找到下载好的文件名为Anaconda3-xxxx-Linux-x86_64的安装包,如果你是通过自己的电脑下载的安装包,想在服务器上面安装Anaconda,那么你可以通过scp命令传输安装包到Centos服务器。如果你是在服务器上面下载的,那么请略过此步。
传输命令为:scp Anaconda3-xxxx-Linux-x86_64 aliyun@192.168.1.122:/home 然后根据提示输入密码即可。
等待读条完成后,就将安装包传输到了Centos服务器。
二、或者通过xftp 上传到服务器home文件夹下
接着进入终端到Anaconda3-2018.12-Linux-x86_64.sh目录下:
在Linux里面.sh文件是可执行的脚本文件,需要用命令bash来进行安装。
此时我们输入命令bash Anaconda3-2018.12-Linux-x86_64.sh
然后开启安装,在安装过程中,基本上不断按回车或者yes默认就行了。
环境变量配置
安装完成后,我们还需要对环境变量进行添加,方便我们启动。
无论是哪种内核(版本)的系统,都可以通过修改/etc/profile或者/etc/bashrc的配置信息来达到设置环境变量的目的
在这里我们修改profile文件
sudo vi /etc/profile
输入密码后进入文件编辑
这里sudo是加权限类似root用户进行操作,vi是一种编辑器
这里的i代表INSERT输入模式,然后按向下键切换到最下面,
在文件的末尾加上下述代码:
export PATH=$PATH:/home/software/anaconda3/bin
这个地址是自己安装的anaconda3的路径
按下ESC键,输入:,然后输入wq按下回车就保存退出了
最后重新载入配置文件,输入source /etc/profile
完成上述步骤,环境变量就配置好
测试
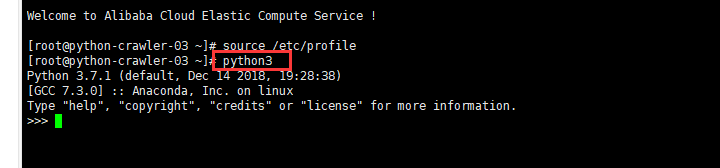
打开终端(Terminal),输入python3,如果显示如下图,则表示安装成功。
conda创建并激活虚拟环境
命令:
conda create -n your_env_name python=2.7/3.6
source activate your_env_name
其中,-n中n表示name,即你创建环境的名字。
之后如果忘记自己创建的环境的名字,可以查看conda中的环境:
conda env list
之后选择你创建的环境激活。之后进入pytorch官网选择你要安装的版本以及操作系统、CUDA版本号,便可以得到下载的命令。比如本人得到的命令是:
conda install pytorch torchvision cuda80 -c pytorch
若不知道自己CUDA的版本号,可以输入下面命令查询:
cat /usr/local/cuda/version.txt
若希望快速下载,可以把源换为国内的镜像源,从而提高下载速度。在下载前输入:
vim ~/.condarc
打开文件后,输入:
channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- defaults
show_channel_urls: true
若配置好环境后需要别的包,用conda或者pip下载皆可
运行py文件
直接调用指令 python xxxxx.py 即可
编辑py文件
直接调用指令 vi xxxxx.py即可
pytorch下多GPU并行运行教程
1. nn.DataParallel
|
1
|
torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0) |
- module -要并行化的模块
- device_ids (python列表:int或torch.device) - CUDA设备(默认:所有设备)
- output_device (int或torch.device) -输出的设备位置(默认:device_ids[0]) (用于汇总梯度信息的设备)
在模块级别实现数据并行。此容器通过在批尺寸维度中分块(其他对象将在每个设备上复制一次),在指定的设备上分割输入,从而并行化给定模块的应用程序。
在正向传递过程中,模型被复制到每个设备上,每个副本处理输入的一部分。在向后传递过程中,每个副本的梯度将累加到原始模块中。
批尺寸的大小应该大于所使用的gpu的数量。
https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
|
1
2
|
if torch.cuda.device_count() > 1: model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0]) |
DataParallel 可以自动拆分数据并发送作业指令到多个gpu上的多个模型。在每个模型完成它们的工作之后,dataparparallel收集并合并结果,然后再返回给您。
DataParallel 使用起来非常方便,我们只需要用 DataParallel 包装模型,再设置一些参数即可。需要定义的参数包括:参与训练的 GPU 有哪些,device_ids=gpus;用于汇总梯度的 GPU 是哪个,output_device=gpus[0] 。DataParallel 会自动帮我们将数据切分 load 到相应 GPU,将模型复制到相应 GPU,进行正向传播计算梯度并汇总。
DataParallel 仅需改动一行代码即可。但是DataParallel 速度慢,GPU 负载存在不均衡的问题。
2. 使用 torch.distributed 加速并行训练
It is recommended to use DistributedDataParallel, instead of DataParallel to do multi-GPU training, even if there is only a single node.
对于单节点多GPU数据并行训练,事实证明,DistributedDataParallel的速度明显高于torch.nn.DataParallel。
torch.nn.parallel.DistributedDataParallel(module, device_ids=None, output_device=None, dim=0, broadcast_buffers=True, process_group=None, bucket_cap_mb=25, find_unused_parameters=False, check_reduction=False, gradient_as_bucket_view=False)
在模块级别实现基于torch.distributed包的分布式数据并行。
此容器通过在批尺寸维度中分组,在指定的设备之间分割输入,从而并行地处理给定模块的应用程序。模块被复制到每台机器和每台设备上,每个这样的复制处理输入的一部分。在反向传播过程中,每个节点的梯度取平均值。
批处理的大小应该大于本地使用的gpu数量。
输入的约束与torch.nn.DataParallel中的约束相同。
此类的创建要求torch.distributed已通过调用torch.distributed.init_process_group()进行初始化。
要在具有N个GPU的主机上使用DistributedDataParallel,应生成N个进程,以确保每个进程在0到N-1的单个GPU上独自工作。这可以通过为每个进程设置CUDA_VISIBLE_DEVICES或调用以下命令来完成:
|
1
|
torch.cuda.set_device(i) |
i从0到N-1。 在每个进程中,都应参考以下内容来构造此模块:
|
1
2
3
|
torch.distributed.init_process_group(backend='nccl', world_size=N, init_method='...')model = DistributedDataParallel(model, device_ids=[i], output_device=i) |
为了在每个节点上生成多个进程,可以使用torch.distributed.launch或torch.multiprocessing.spawn。
如果使用DistributedDataParallel,可以使用torch.distributed.launch启动程序,请参阅第三方后端(Third-party backends)。
当使用gpu时,nccl后端是目前最快的,并且强烈推荐使用。这适用于单节点和多节点分布式训练。
区别
DistributedDataParallel和DataParallel之间的区别是:DistributedDataParallel使用多进程,其中为每个GPU创建一个进程,而DataParallel使用多线程。
通过使用多进程,每个GPU都有其专用的进程,从而避免了Python解释器的GIL导致的性能开销。
手把手教会你远程Linux虚拟机连接以及配置pytorch环境。的更多相关文章
- Linux环境搭建 | 手把手教你安装Linux虚拟机
前言 作为一名Linux工程师,不管是运维.应用.驱动方向,在工作中肯定会需要Linux环境.想要获得Linux环境,一个办法就是将电脑系统直接换成Linux系统,但我们平常用惯了Windows系统, ...
- 在VMware上克隆Linux虚拟机及其网卡配置方法
最近在搭建Hadoop集群,1个Master,3个Workers.使用VMware workstations创建Linux虚拟机,版本是CentOS7.安装完成并做了相应的网络配置后,使用VMware ...
- [eShopOnContainers 学习系列] - 03 - 在远程 Ubuntu 16.04 上配置开发环境
直接把 md 粘出来了,博客园的富文本编辑器换成 markdown,没啥效果呀 ,先凑合吧.实在不行换地方 # 在远程 Ubuntu 16.04 上配置开发环境 ## 零.因 为什么要用这么麻烦的 ...
- SSH服务搭建、账号密码登录远程Linux虚拟机、基于密钥的安全验证(Windows_Xshell,Linux)
问题1:如果是两台虚拟机ping不同且其中一个虚拟机是克隆的另一个,需要更改一下MAC地址,关机状态下 一> "编辑虚拟机设置" 一>" 网络适配器" ...
- Linux虚拟机下安装配置MySQL
一. 下载mysql5.7 http://mirrors.sohu.com/mysql/MySQL-5.7/ Linux下载: 输入命令:wget http://mirrors.sohu.c ...
- VMware中对Linux虚拟机的网络配置静态IP的配置
前言 踏出象牙塔,进入公司,由于公司的所有产品都是Linux下的,必然自己这段时间需要在自己的工作机器先学习一下.项目代码是用Source Insight进行查看的,总是Ctrl + Alt的切来切去 ...
- Linux虚拟机中 Node.js 开发环境搭建
Node.js 开发环境搭建: 1.下载CentOS镜像文件和VMWare虚拟机程序; 2.安装VMWare——>添加虚拟机——>选择CentOS镜像文件即可默认安装带有桌面的Linux虚 ...
- Xshell访问本地或者远程Linux虚拟机
背景 在本地PC机上安装了VMware workstation和Ubuntu系统,但是每次访问虚拟机都需要输入登陆密码,比较不方便.为此,通过Xshell来访问虚拟机,提高工作效率. 步骤 1.打开虚 ...
- 关于Linux虚拟机连接不上网络的问题
前阵子自学Linux(版本是CentOS6 -VMware ),因为连不上网的问题搁置了一段时间,昨天又重新拾起来,花了一下午时间终于搞定.下面说几点,给自己学习历程一个记录,也希望能帮到其他初学者. ...
随机推荐
- [刷题] 17 Letter Combinations of a Phone Number
要求 给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合 1 不对应任何字母 示例 输入:"23" 输出:["ad", "ae&q ...
- jolokia配置Java监控
wget http://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.3.6/jolokia-jvm-1.3.6- ...
- Python实现TCP通讯
Environment Client:Windows Server:KaLi Linux(VM_virtul) Network:Same LAN Client #!/usr/bin/python3 # ...
- 【IBM】netperf 与网络性能测量
netperf 与网络性能测量 汤凯2004 年 7 月 01 日发布 WeiboGoogle+用电子邮件发送本页面 2 在构建或管理一个网络系统时,我们更多的是关心网络的可用性,即网络是否连通,而对 ...
- Java 常量值的数据类型
Java 常量值(也叫字面量)和变量一样,也是有数据类型的. 经常有面试题考察你对 Java 常量值数据类型的理解,如下: float a = 3.3; 问你这一行代码是否正确?答案肯定是不正确.为什 ...
- STM32标准外设库中USE_STDPERIPH_DRIVER, STM32F10X_MD的含义
在项目中使用stm32标准外设库(STM32F10x Standard Peripherals Library)的时候,我们会在项目的选项中预定义两个宏定义:USE_STDPERIPH_DRIVER, ...
- fprintf函数
描述 C 库函数 int fprintf(FILE *stream, const char *format, ...) 发送格式化输出到流 stream 中. 声明 下面是 fprintf() 函数的 ...
- 使用nuget包下载Entity Framework6.0无法使用模型类与数据库上下文自动生成controller与view
解决方法:卸载掉原有的6.0版本EF,从控制台安装5.0版本的. >工具>库程序包管理器>程序包管理器控制台.在PM>后面输入安装命令. 命令如下 Install-Packag ...
- 设计模式Immutability
1.什么是Immutability Immutability,不变性, 叫做不变性设计模式,简单来说就是对象一旦创建,状态就不再发生变化. 变量一旦被赋值,就不允许修改了(没有写操作):没有修改操作, ...
- 智能物联网(AIoT,2020年)(下)
智能物联网(AIoT,2020年)(下) 12工业物联网是AIoT在工业领域第一战场 工业物联网分为感知.决策.执行,OS与软件是大脑+神经 13工业场景下一步如何使用AIoT 不止工业物联网:用人工 ...