Beta_测试说明
Beta阶段测试说明
测试发现的BUG
Beta阶段测试BUG:
测试发现的BUG都放在BUG FIX里面
GitHUB issue BUG FIX
- 后端:实体识别结果重复。
解决:把处理结果的id和label绑定,这样就不会出现重复的label - 后端:预测结果顺序不一致且没有处理,导致Excel文件数据不对应
解决:处理时根据对应字段填写,不是顺序填写 - 后端:生成的表单的日期格式为 日/月/年,Excel只能识别年/月/日,待改进
解决:修改了格式 - 前端:Train页面在type2类型时, 训练有时提示label文件不足
解决:经查证是OCR超时导致,可以刷新再次训练 - 前端: 打开Cloud Project会出现 Security Token Not Found
解决:这是因为在appSettings里面没有关于该项目的token(被视为项目不是你的),所以不能打开
处理办法:
- 提示并从list中删除
- 仅提示 - 前端: ExcelVisual在后端报错时不会提示错误而是下载一个错误的xlsx
解决:进行提示并阻止下载 - BUG:表单预测服务无法使用
解决:之前的服务被莫名阻止,无法正常使用,重新申请了一个服务 - 前端:data页面显示问题
解决:mark表单是在生成的时候使用的,生成后会自动删除,不会产生影响
Alpha阶段遗留的BUG有:
测试方案
前端:
zyc、lzh:
对于每一个issue会开启一个名为issue-(issue_number)-(name)的分支,在其上进行开发,开发完成后进行自动化测试和浏览器中的实际操作测试。
测试包括以下部分,逐一进行检查:
- Jest自动化测试
- 被修改组件的功能是否符合期望。
- 页面的功能是否正常。
- 进行完整的工作流程,检查是否存在错误和异常。
测试正常后会合并到dev分支,进行代码复审。
每天将复审后的dev分支合并到master分支。
使用tslint进行前端代码的规范,使用的规则如下:
{
"defaultSeverity": "error",
"extends": [
"tslint:recommended"
],
"jsRules": {},
"rules": {
"object-literal-sort-keys": false,
"no-console": false,
"no-empty-interface": false,
"no-shadowed-variable": false,
"ordered-imports": false,
"no-string-literal": false,
"no-bitwise": false,
"function-constructor": false,
"linebreak-style": [true, "LF"]
},
"rulesDirectory": []
}
每次提交和复审时确保没有tslint的错误和警告。

后端:
llj:
代码经过复审后再合并进master,主要测试的是调用接口对多种实体的识别情况,测试样例中涵盖我们所需要处理的字段以及不匹配实体的字段:

代码覆盖率:
wyk:
使用pylint做代码格式审查,风格良好:

使用unittest做单元测试,构造多个测试函数:
运行结果良好
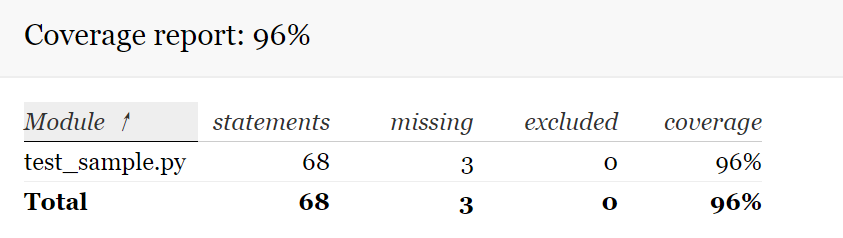
使用coverage做覆盖率测试,结果如下:
dxy:
代码规范:

使用pylint进行代码规范的度量,取得满分
测试样例:
PDF:
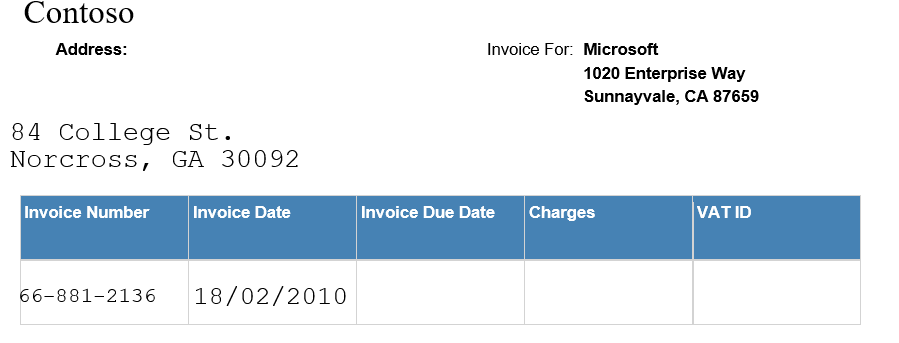
JSON1:

JSON2:

如图所示,PDF部分是随机生成的一个表单,其中的地址数据被生成为了两行,同时还包括了表格中自带的数据。beta部分的数据生成工作需要自动识别文字的位置,从而将其实体识别为各种类别,进而进行数据的训练工作。
利用微软OCR项目,可以直接得到PDF对应的json,但是经过观察json发现,OCR工具会将中间有过大空格的文字或两行文字,识别成多个词条。这样导致的结果就是,像地址等信息就会被自动拆开,如JSON2所示,而无法正常训练。并且OCR工具还会把原本存在于表格上的文字也识别进去,如JSON1所示,所以数据生成部分做的处理是,首先将原本存在的文字数据进行多文本比对,进行去除;之后按照相对位置、文字大小等属性,将原本属于同一词条但被分成了多条的数据进行自动拼接。
测试结果:
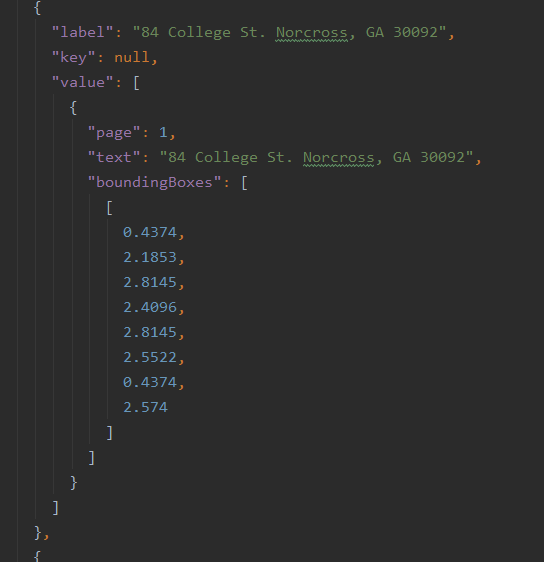
可以看出,本来被分开的数据现在被拼接到了一起,同时,在json文件中,也删除掉了表格中本来存在的字段,后者因为不便展示,仅说实现思路。思路为:传入多个PDF,检测识别出的完全相同的多个部分,则一定是表格中原本存在的文字,可以直接删除。
ly:
对后端http服务器进行测试,主要测试API的正确性,采用Postman来进行测试。
举例:
上传JSON文件
请求类别 参数或者数据 是否成功 反馈信息 GET type=1 否 Well, please use POST to upload the json file! POST 没有path参数 否 Wrong in path parameter! You should give the path! POST type=1 出现异常 Upload failed, please try again! POST type=1 是 We have get the data: [上传的JSON数据] 上传PDF模板
请求类别 参数或者数据 是否成功 反馈信息 GET type=1 否 Well, you should use POST to upload pdf template! POST 没有path参数 否 Wrong in path parameter! You should give the path! POST type=1 出现异常 Upload failed, please try again! POST type=1 是 We have get the data! 请求生成
请求类别 参数或者数据 是否成功 反馈信息 GET|POST 没有path参数 否 Wrong in path parameter! You should give the path! GET|POST —— 异常 readjson and getlabel wrong! GET|POST —— 异常 genData wrong! GET|POST —— 异常 open mark fail! GET|POST —— 成功 We have generated * files! You can just download them! 请求下载
请求类别 参数或者数据 是否成功 反馈信息 GET|POST 没有path参数 否 Well, you should give the 'path' parameter! GET|POST —— 出现异常 DownLoad wrong, please try again! GET|POST —— 是 pdf和对应的JSON文件zip包 自动处理
请求类别 参数或者数据 是否成功 反馈信息 GET|POST 没有path参数 否 'path' parameter is needed! GET|POST —— 出现异常 Azure自带的异常信息 GET|POST —— 是 Get it
场景测试
李华
| 用户信息 | 用户情况 |
|---|---|
| 姓名 | 李华 |
| 用户身份 | 高一3班英语课代表 |
| 用户情况 | 处理同学们的调查问卷,由于无法直接导入到Excel,需要手动处理 |
| 用户痛点 | 有急事,需要快速处理这些表单 |
| 典型场景 | 北航附中的学生开学了,今天高一3班的同学们填写了一份关于疫情期间线上英语学习的调查问卷,李华作为英语课代表,老师让他处理这些表单,但是他还没有写完英语作文,你可以帮帮他吗? |
| 预期场景 | 李华发现了我们的软件 李华使用软件,上传了5份用来训练 训练结束后李华批量处理了所有的表单并且得到了处理后的Excel文件 李华完成了工作 |
我们的软件提供自动训练模型的功能,只需要用户上传5份填好数据的同类型表单,即可进行训练,之后就可以用来批量处理表单,并支持下载处理结果的Excel!
回归测试
Alpha阶段的主要功能是上传一个PDF模板,进行标注,根据标注的信息来自动生成若干个填好数据的表单。
Beta阶段基于这一功能,实现了训练表单识别模型的功能。在生成数据的基础上,直接用生成的数据来训练模型,并且拿训练好的模型预测处理“新表单”
测试用例
这里的回归测试是基于当前Beta阶段稳定版本,测试之前表单数据生成的功能的完整性和正确性,从两个方面进行
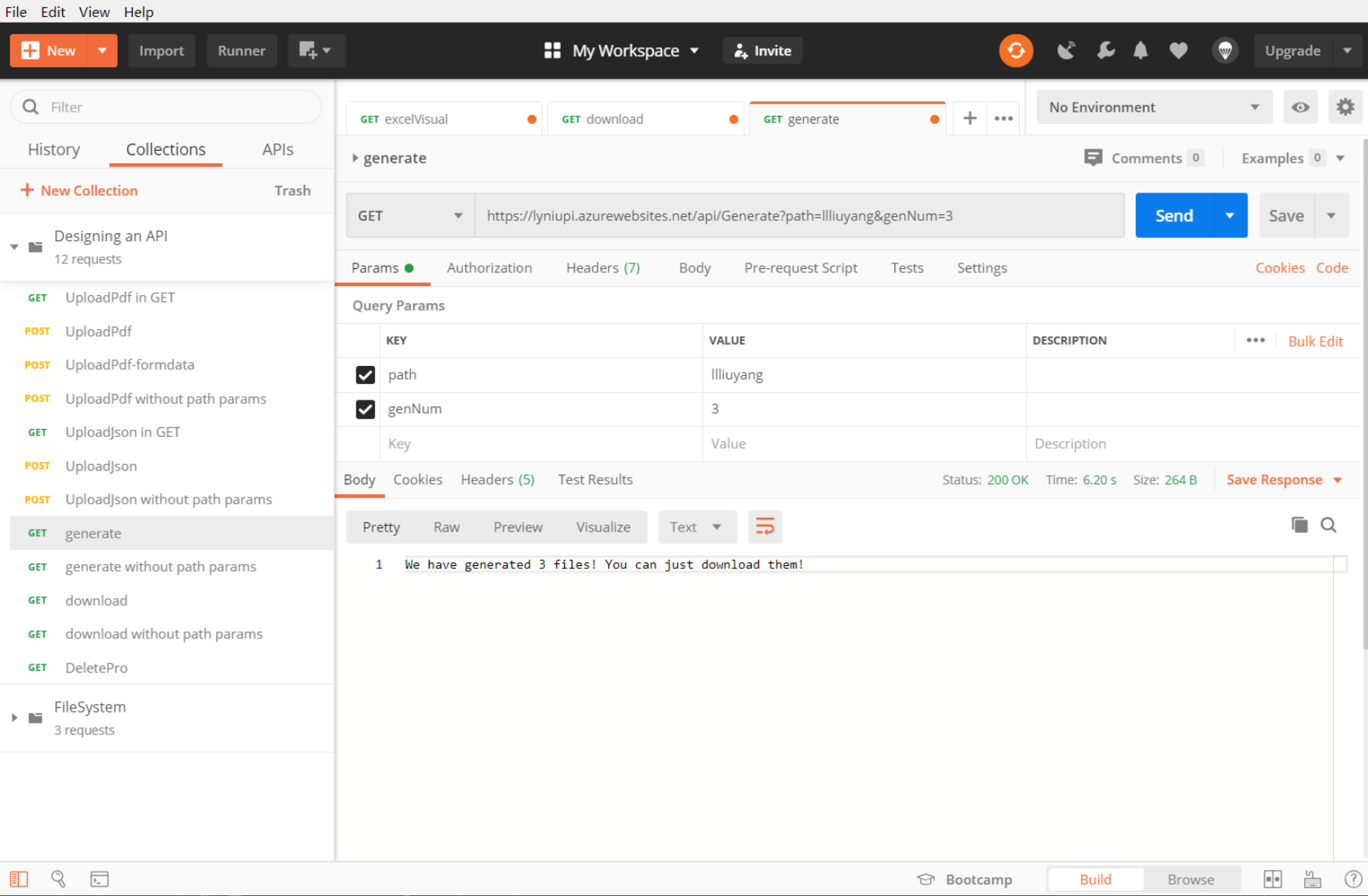
- 后端API测试:Postman + 后端API
- Postman调用API
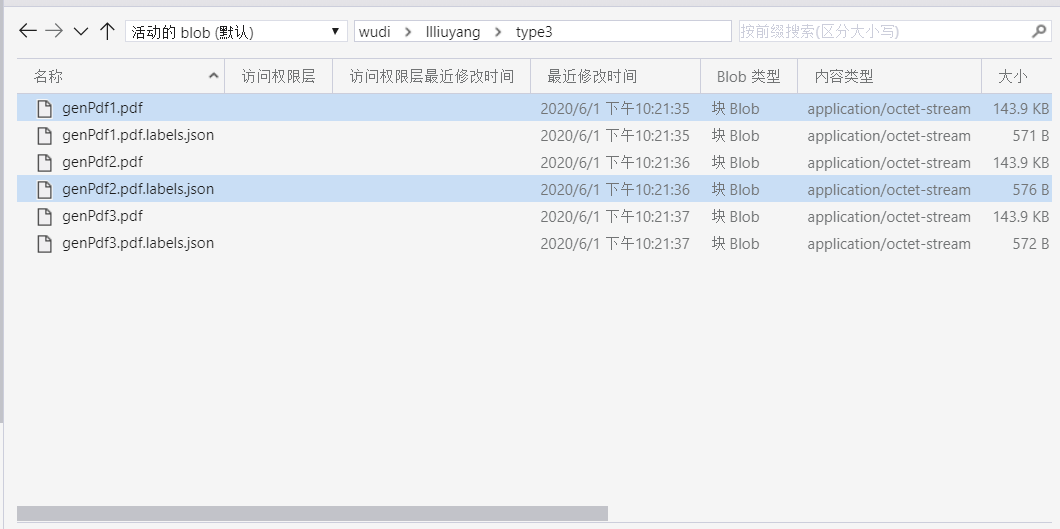
- 后台数据库生成的数据
- 前后端结合测试,直接使用Beta阶段的前端界面来测试Alpha阶段的功能
- 标注:(为了展示方便只标注了两个字段)
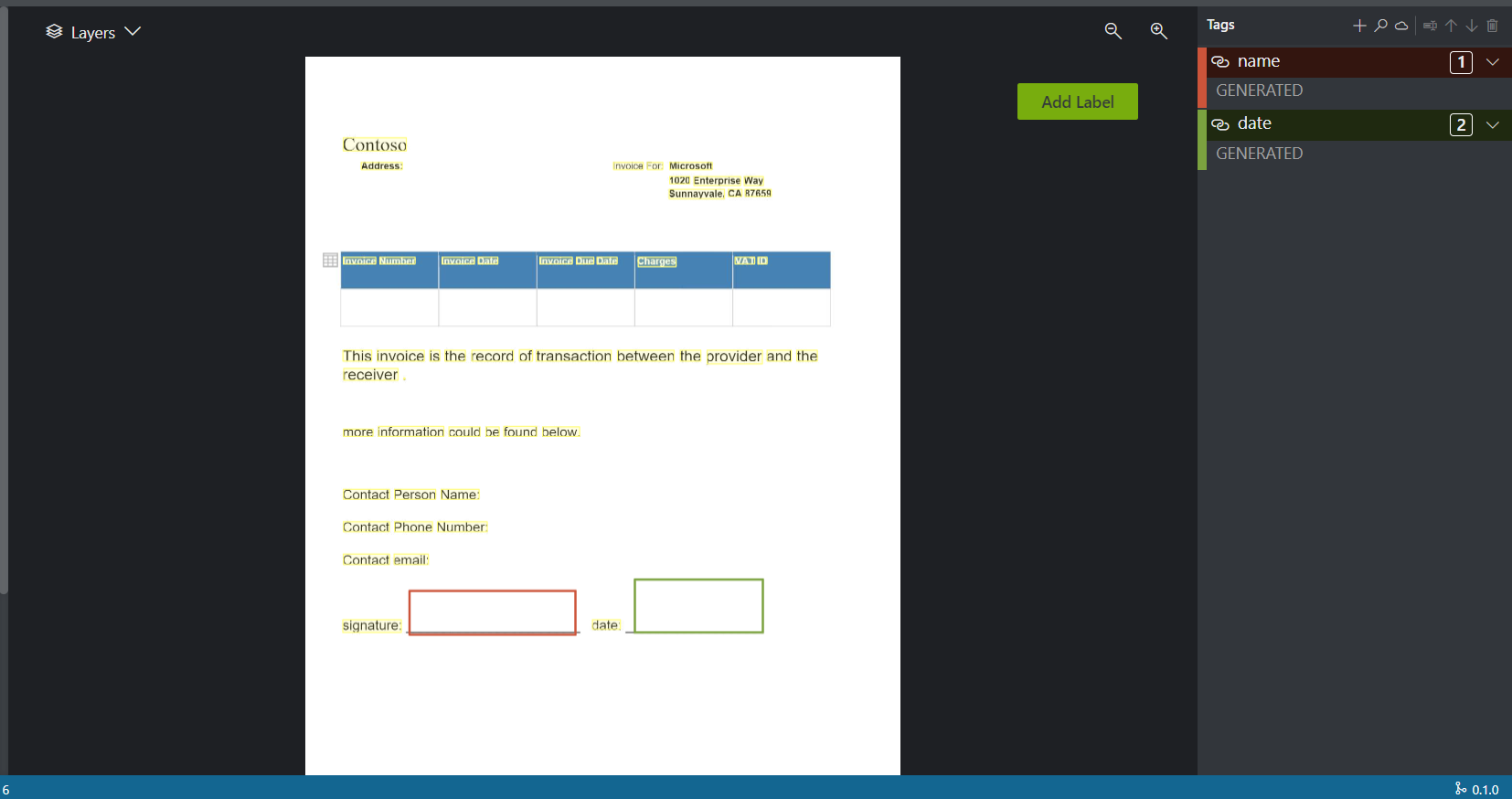
- 数据生成:
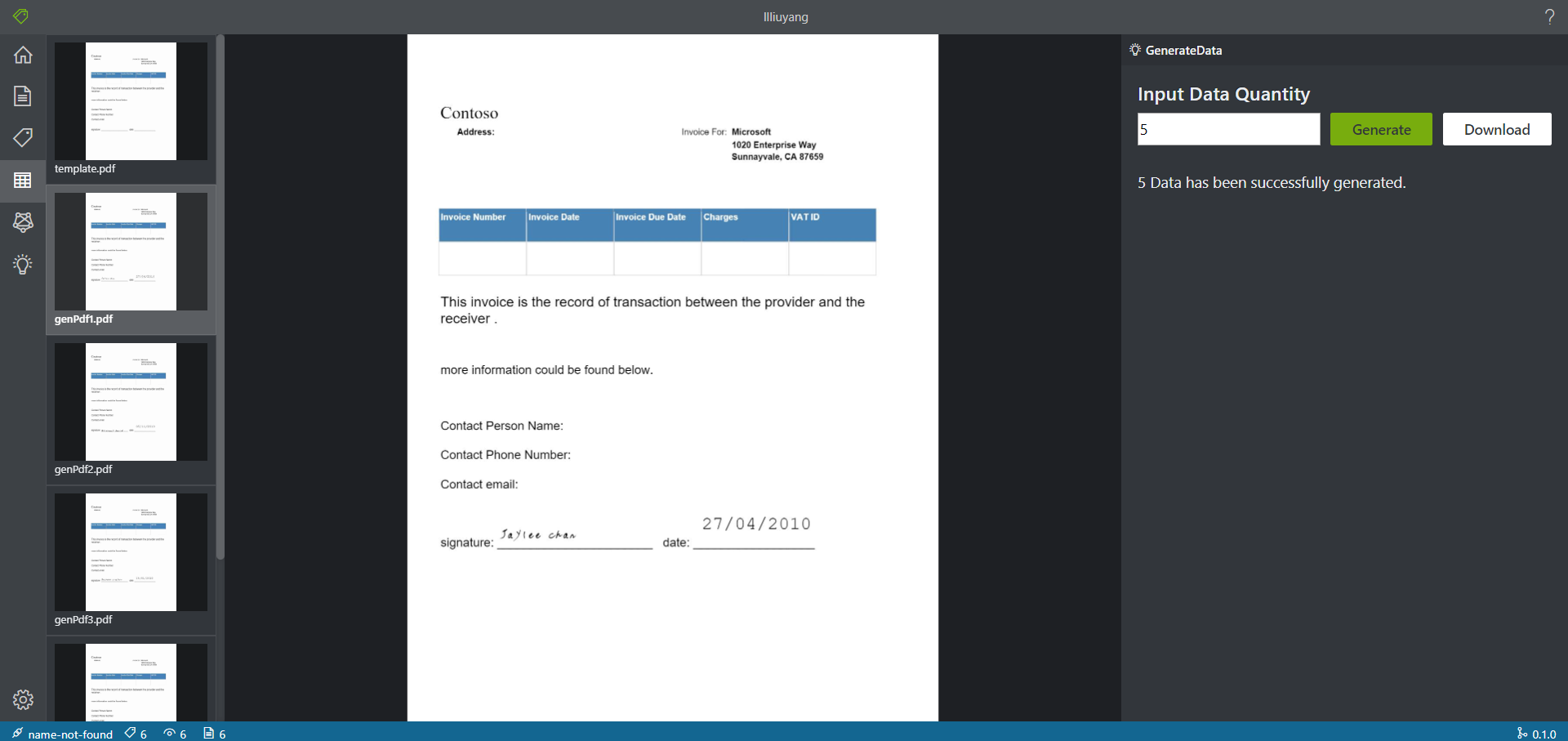
- 下载:
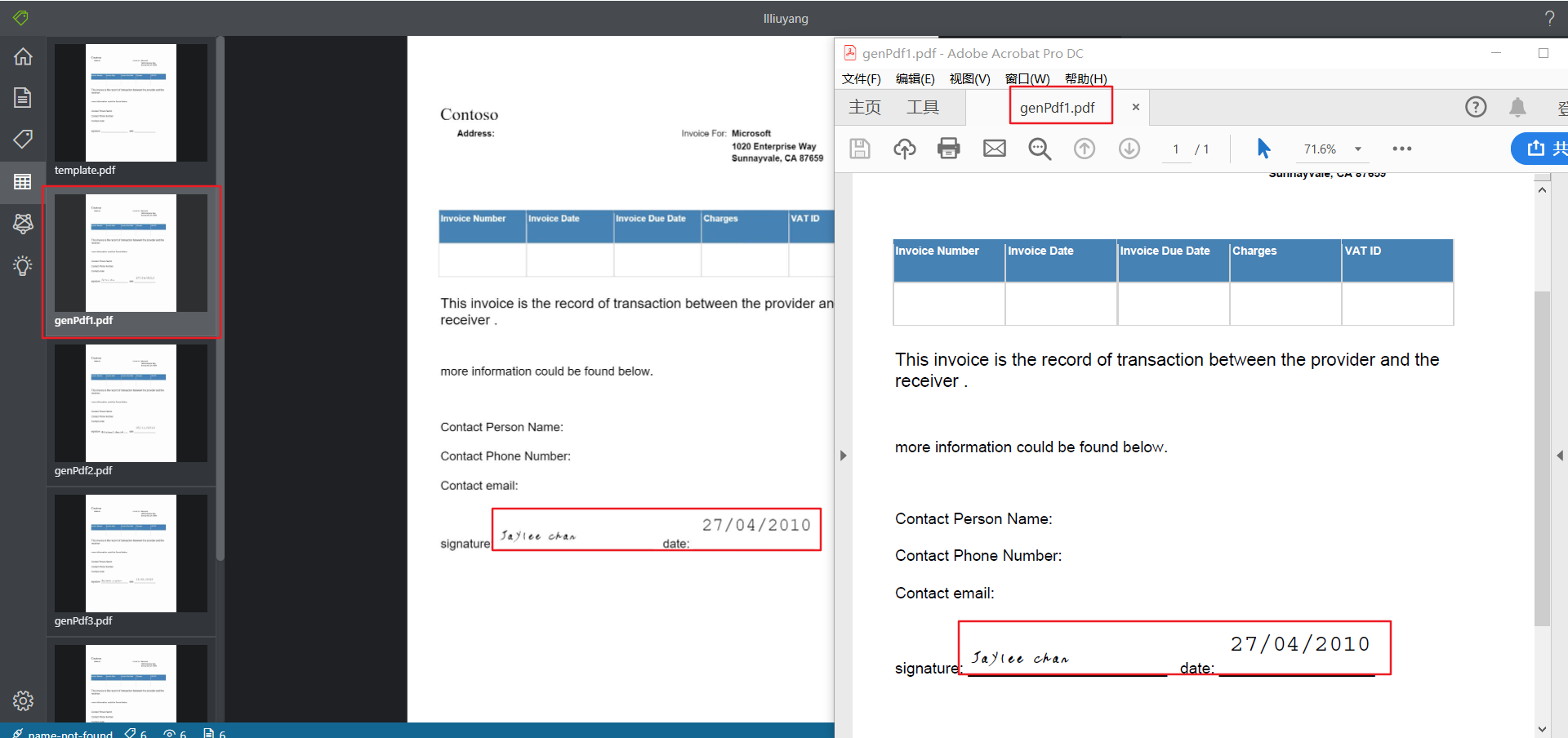
测试矩阵
基于chromium的浏览器均可以正常使用。
主流浏览器基本都可以正常使用我们的软件。
| 操作系统 | 浏览器类型 | 是否正常 |
|---|---|---|
| win10 | Microsoft Edge(版本号81.0.416.68 ) | 可以正常显示和使用 |
| win10 | Internet Explorer(版本号11.778.18362.0) | 不正常。该版本最后发布日期应该是2015年,比较老旧,无法正常显示,升级到chrome内核后可以正常使用 |
| win10 | Google Chrome(版本号81.0.4044.129) | 可以正常显示和使用 |
| win10 | FireFox(72.0.2 (64 位)) | 可以正常显示与使用 |
| win10 | 360浏览器 | 无法正常使用,频繁报错,暂时没有找到解决方案 |
| Ubuntu16.04 | Google chrome | 可以正常显示和使用 |
| Android9 | 华为手机自带浏览器(版本号5.0.420) | 可以正常显示,并且界面大小比较合适。但由于部分操作涉及键盘,在使用时存在困难。 |
| IOS13 | Safari | 可以正常显示,但是手机端使用不便 |
出口条件
- Beta阶段新功能实现
- 表单识别模型的训练
- 自动化训练模型
- 表单预测
- 表单预测结果自动化处理
- 数据结果可视化展示
- Alpha阶段功能完善
- 标注页面数据同步问题
- Introduction页面
- 回归测试+测试矩阵
以上的部分目前都已经实现,所以认为项目当前可以发布!
Beta_测试说明的更多相关文章
- 正则表达式测试器 beta_
说明:"言简意赅".简而从之:如题※网上已经有很多正则的测试工具了※感谢小Z推荐了一款非常好的(但是个别子匹配项多时卡顿.应该是我的表达式问题)故而花了点时间照着“抄”了一个,并配 ...
- SignalR系列续集[系列8:SignalR的性能监测与服务器的负载测试]
目录 SignalR系列目录 前言 也是好久没写博客了,近期确实很忙,嗯..几个项目..头要炸..今天忙里偷闲.继续我们的小系列.. 先谢谢大家的支持.. 我们来聊聊SignalR的性能监测与服务器的 ...
- Apache Ignite之集群应用测试
集群发现机制 在Ignite中的集群号称是无中心的,而且支持命令行启动和嵌入应用启动,所以按理说很简单.而且集群有自动发现机制感觉对于懒人开发来说太好了,抱着试一试的心态测试一下吧. 在Apache ...
- 测试一下StringBuffer和StringBuilder及字面常量拼接三种字符串的效率
之前一篇里写过字符串常用类的三种方式<java中的字符串相关知识整理>,只不过这个只是分析并不知道他们之间会有多大的区别,或者所谓的StringBuffer能提升多少拼接效率呢?为此写个简 ...
- TechEmpower 13轮测试中的ASP.NET Core性能测试
应用性能直接影响到托管服务的成本,因此公司在开发应用时需要格外注意应用所使用的Web框架,初创公司尤其如此.此外,糟糕的应用性能也会影响到用户体验,甚至会因此受到相关搜索引擎的降级处罚.在选择框架时, ...
- .NET Core系列 :4 测试
2016.6.27 微软已经正式发布了.NET Core 1.0 RTM,但是工具链还是预览版,同样的大量的开源测试库也都是至少发布了Alpha测试版支持.NET Core, 这篇文章 The Sta ...
- 渗透测试工具BurpSuite做网站的安全测试(基础版)
渗透测试工具BurpSuite做网站的安全测试(基础版) 版权声明:本文为博主原创文章,未经博主允许不得转载. 学习网址: https://t0data.gitbooks.io/burpsuite/c ...
- 在ubuntu16.10 PHP测试连接MySQL中出现Call to undefined function: mysql_connect()
1.问题: 测试php7.0 链接mysql数据库的时候发生错误: Fatal error: Uncaught Error: Call to undefined function mysqli_con ...
- 【初学python】使用python调用monkey测试
目前公司主要开发安卓平台的APP,平时测试经常需要使用monkey测试,所以尝试了下用python调用monkey,代码如下: import os apk = {'j': 'com.***.test1 ...
随机推荐
- Java 添加数字签名到Excel以及检测、删除签名
Excel中可添加数字签名以供文档所有者申明文档的所有权或有效性.文本以Java代码示例介绍如何在Excel文档中对数字签名功能进行相关操作,包括如何添加签名到Excel.检测Excel文档是否已签名 ...
- 【Django笔记1】-视图(views)与模板(templates)
视图(views)与模板(templates) 1,视图(views) 将接收到的数据赋值给模板(渲染),再传递给浏览器.HTML代码可以直接放在views.py(文件名可任意更换),也可以放在t ...
- Python数据分析入门(六):Pandas的函数应用
apply和applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random.randn(5,4) - 1) p ...
- 带你全面认识CMMI V2.0(终)——实施落地
引入CMMI的方法 一共有四个阶段将您的业务过程和最佳实践最终融合在一起,并在该范围内重新创造整个组织的"完成方式".这四个阶段是: 战略探索:此阶段的重点是了解当前状态并计划过渡 ...
- mp4视频中插入文字
最近接到一个需求,需要往mp4中动态插入文字,并且mp4中的乌云能在文字上有飘动的效果,一开始想用canvas,但是由于本人经验不足,没什么思路,看到css3有一个属性:mix-blend-mode, ...
- VirtualBox CentOS8 调整分辨率
1 概述 VirtualBox安装完CentOS8后无法调节分辨率,需要安装额外的工具. 2 安装依赖包 首先确保虚拟机能正常连接网络,然后安装:kernel.kernel-core.kernel-m ...
- 16. Vue2.4+新增属性$attrs
vm.$attrs简介 首先我们来看下vue官方对vm.$attrs的介绍: 包含了父作用域中不作为 prop 被识别 (且获取) 的特性绑定 (class 和 style 除外).当一个组件没有声明 ...
- OO第二单元总结——电梯
在电梯系列的作业中,笔者的整体架构几乎没有发生改变.现介绍如下,对于一个电梯系统,主要的工作步骤就是获取乘客请求.分派请求.执行请求.针对这样的工作模式,笔者设计了Elevator.Uselist两个 ...
- 基于MATLAB的手写公式识别(转折)
2021-03-29 21:11:00 很难说自己是不是上当受骗了,老师明明说利用MATLAB进行手写体(记得是手写体,再不济印刷体)的识别是轻而易举的. 平时我也十分喜欢MATLAB这一操作系统,认 ...
- git基于master创建本地新分支
应用场景:开发过程中经常用到从master分支copy一个本地分支作为开发分支 步骤: 1.切换到被copy的分支(master),并且从远端拉取最新版本 $git checkout master $ ...