【爬虫】如何用python+selenium网页爬虫
一、前提
爬虫网页(只是演示,切勿频繁请求):https://www.kaola.com/
需要的知识:Python,selenium 库,PyQuery
参考网站:https://selenium-python-zh.readthedocs.io/en/latest/waits.html
二、简单的分析下网站
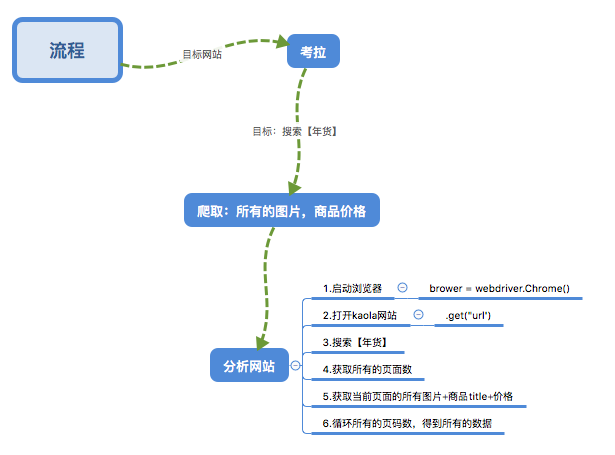
三、步骤
1.目标:
1.open brower
2.open url
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as py
brower = webdriver.Chrome() //定义一个brower ,声明webdriver,调用Chrome()方法
wait = WebDriverWait(brower,20) //设置一个全局等待时间
brower.get("https://www.kaola.com/")
2.搜索【年货】
def search():
try:
brower.get("https://www.kaola.com/")
//红包
close_windows = wait.until(
EC.presence_of_element_located((By.XPATH,'//div[@class="cntbox"]//div[@class="u-close"]'))
)
//输入框
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#topSearchInput'))
)
//搜索
submit = wait.until(
EC.presence_of_element_located((By.XPATH,'//*[@id="topSearchBtn"]'))
)
close_windows.click()
input.send_keys('年货') time.sleep(2) submit.click()
//获取年货所有的页数
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#resultwrap > div.splitPages > a:nth-child(11)'))
)
return total.text
except TimeoutException:
return 'error'
3.获取页面的信息
//使用pyQurey解析页面
def get_product():
wait.until(
EC.presence_of_element_located((By.XPATH,'//*[@id="result"]//li[@class="goods"]'))
)
html = brower.page_source
doc = py(html)
goods = doc('#result .goods .goodswrap')
for good in goods.items():
product = {
'image' : good.find('a').attr('href'),
'title':good.find('a').attr('title'),
'price':good.find('.price .cur').text()
}
print(product)
def main():
get_product()
brower.close
.....后续更新
【爬虫】如何用python+selenium网页爬虫的更多相关文章
- Python编写网页爬虫爬取oj上的代码信息
OJ升级,代码可能会丢失. 所以要事先备份. 一開始傻傻的复制粘贴, 后来实在不能忍, 得益于大潇的启示和聪神的原始代码, 网页爬虫走起! 已经有段时间没看Python, 这次网页爬虫的原始代码是 p ...
- Python动态网页爬虫-----动态网页真实地址破解原理
参考链接:Python动态网页爬虫-----动态网页真实地址破解原理
- Python 简单网页爬虫学习
#coding=utf-8 # 参考文章: # 1. python实现简单爬虫功能 # http://www.cnblogs.com/fnng/p/3576154.html # 2. Python 2 ...
- 【网络爬虫】【python】网络爬虫(五):scrapy爬虫初探——爬取网页及选择器
在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的. 一.爬虫类编写(spider.py) from scrapy.s ...
- 【网络爬虫】【python】网络爬虫(四):scrapy爬虫框架(架构、win/linux安装、文件结构)
scrapy框架的学习,目前个人觉得比较详尽的资料主要有两个: 1.官方教程文档.scrapy的github wiki: 2.一个很好的scrapy中文文档:http://scrapy-chs.rea ...
- Python静态网页爬虫相关知识
想要开发一个简单的Python爬虫案例,并在Python3以上的环境下运行,那么需要掌握哪些知识才能完成一个简单的Python爬虫呢? 爬虫的架构实现 爬虫包括调度器,管理器,解析器,下载器和输出器. ...
- Python学习---网页爬虫[下载图片]
爬虫学习--下载图片 1.主要用到了urllib和re库 2.利用urllib.urlopen()函数获得页面源代码 3.利用正则匹配图片类型,当然正则越准确,下载的越多 4.利用urllib.url ...
- Python简单网页爬虫——极客学院视频自动下载
http://blog.csdn.net/supercooly/article/details/51003921
- python静态网页爬虫之xpath(简单的博客更新提醒功能)
直接上代码: #!/usr/bin/env python3 #antuor:Alan #-*- coding: utf-8 -*- import requests from lxml import e ...
随机推荐
- HDFS(一) 高级特性
三个高级特性——快照.配额.回收站 一.快照(snapshot):是一种备份,默认关闭 1.应用场景: 防止用户错误操作 备份 试验/测试 灾难恢复 2.命令: 管理命令: -allowsnapsho ...
- 安装CaffeOnSpark过程中遇到的问题及解决方案
安装教程来自 http://blog.csdn.net/sadonmyown/article/details/72781393 首先,我使用的节点环境是ubuntu 16.04.1,事先 成功安装了s ...
- nopcommerce 4.1 core 学习 增加商城配置属性
需求: 原本是想用nop 来做国际版的商城,可以像亚马逊那样 国内外通用, 专门增加一个跨进元素属性. 学习里面的一些架构思想. 国内的行情还是 像himall 会比较实用. 这是在商城的综合 ...
- springboot-mybatis多数据源以及踩坑之旅
首先,springboot项目结构如下 springboot配置文件内容如下 动态数据源的配置类如下(必须保证能被ComponentScan扫描到): 1 package com.letzgo.con ...
- python笔记24-os模块
import osprint(os.getcwd())#取当前工作目录#os.chmod('/usr/local',7)#给文件目录加权限,7是最高权限print(os.chdir(r"e: ...
- Labview笔记-创建自定义控件
labview中的控件种类很多,但是样式或者外观有时不能满足我们的需求.如何制作一个好看酷酷的自定义控件呢? 以开关为例,我们先添加一个labview中自带的确定开关控件 之后右键该控件--高级--自 ...
- 在Linux系统使用VMware安装虚拟机
首先到VMware官网上www.vmware.com下载相应的版本 我这边用的是 VMware-Workstation-Full-12.5.0-4352439.x86_64.bundle 上传到Lin ...
- OpenStack源码分析 Neutron源码分析(一)-----------Restful API篇
原文:https://blog.csdn.net/happyanger6/article/details/54586463 首先,先分析WSGI应用的实现. 由前面的文章http://blog.csd ...
- JAVA 对接腾讯地图,经纬度转换
package com.lvjing.util; import net.sf.json.JSONArray; import net.sf.json.JSONObject; import org.spr ...
- 两个action之间进行跳转
名字 说明 Chain 用来处理Action链 Dispatcher 用来转向页面,通常处理JSP FreeMarker 处理FreeMarker模板 HttpHeader 用来控制特殊的Http行为 ...