【爬虫】如何用python+selenium网页爬虫
一、前提
爬虫网页(只是演示,切勿频繁请求):https://www.kaola.com/
需要的知识:Python,selenium 库,PyQuery
参考网站:https://selenium-python-zh.readthedocs.io/en/latest/waits.html
二、简单的分析下网站
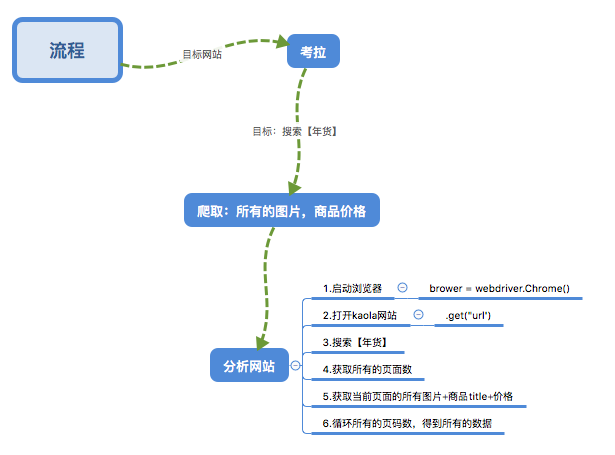
三、步骤
1.目标:
1.open brower
2.open url
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from pyquery import PyQuery as py
brower = webdriver.Chrome() //定义一个brower ,声明webdriver,调用Chrome()方法
wait = WebDriverWait(brower,20) //设置一个全局等待时间
brower.get("https://www.kaola.com/")
2.搜索【年货】
def search():
try:
brower.get("https://www.kaola.com/")
//红包
close_windows = wait.until(
EC.presence_of_element_located((By.XPATH,'//div[@class="cntbox"]//div[@class="u-close"]'))
)
//输入框
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#topSearchInput'))
)
//搜索
submit = wait.until(
EC.presence_of_element_located((By.XPATH,'//*[@id="topSearchBtn"]'))
)
close_windows.click()
input.send_keys('年货') time.sleep(2) submit.click()
//获取年货所有的页数
total = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#resultwrap > div.splitPages > a:nth-child(11)'))
)
return total.text
except TimeoutException:
return 'error'
3.获取页面的信息
//使用pyQurey解析页面
def get_product():
wait.until(
EC.presence_of_element_located((By.XPATH,'//*[@id="result"]//li[@class="goods"]'))
)
html = brower.page_source
doc = py(html)
goods = doc('#result .goods .goodswrap')
for good in goods.items():
product = {
'image' : good.find('a').attr('href'),
'title':good.find('a').attr('title'),
'price':good.find('.price .cur').text()
}
print(product)
def main():
get_product()
brower.close
.....后续更新
【爬虫】如何用python+selenium网页爬虫的更多相关文章
- Python编写网页爬虫爬取oj上的代码信息
OJ升级,代码可能会丢失. 所以要事先备份. 一開始傻傻的复制粘贴, 后来实在不能忍, 得益于大潇的启示和聪神的原始代码, 网页爬虫走起! 已经有段时间没看Python, 这次网页爬虫的原始代码是 p ...
- Python动态网页爬虫-----动态网页真实地址破解原理
参考链接:Python动态网页爬虫-----动态网页真实地址破解原理
- Python 简单网页爬虫学习
#coding=utf-8 # 参考文章: # 1. python实现简单爬虫功能 # http://www.cnblogs.com/fnng/p/3576154.html # 2. Python 2 ...
- 【网络爬虫】【python】网络爬虫(五):scrapy爬虫初探——爬取网页及选择器
在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的. 一.爬虫类编写(spider.py) from scrapy.s ...
- 【网络爬虫】【python】网络爬虫(四):scrapy爬虫框架(架构、win/linux安装、文件结构)
scrapy框架的学习,目前个人觉得比较详尽的资料主要有两个: 1.官方教程文档.scrapy的github wiki: 2.一个很好的scrapy中文文档:http://scrapy-chs.rea ...
- Python静态网页爬虫相关知识
想要开发一个简单的Python爬虫案例,并在Python3以上的环境下运行,那么需要掌握哪些知识才能完成一个简单的Python爬虫呢? 爬虫的架构实现 爬虫包括调度器,管理器,解析器,下载器和输出器. ...
- Python学习---网页爬虫[下载图片]
爬虫学习--下载图片 1.主要用到了urllib和re库 2.利用urllib.urlopen()函数获得页面源代码 3.利用正则匹配图片类型,当然正则越准确,下载的越多 4.利用urllib.url ...
- Python简单网页爬虫——极客学院视频自动下载
http://blog.csdn.net/supercooly/article/details/51003921
- python静态网页爬虫之xpath(简单的博客更新提醒功能)
直接上代码: #!/usr/bin/env python3 #antuor:Alan #-*- coding: utf-8 -*- import requests from lxml import e ...
随机推荐
- C语言:开平方根sqrt程序02
#include <stdio.h> int sqrt01(int x); void main(void){ int x=49,y; y=sqrt01(x); if(y<0) pri ...
- linux目录说明
/etc/passwd 用户信息文件 [root@web01 ~]# cat /etc/passwd root: x: : : root: /root: /bin/bash 可登录用户 bin: x ...
- JS---作用域和作用域链
JS---作用域和作用域链 作用域就是变量与函数的可访问范围,即作用域控制着变量与函数的可见性和生命周期.在JavaScript中,变量的作用域有全局作用域和局部作用域两种. //常犯的一个错误 &l ...
- wifi编辑 centos
ifconfig -a sudo iw dev 设置名称 scan
- Mvaen仓库文件添加阿里镜像
新手一枚,创建项目的时候下载Jar之类的特别慢,问过前辈才知道要去settings.xml里面增加一个阿里云服务.不添加这个的话是从国外的仓库下载,添加之后就能直接从国内下载了~ 步骤1:找到你的Ma ...
- sprindmvc
Spring Web MVC是一种基于Java的实现了Web MVC设计模式的请求驱动类型的轻量级Web框架,即使用了MVC架构模式的思想,将web层进行职责解耦,基于请求驱动指的就是使用请求-响应模 ...
- 安装oracle数据库的操作步骤
1. vnc启动之后,进入数据库安装包所在目录,此处是/home/DB/backup/database 2. 输入命令 ./runInstaller 3. 弹出linux图形化界面,同时弹出Oracl ...
- 自学python之路(day4)
一 购物车小程序 goods=[{}, {}, {}] shop_car={} li=[] ,len(goods)): li.append(i) money=input('请输入您的总金额:') if ...
- CNN
<卷积神经网络详述> <卷积神经网络——雨石博客> 学习参考:http://blog.csdn.net/stdcoutzyx/article/details/4159 ...
- vue 控制视图
<!--第一种:点击改变容器的值--> <li> <a href="javascript:void(0)" @click="state.bo ...