SQLServer之创建全文索引
创建全文索引的必须条件
必须具有全文目录,然后才能创建全文索引。 目录是包含一个或多个全文索引的虚拟容器。
使用SSMS数据库管理工具创建全文索引
1、连接数据库,选择数据库,选择数据表-》右键数据表-》选择全文索引-》选择定义全文索引。
2、在全文索引向导点击下一步。
3、在全文索引向导弹出框-》选择一个最小唯一索引-》点击下一步。

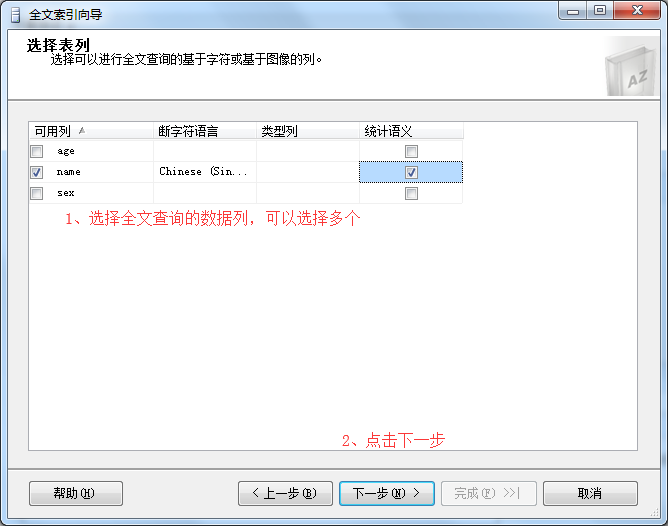
4、在全文索引向导弹出框-》选择全文检索数据列-》点击下一步。
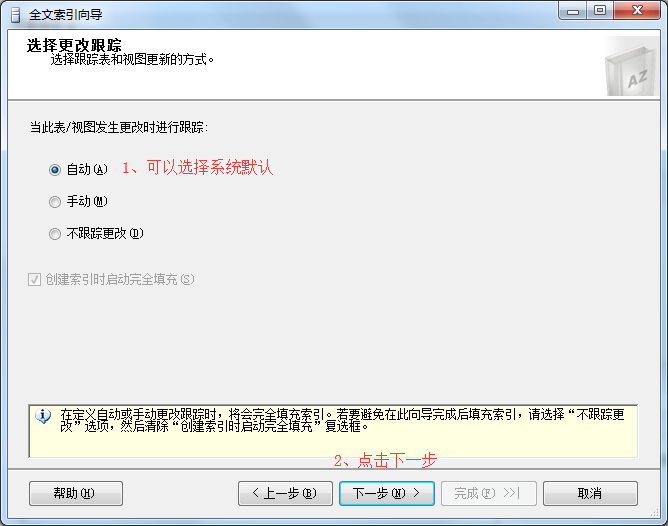
5、在全文索引向导弹出框-》选择表或者视图修改全文索引修改方式-》点击下一步。
6、在全文索引向导弹出框-》可以选择已有的全文索引目录或者自定义全文索引目录-》点击下一步。
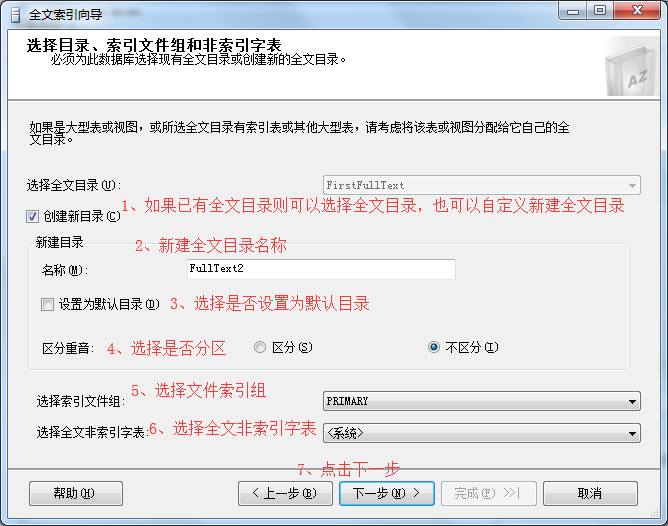
7、在全文索引向导弹出框-》选择填充计划,可以自定义填充计划-》点击下一步。
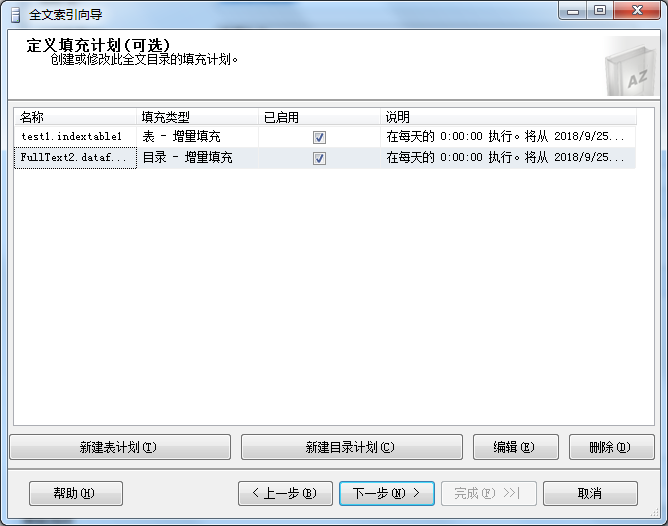
8、在全文索引向导弹出框-》点击完成。

使用T-SQL脚本创建全文索引
语法:
--声明数据库引用
use 数据库名;
go
--查看全文索引是否存在,如果存在则删除
if exists(select * from sys.fulltext_indexes)
drop fulltext index on 表名;
go
create
fulltext --创建全文索引
index
on 表名--包含全文索引中的一列或多列的表或索引视图的名称。
(
name1 --全文索引中包含的列的名称。 只能为 char、varchar、nchar、nvarchar、text、ntext、image、xml 或 varbinary 类型的列编制索引,以供全文搜索使用。
--[LANGUAGE language_term] --存储在 column_name 中的数据的语言。
--statistical_semantics, --创建作为统计语义索引一部分的附加关键短语和文档相似性索引。
name2
--[LANGUAGE language_term]
--statistical_semantics,
......
)
key index 唯一索引名称--table_name 的唯一键索引的名称。 KEY INDEX 必须是唯一的单键列,不可为 Null。 为全文唯一键选择最小的唯一键索引。 为获得最佳性能,建议全文键使用整数数据类型。
on 全文目录--用于全文索引的全文目录。 数据库中必须已存在该目录。 此子句为可选项。 如果未指定,则使用默认目录。 如果默认目录不存在, SQL Server 将返回错误。
with(
--CHANGE_TRACKING [ = ] { MANUAL | AUTO | OFF [ , NO POPULATION ] }
--指定是否由 SQL Server 将对全文索引所覆盖的表列所做的更改(更新、删除或插入)传播到全文索引。 通过 WRITETEXT 和 UPDATETEXT 所做的数据更改不会反映到全文索引中,也不能使用更改跟踪方法拾取。
--MANUAL
--指定必须通过调用 ALTER FULLTEXT INDEX … START UPDATE POPULATION Transact-SQL 语句(手动填充)。 您可以使用 SQL Server 代理来定期调用此 Transact-SQL 语句。
--AUTO
--指定当基表中的数据修改时,所跟踪的更改将会自动传播(自动填充)。 尽管是自动传播更改,但这些更改可能不会立即反映到全文索引中。 默认值为 AUTO。
--OFF [ , NO POPULATION]
--指定 SQL Server 不保留对索引数据的更改的列表。 如果未指定 NO POPULATION,则 SQL Server 创建索引后将对其进行完全填充。
--仅当 CHANGE_TRACKING 为 OFF 时,才能使用 NO POPULATION 选项。 如果指定了 NO POPULATION,则 SQL Server 在创建索引后不会对其进行填充。 仅当用户使用 START FULL POPULATION 或 START INCREMENTAL POPULATION 子句执行 ALTER FULLTEXT INDEX 命令之后,才会填充索引。
change_tracking={ MANUAL | AUTO | OFF [ , NO POPULATION ] },
--STOPLIST [ = ] { OFF | SYSTEM | stoplist_name }
--将全文非索引字表与索引关联起来。 不使用属于指定非索引字表的任何标记填充索引。 如果未指定 STOPLIST,则 SQL Server 会将系统全文非索引字表与索引关联起来。
--OFF
--指定没有与全文索引关联的非索引字表。
--SYSTEM
--指定应对此全文索引使用默认的全文系统 STOPLIST。
--stoplist_name
--指定要与全文索引关联的非索引字表的名称。
stoplist= { OFF | SYSTEM | stoplist_name },
--SEARCH PROPERTY LIST [ = ] property_list_name
--适用范围: SQL Server 2012 (11.x) 到 SQL Server 2017。
--将搜索属性列表与索引相关联。
--OFF
--指定不会将任何属性列表与全文索引相关联。
--property_list_name
--指定要与全文索引关联的搜索属性列表的名称。
search property list={ off | property_list_name },
)
go
示例:
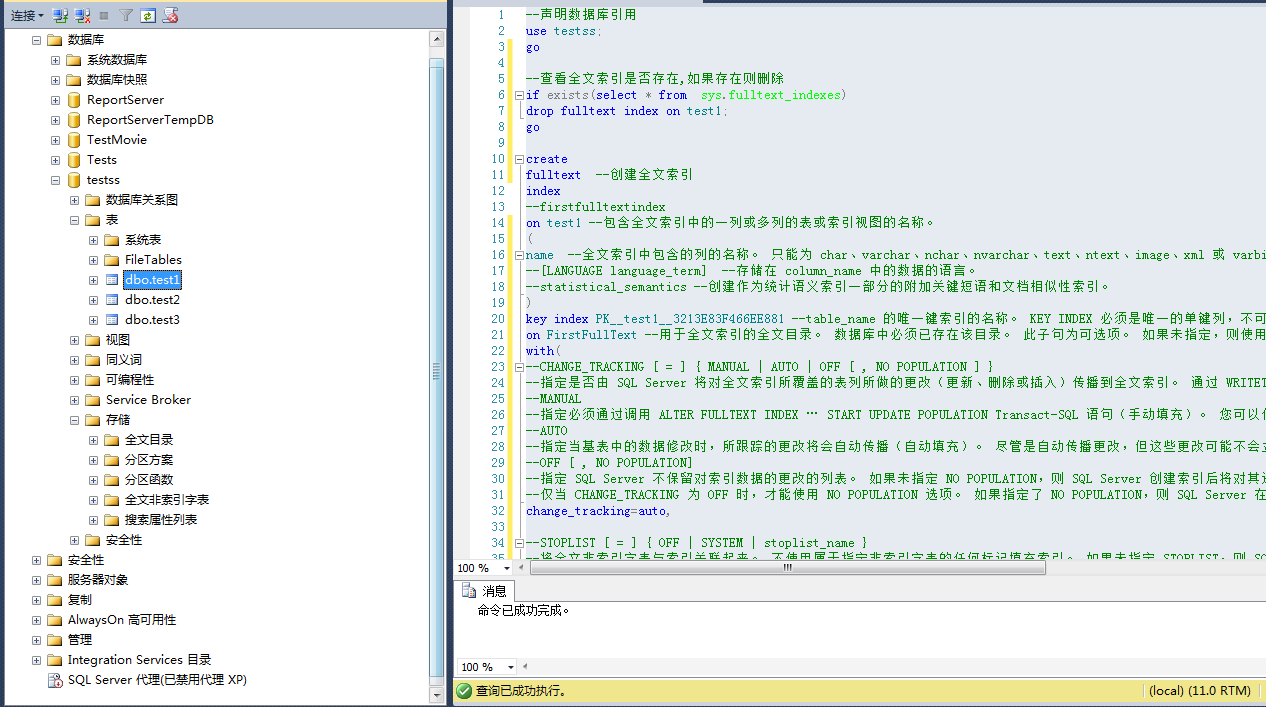
--声明数据库引用
use testss;
go
--查看全文索引是否存在,如果存在则删除
if exists(select * from sys.fulltext_indexes)
drop fulltext index on test1;
go
create
fulltext --创建全文索引
index
--firstfulltextindex
on test1 --包含全文索引中的一列或多列的表或索引视图的名称。
(
name --全文索引中包含的列的名称。 只能为 char、varchar、nchar、nvarchar、text、ntext、image、xml 或 varbinary 类型的列编制索引,以供全文搜索使用。
--[LANGUAGE language_term] --存储在 column_name 中的数据的语言。
--statistical_semantics --创建作为统计语义索引一部分的附加关键短语和文档相似性索引。
)
key index PK__test1__3213E83F466EE881 --table_name 的唯一键索引的名称。 KEY INDEX 必须是唯一的单键列,不可为 Null。 为全文唯一键选择最小的唯一键索引。 为获得最佳性能,建议全文键使用整数数据类型。
on FirstFullText --用于全文索引的全文目录。 数据库中必须已存在该目录。 此子句为可选项。 如果未指定,则使用默认目录。 如果默认目录不存在, SQL Server 将返回错误。
with(
--CHANGE_TRACKING [ = ] { MANUAL | AUTO | OFF [ , NO POPULATION ] }
--指定是否由 SQL Server 将对全文索引所覆盖的表列所做的更改(更新、删除或插入)传播到全文索引。 通过 WRITETEXT 和 UPDATETEXT 所做的数据更改不会反映到全文索引中,也不能使用更改跟踪方法拾取。
--MANUAL
--指定必须通过调用 ALTER FULLTEXT INDEX … START UPDATE POPULATION Transact-SQL 语句(手动填充)。 您可以使用 SQL Server 代理来定期调用此 Transact-SQL 语句。
--AUTO
--指定当基表中的数据修改时,所跟踪的更改将会自动传播(自动填充)。 尽管是自动传播更改,但这些更改可能不会立即反映到全文索引中。 默认值为 AUTO。
--OFF [ , NO POPULATION]
--指定 SQL Server 不保留对索引数据的更改的列表。 如果未指定 NO POPULATION,则 SQL Server 创建索引后将对其进行完全填充。
--仅当 CHANGE_TRACKING 为 OFF 时,才能使用 NO POPULATION 选项。 如果指定了 NO POPULATION,则 SQL Server 在创建索引后不会对其进行填充。 仅当用户使用 START FULL POPULATION 或 START INCREMENTAL POPULATION 子句执行 ALTER FULLTEXT INDEX 命令之后,才会填充索引。
change_tracking=auto,
--STOPLIST [ = ] { OFF | SYSTEM | stoplist_name }
--将全文非索引字表与索引关联起来。 不使用属于指定非索引字表的任何标记填充索引。 如果未指定 STOPLIST,则 SQL Server 会将系统全文非索引字表与索引关联起来。
--OFF
--指定没有与全文索引关联的非索引字表。
--SYSTEM
--指定应对此全文索引使用默认的全文系统 STOPLIST。
--stoplist_name
--指定要与全文索引关联的非索引字表的名称。
stoplist=system,
--SEARCH PROPERTY LIST [ = ] property_list_name
--适用范围: SQL Server 2012 (11.x) 到 SQL Server 2017。
--将搜索属性列表与索引相关联。
--OFF
--指定不会将任何属性列表与全文索引相关联。
--property_list_name
--指定要与全文索引关联的搜索属性列表的名称。
search property list=off
)
go
创建全文索引优缺点
优点:
1、全文索引可对char、varchar、nchar、nvarchar、text、ntext、image、xml、varbinary 或 varbinary(max) 类型字段进行检索,是解决海量数据模糊查询的好办法。
2、一个表只能建立一个全文索引(但可以对多个字段)。
3、与全文搜索不同,LIKE Transact-SQL 谓词仅对字符模式( char、varchar、nchar、nvarchar)有效。另外,不能使用 LIKE 谓词来查询格式化的二进制数据。此外,对大量非结构化的文本数据执行 LIKE 查询要比对相同数据执行同样的全文查询慢得多。对数百万行文本数据进行的 LIKE 查询可能需要几分钟的时间才能返回结果;而对于同样的数据,全文查询只需要几秒甚至更少的时间,具体取决于返回的行数及其大小。另一个考虑因素是 LIKE 仅对整个表执行简单模式扫描。相反,全文查询可识别语言,它在索引和查询时应用特定的转换,例如,筛选非索引字并进行同义词库和变形扩展。这些转换可帮助全文查询改进其撤回以及结果的最终排名
缺点:
1、全文索引导致磁盘资源的大量占用,全文索引本身就是一个利用磁盘空间换取性能的方法。全文索引大的原因是,按照某种语言来进行分词。
2、更新字段值,全文索引的索引不会自动更新,索引定期维护,以及表本身的维护操作使得这个表的管理成本大大的增加。
3、使用全文索引并不是对应用透明的。如果要想利用全文索引,必须修改查询语句。原有的查询语句是不可能利用全文索引的,需要改成全文索引规定的语法。全文索引不会影响到其他的SQL语句。
4、全文索引自身还有些缺陷。
SQLServer之创建全文索引的更多相关文章
- SqlServer中创建Oracle连接服务器
转自太祖元年的:http://www.cnblogs.com/jirglt/archive/2012/06/10/2544025.html参考:http://down.51cto.com/data/9 ...
- SQL Server 创建全文索引
背景知识: 全文目录是全文索引是容器.所以在创建全文索引前要有全文目录. 第一步: 创建全文目录: create fulltext catalog catalog_name [on filegroup ...
- MySQL创建全文索引
使用索引时数据库性能优化的必备技能之一.在MySql数据库中,有四种索引:聚焦索引(主键索引).普通索引.唯一索引以及我们这里将要介绍的全文索引(FUNLLTEXT INDEX). 全文索引(也称全文 ...
- SqlServer中创建Oracle链接服务器
SqlServer中创建Oracle链接服务器 第一种:界面操作 (1)展开服务器对象-->链接服务器-->右击“新建链接服务器” (2)输入链接服务器的IP (3)链接成功后 第二种:语 ...
- 【转载】Sqlserver在创建表的时候如何定义自增量Id
在Sqlserver创建表的过程中,有时候需要为表指定一个自增量Id,其实Sqlserver和Mysql等数据库都支持设置自增量Id字段,允许设置自增量Id的标识种子和标识自增量,标识种子代表初始自增 ...
- 【SqlServer】管理全文索引(FULL TEXT INDEX)
Sql Server中的全文索引(下面统一使用FULLTEXT INDEX来表示全文索引),是一种特定语言搜索索引功能.它和LIKE的不一样,LIKE主要是根据搜索模板搜索数据,它的效率比FULLTE ...
- 创建全文索引----SQLserver
1.启动 Microsoft Search 服务 开始菜单-->SQL程序组-->服务管理器-->下拉筐-->Microsoft Search 服务-->启动它. 2. ...
- sqlserver中创建链接服务器
链接服务器在跨数据库/跨服务器查询时非常有用(比如分布式数据库系统中),本文将以图文方式详细说明如何利用SQL Server Management Studio在图形界面下创建链接服务器. 1 ...
- SqlServer 在创建数据库时候指定的初始数据库大小是不能被收缩的
当你在SqlServer创建数据库的时候可以指定数据库文件的初始大小,比如下图中我们将新创建的数据库MyDB的大小设置成了1024MB 那么你建好的数据库的确也就会占用1024MB左右的磁盘空间 不过 ...
随机推荐
- 【Spark篇】---Spark中控制算子
一.前述 Spark中控制算子也是懒执行的,需要Action算子触发才能执行,主要是为了对数据进行缓存. 控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化 ...
- Vue轻松入门,一起学起来!
我们创建一个项目,这个项目我们细说Vue. 一.如何在项目中添加模块 我们通过npm 进行 安装 模块. 首先我们通过cmd.exe cd进入你的项目根目录,必须存在package.json文件,安装 ...
- C++ 断言
assert宏 (基本概念与用法整理) assert宏的深入学习 1.运行时断言 1.1.assert属于运行时断言,可以在运行时判断给定条件是否为真,如果为真则什么也不做,否则打印一跳错误信息,然后 ...
- C++版 - Leetcode 400. Nth Digit解题报告
leetcode 400. Nth Digit 在线提交网址: https://leetcode.com/problems/nth-digit/ Total Accepted: 4356 Total ...
- JsChart组件使用
JsChart是什么? JSChart能够在网页上生成图标,常用于统计信息,十分好用的一个JS组件. 使用JsChart 一.导入jscharts.js 二.编写jscharts.jsp测试页面 下载 ...
- Spring Boot 2.x (十二):Swagger2的正确玩儿法
Swagger2简介 简单的来说,Swagger2的诞生就是为了解决前后端开发人员进行交流的时候API文档难以维护的痛点,它可以和我们的Java程序完美的结合在一起,并且可以与我们的另一开发利器Spr ...
- 【CSS】按钮的禁用与可用 CSS Cursor 属性
禁用时的样式 可用时的样式 样式很简单,禁用就设置为灰色,可用就设置为红色,今天这个不是重点,重点的是,光标的样子 一般,禁用时候,光标移动到按钮的上方,光标如下 而在启用按钮的时候,光标移动到按钮上 ...
- Java 工厂模式(一)— 简单工厂模式
一.什么是工厂模式: Java中的工厂模式主要是用来将有大量共同接口的类实例化.工厂模式可以动态的决定将哪一个类实例化,不必事先知道要实例化哪个类,将类的实例化的主动权交给工厂而不是类本身.我们常见的 ...
- Spring Cloud Eureka 常用配置及说明
配置参数 默认值 说明 服务注册中心配置 Bean类:org.springframework.cloud.netflix.eureka.server.EurekaServerConfigBean eu ...
- JavaScript面试总结(一)
(一).call,apply,bind 的用法与区别? 答案:摘自:https://www.cnblogs.com/Jade-Liu18831/p/9580410.html(总结的特别棒的一篇文章) ...