MySQL MERGE存储引擎
写这篇文章,主要是因为面试的时候,面试官问我怎样统计所有的分表(假设按天分表)数据,我说了两种方案,第一种是最笨的方法,就是循环查询所有表数据(肯定不能采用);第二种方法是,利用中间件,每天定时把前一天的表数据查询出来存到mongodb,最后只查询mongodb。然后面试官问我还有没有比这个更好的方案,虽然没有给我解答,我回来自己在网上查询了一下,就是利用Merge存储引擎;
1.创建三张表,分别为user_1,user_2,user_3
CREATE TABLE `user_1` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MYISAM DEFAULT CHARSET=utf8mb4;
CREATE TABLE `user_2` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MYISAM DEFAULT CHARSET=utf8mb4;
CREATE TABLE `user_3` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MYISAM DEFAULT CHARSET=utf8mb4;
插入表数据
INSERT INTO user_1 (user_name,user_sex,user_birth_date) VALUES ('张1', '男', now());
INSERT INTO user_1 (user_name,user_sex,user_birth_date) VALUES ('张2', '男', now());
INSERT INTO user_1 (user_name,user_sex,user_birth_date) VALUES ('张3', '男', now());
INSERT INTO user_2 (user_name,user_sex,user_birth_date) VALUES ('王1', '女', now());
INSERT INTO user_2 (user_name,user_sex,user_birth_date) VALUES ('王2', '女', now());
INSERT INTO user_2 (user_name,user_sex,user_birth_date) VALUES ('王3', '女', now());
INSERT INTO user_3 (user_name,user_sex,user_birth_date) VALUES ('李1', '女', now());
INSERT INTO user_3 (user_name,user_sex,user_birth_date) VALUES ('李2', '女', now());
INSERT INTO user_3 (user_name,user_sex,user_birth_date) VALUES ('李3', '女', now());
2.创建merge表
CREATE TABLE `user_merge` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MERGE UNION = (user_1,user_2,user_3);
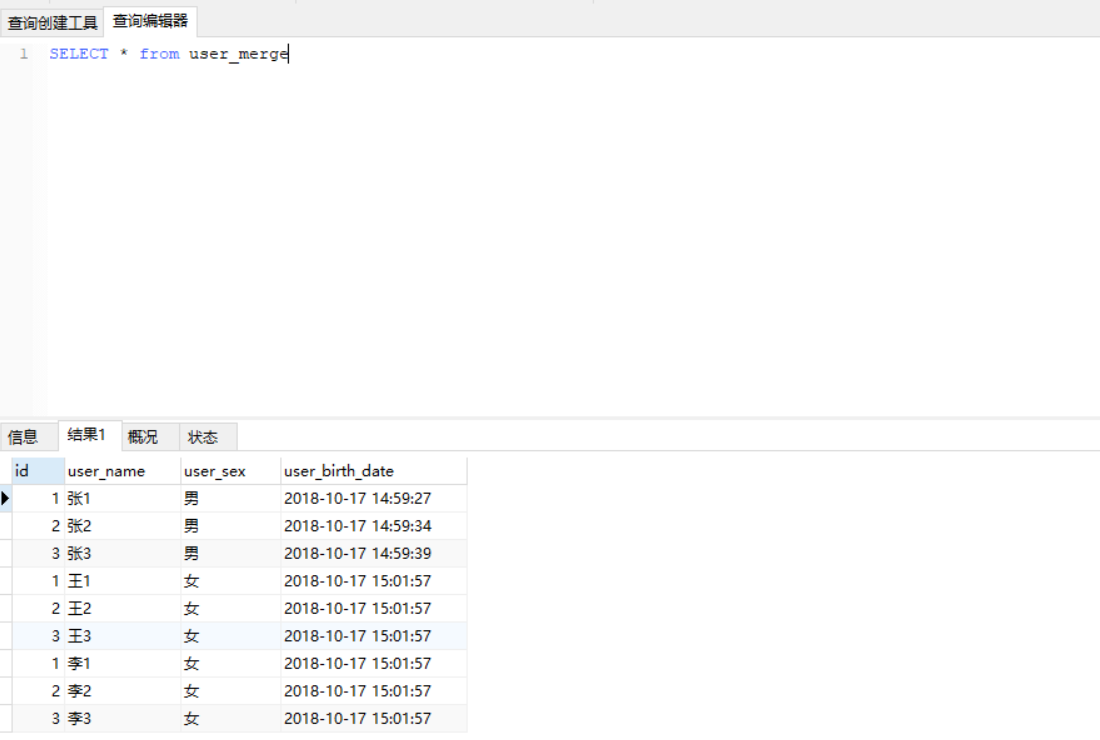
然后查询该表,select * from user_merge 结果如下
如果添加一张user_4表呢
CREATE TABLE `user_4` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MYISAM DEFAULT CHARSET=utf8mb4;
INSERT INTO user_4 (user_name,user_sex,user_birth_date) VALUES ('黄1', '女', now());
INSERT INTO user_4 (user_name,user_sex,user_birth_date) VALUES ('黄2', '女', now());
INSERT INTO user_4 (user_name,user_sex,user_birth_date) VALUES ('黄3', '女', now());
ALTER TABLE user_merge UNION = (user_1,user_2,user_3,user_4);
再次查询select * from user_merge 结果如下
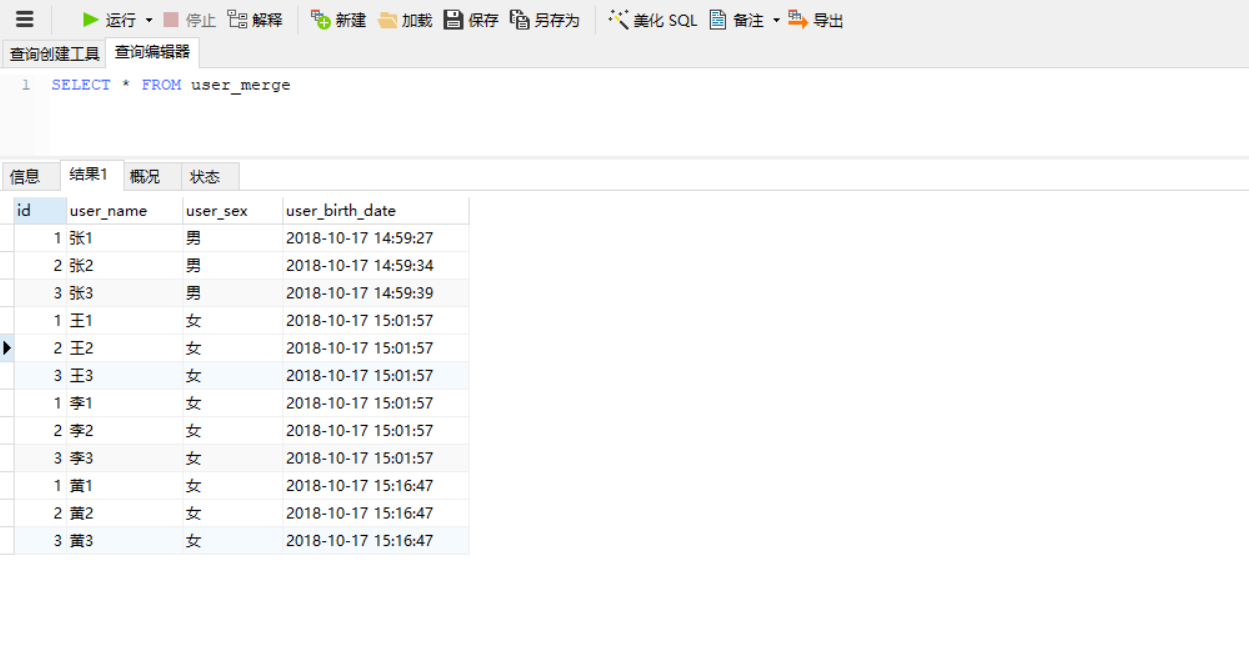
将4张表数据合并到一张表,然后我们只需查询user_merge表,即可得到我们想要的结果
注意:
1.MERGE存储引擎只能和MYISAM配合使用,也就是user_1,user_2,user_3,user_4必须指定ENGINE = MYISAM,否则查询user_merge会报错
2.user_merge表和分表字段必须完全一致
MySQL MERGE存储引擎的更多相关文章
- MySQL MERGE存储引擎 简介
MERGE存储引擎把一组MyISAM数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个MERGE数据表结构的各成员MyISAM数据表必须具有完全一样的结构.每一个成员数据表的数据列必 ...
- MySQL MERGE存储引擎 简介及用法
MERGE存储引擎把一组MyISAM数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个MERGE数据表结构的各成员MyISAM数据表必须具有完全一样的结构.每一个成员数据表的数据列必 ...
- Mysql的Merge存储引擎实现分表查询
对于数据量很大的一张表,i/o效率底下,分表势在必行! 使用程序分,对不同的查询,分配到不同的子表中,是个解决方案,但要改代码,对查询不透明. 好在mysql 有两个解决方案: Partition(分 ...
- 使用Merge存储引擎实现MySQL分表
一.使用场景 Merge表有点类似于视图.使用Merge存储引擎实现MySQL分表,这种方法比较适合那些没有事先考虑分表,随着数据的增多,已经出现了数据查询慢的情况. 这个时候如果要把已有的大数据量表 ...
- Mysql 之 MERGE 存储引擎
MERGE 存储引擎把一组 MyISAM 数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个 MERGE 数据表结构的各成员 MyISAM 数据表必须具有完全一样的表结构.每一个成员 ...
- 用Merge存储引擎中间件实现MySQL分表
觉得一个用Merge存储引擎中间件来实现MySQL分表的方法不错. 可以看下这个博客写的很清楚--> http://www.cnblogs.com/xbq8080/p/6628034.html ...
- [转帖]mysql常用存储引擎(InnoDB、MyISAM、MEMORY、MERGE、ARCHIVE)介绍与如何选择
mysql常用存储引擎(InnoDB.MyISAM.MEMORY.MERGE.ARCHIVE)介绍与如何选择原创web洋仔 发布于2018-06-28 15:58:34 阅读数 1063 收藏展开 h ...
- MySQL的存储引擎整理
01.MyISAM MySQL 5.0 以前的默认存储引擎.MyISAM 不支持事务.也不支持外键,其优势是访问的速度快,对事务完整性没有要求或者以SELECT.INSERT 为主的应用基本上都可以使 ...
- MySQL常用存储引擎
MySQL存储引擎主要有两大类: 1. 事务安全表:InnoDB.BDB. 2. 非事务安全表:MyISAM.MEMORY.MERGE.EXAMPLE.NDB Cluster.ARCHIVE.CSV. ...
随机推荐
- 论文笔记:Auto-ReID: Searching for a Part-aware ConvNet for Person Re-Identification
Auto-ReID: Searching for a Part-aware ConvNet for Person Re-Identification 2019-03-26 15:27:10 Paper ...
- springmvc定时任务
1.SpringMVC.xml文件加这个 <task:annotation-driven scheduler="qbScheduler"/> <task:sche ...
- Linux——高效玩转命令行
[0]统计文件or压缩文件的行数 zcat file.gz | sed -n '$=' #迅速.直接打印出多少行.-n 取消默认的输出,使用安静(silent)模式 '$=' 不知道是什么 ...
- 图解HTTP学习笔记
前言: 一直觉得自己在HTTP基础方面都是处于知其然,不知其所以然的样子.最近利用空闲时间拜读了一下图解HTTP,写篇博客记录一下读书笔记. TCP三次握手: ① 发送端首先发送一个带SYN标志的数据 ...
- Unity---在Hierarchy视图中将选中的对象的层级目录复制到剪切板
using UnityEditor; using UnityEngine; public class ObjPathCopyTool : ScriptableObject { [MenuItem(&q ...
- MySQL的随机数函数rand()的使用技巧
咱们学php的都知道,随机函数rand或mt_rand,可以传入一个参数,产生0到参数之间的随机整数,也可以传入两个参数,产生这两个参数之间的随机整数. 而在mysql里,随机数函数rand不能传参, ...
- samtools 使用简述
功能如下: 1.View 主要功能讲sam文件转位bam文件. 涉及的参数: -b 输出bam格式..默认是sam文件 -h 输出的sam文件带header..默认不带 -H 仅仅输出header - ...
- ajax得到后端数据一直提示为[object Object]解决方法
前段ajax <script type="text/javascript"> function requestJson() { $.ajax({ type : &quo ...
- Lab 11-2
Analyze the malware found in Lab11-02.dll. Assume that a suspicious file named Lab11-02.ini was also ...
- ElasticSearch改造研报查询实践
背景: 1,系统简介:通过人工解读研报然后获取并录入研报分类及摘要等信息,系统通过摘要等信息来获得该研报的URI 2,现有实现:老系统使用MSSQL存储摘要等信息,并将不同的关键字分解为不同字段来提供 ...