MySQL MERGE存储引擎
写这篇文章,主要是因为面试的时候,面试官问我怎样统计所有的分表(假设按天分表)数据,我说了两种方案,第一种是最笨的方法,就是循环查询所有表数据(肯定不能采用);第二种方法是,利用中间件,每天定时把前一天的表数据查询出来存到mongodb,最后只查询mongodb。然后面试官问我还有没有比这个更好的方案,虽然没有给我解答,我回来自己在网上查询了一下,就是利用Merge存储引擎;
1.创建三张表,分别为user_1,user_2,user_3
CREATE TABLE `user_1` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MYISAM DEFAULT CHARSET=utf8mb4;
CREATE TABLE `user_2` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MYISAM DEFAULT CHARSET=utf8mb4;
CREATE TABLE `user_3` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MYISAM DEFAULT CHARSET=utf8mb4;
插入表数据
INSERT INTO user_1 (user_name,user_sex,user_birth_date) VALUES ('张1', '男', now());
INSERT INTO user_1 (user_name,user_sex,user_birth_date) VALUES ('张2', '男', now());
INSERT INTO user_1 (user_name,user_sex,user_birth_date) VALUES ('张3', '男', now());
INSERT INTO user_2 (user_name,user_sex,user_birth_date) VALUES ('王1', '女', now());
INSERT INTO user_2 (user_name,user_sex,user_birth_date) VALUES ('王2', '女', now());
INSERT INTO user_2 (user_name,user_sex,user_birth_date) VALUES ('王3', '女', now());
INSERT INTO user_3 (user_name,user_sex,user_birth_date) VALUES ('李1', '女', now());
INSERT INTO user_3 (user_name,user_sex,user_birth_date) VALUES ('李2', '女', now());
INSERT INTO user_3 (user_name,user_sex,user_birth_date) VALUES ('李3', '女', now());
2.创建merge表
CREATE TABLE `user_merge` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MERGE UNION = (user_1,user_2,user_3);
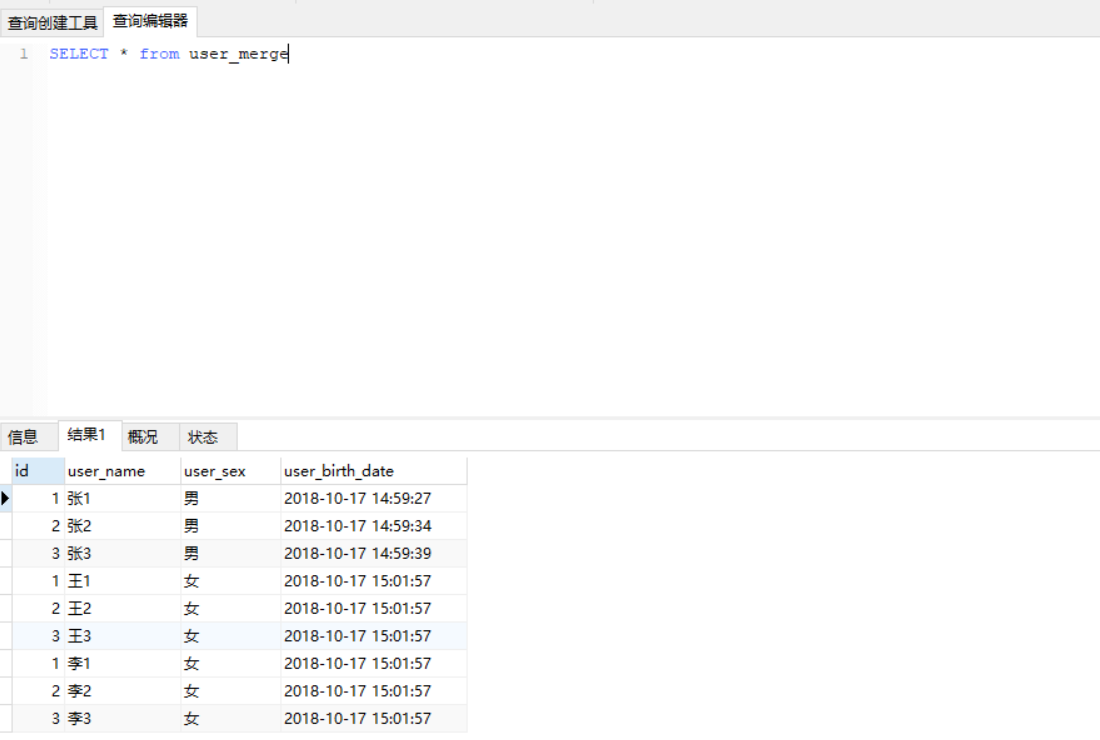
然后查询该表,select * from user_merge 结果如下
如果添加一张user_4表呢
CREATE TABLE `user_4` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`user_name` varchar(255) NULL ,
`user_sex` varchar(255) NULL ,
`user_birth_date` datetime NULL ,
PRIMARY KEY (`id`)
)ENGINE = MYISAM DEFAULT CHARSET=utf8mb4;
INSERT INTO user_4 (user_name,user_sex,user_birth_date) VALUES ('黄1', '女', now());
INSERT INTO user_4 (user_name,user_sex,user_birth_date) VALUES ('黄2', '女', now());
INSERT INTO user_4 (user_name,user_sex,user_birth_date) VALUES ('黄3', '女', now());
ALTER TABLE user_merge UNION = (user_1,user_2,user_3,user_4);
再次查询select * from user_merge 结果如下
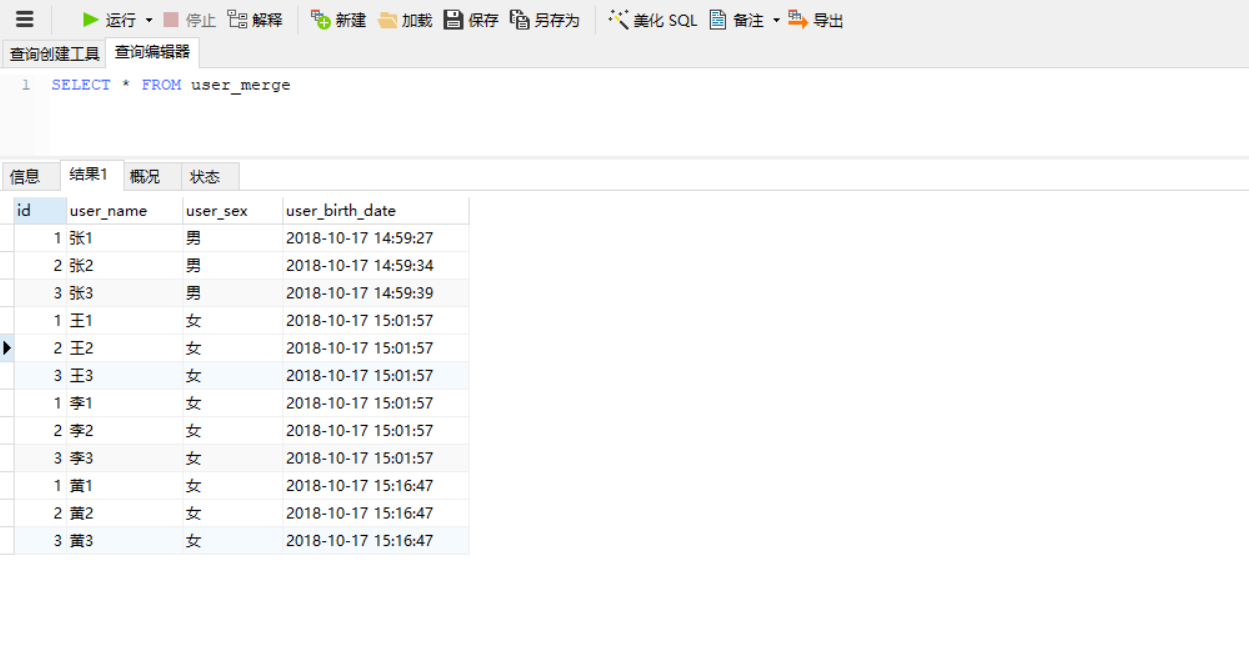
将4张表数据合并到一张表,然后我们只需查询user_merge表,即可得到我们想要的结果
注意:
1.MERGE存储引擎只能和MYISAM配合使用,也就是user_1,user_2,user_3,user_4必须指定ENGINE = MYISAM,否则查询user_merge会报错
2.user_merge表和分表字段必须完全一致
MySQL MERGE存储引擎的更多相关文章
- MySQL MERGE存储引擎 简介
MERGE存储引擎把一组MyISAM数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个MERGE数据表结构的各成员MyISAM数据表必须具有完全一样的结构.每一个成员数据表的数据列必 ...
- MySQL MERGE存储引擎 简介及用法
MERGE存储引擎把一组MyISAM数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个MERGE数据表结构的各成员MyISAM数据表必须具有完全一样的结构.每一个成员数据表的数据列必 ...
- Mysql的Merge存储引擎实现分表查询
对于数据量很大的一张表,i/o效率底下,分表势在必行! 使用程序分,对不同的查询,分配到不同的子表中,是个解决方案,但要改代码,对查询不透明. 好在mysql 有两个解决方案: Partition(分 ...
- 使用Merge存储引擎实现MySQL分表
一.使用场景 Merge表有点类似于视图.使用Merge存储引擎实现MySQL分表,这种方法比较适合那些没有事先考虑分表,随着数据的增多,已经出现了数据查询慢的情况. 这个时候如果要把已有的大数据量表 ...
- Mysql 之 MERGE 存储引擎
MERGE 存储引擎把一组 MyISAM 数据表当做一个逻辑单元来对待,让我们可以同时对他们进行查询.构成一个 MERGE 数据表结构的各成员 MyISAM 数据表必须具有完全一样的表结构.每一个成员 ...
- 用Merge存储引擎中间件实现MySQL分表
觉得一个用Merge存储引擎中间件来实现MySQL分表的方法不错. 可以看下这个博客写的很清楚--> http://www.cnblogs.com/xbq8080/p/6628034.html ...
- [转帖]mysql常用存储引擎(InnoDB、MyISAM、MEMORY、MERGE、ARCHIVE)介绍与如何选择
mysql常用存储引擎(InnoDB.MyISAM.MEMORY.MERGE.ARCHIVE)介绍与如何选择原创web洋仔 发布于2018-06-28 15:58:34 阅读数 1063 收藏展开 h ...
- MySQL的存储引擎整理
01.MyISAM MySQL 5.0 以前的默认存储引擎.MyISAM 不支持事务.也不支持外键,其优势是访问的速度快,对事务完整性没有要求或者以SELECT.INSERT 为主的应用基本上都可以使 ...
- MySQL常用存储引擎
MySQL存储引擎主要有两大类: 1. 事务安全表:InnoDB.BDB. 2. 非事务安全表:MyISAM.MEMORY.MERGE.EXAMPLE.NDB Cluster.ARCHIVE.CSV. ...
随机推荐
- xshell终端向远程服务器上传文件方法
centos-7下在本地终端里向远程服务器上传文件,在命令行中执行的软件. 安装命令如下: 在终端里输入如下命令: 会弹出如下窗口 选择你要上传的文件即可上传成功.
- SAP 跨公司销售业务
SAP 跨公司销售业务 http://blog.sina.com.cn/s/blog_95ac31e30102x5wh.html 分类: SAP_SD SAP 跨公司销售业务 一.业务简介 在由 ...
- 四、ConcurrentHashMap 锁分段机制
回顾: HashMap与Hashtable的底层都是哈希表,但是 HashMap:线程不安全 Hashtable:线程安全,但是效率非常低,且存在[复合操作](如"若存在则删除") ...
- 记一次IIS发布网站导致系统时常跳入登录页面的问题解决
服务器:winserver2012R2 iis 发布网站后,正常浏览网页,时常跳到登录页面,第一反应session过期,因为登录信息都存在session,但session 都是默认配置过期时间为20分 ...
- composer学习总结
composer 简介:是php用来管理依赖(dependency)关系的工具,工具包地址:https://packagist.org 下载地址:https://getcomposer.org/ 安 ...
- AT2412 最大の和
传送门 思路: 线段树暴力枚举区间,查询最大区间和. Code: #include<iostream> #include<cstdio> #include<algorit ...
- css3 calc()的用法
转载自:css3 calc()的用法 说明:calc(四则运算):任何长度值都可以使用calc()函数进行计算:和平时的加减乘除优先顺序一样一样的: 特别注意:calc()里面的运算符必须前后都留一个 ...
- C#中得到程序当前工作目录和执行目录的五种方法
string str="";str += "\r\n" + System.Diagnostics.Process.GetCurrentProcess().Mai ...
- Jquery封装的Ajax
$.get方法 语法: $.get(url,data,function(e){ //e就是服务器返回的数据 },dataType); 四个参数: url: 请求的服务器地址 data: 发送给服务器的 ...
- 『TensorFlow』专题汇总
TensorFlow:官方文档 TensorFlow:项目地址 本篇列出文章对于全零新手不太合适,可以尝试TensorFlow入门系列博客,搭配其他资料进行学习. Keras使用tf.Session训 ...