并发编程(九)—— Java 并发队列 BlockingQueue 实现之 LinkedBlockingQueue 源码分析
LinkedBlockingQueue
在看源码之前,通过查询API发现对LinkedBlockingQueue特点的简单介绍:
1、LinkedBlockingQueue是一个由链表实现的有界队列阻塞队列。
2、新元素插入到队列的尾部,队列获取操作则是从队列头部开始获得元素
3、大小默认值为Integer.MAX_VALUE,所以我们在使用LinkedBlockingQueue时建议手动传值,为其提供我们所需的大小,避免队列过大造成机器负载或者内存爆满等情况。
4、链接队列的吞吐量通常要高于基于数组的对列(ArrayBlockingQueue),但是在大多数并发应用程序中,其可预知的性能要低
源码剖析
通常情况下,我们建议创建指定大小的LinkedBlockingQueue阻塞队列。在正常情况下,链接队列的吞吐量要高于基于数组的队列(ArrayBlockingQueue),因为其内部实现添加和删除操作使用的两个ReenterLock来控制并发执行,而ArrayBlockingQueue内部只是使用一个ReenterLock控制并发,因此LinkedBlockingQueue的吞吐量要高于ArrayBlockingQueue。
其构造函数如下:
//默认大小为Integer.MAX_VALUE
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
} //创建指定大小为capacity的阻塞队列
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
我们先看看LinkedBlockingQueue的内部成员变量:
public class LinkedBlockingQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable { /**
* 节点类,用于存储数据
*/
static class Node<E> {
E item; /**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next; Node(E x) { item = x; }
} /** 阻塞队列的大小,默认为Integer.MAX_VALUE */
private final int capacity; /** 当前阻塞队列中的元素个数 */
private final AtomicInteger count = new AtomicInteger(); /**
* 阻塞队列的头结点
*/
transient Node<E> head; /**
* 阻塞队列的尾节点
*/
private transient Node<E> last; /** 获取并移除元素时使用的锁,如take, poll, etc */
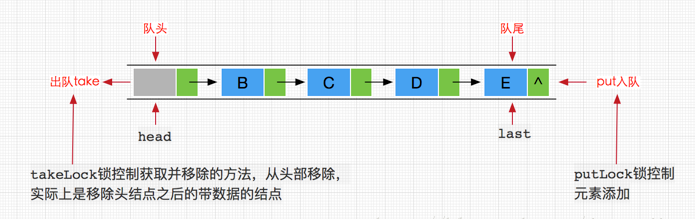
private final ReentrantLock takeLock = new ReentrantLock(); /** notEmpty条件对象,当队列没有数据时用于挂起执行删除的线程 */
private final Condition notEmpty = takeLock.newCondition(); /** 添加元素时使用的锁如 put, offer, etc */
private final ReentrantLock putLock = new ReentrantLock(); /** notFull条件对象,当队列数据已满时用于挂起执行添加的线程 */
private final Condition notFull = putLock.newCondition(); }
与ArrayBlockingQueue不同的是,LinkedBlockingQueue内部分别使用了takeLock 和 putLock 对并发进行控制,也就是说,添加和删除操作并不是互斥操作,可以同时进行,这样也就可以大大提高吞吐量。这里再次强调如果没有给LinkedBlockingQueue指定容量大小,其默认值将是Integer.MAX_VALUE,如果存在添加速度大于删除速度时候,有可能会内存溢出,这点在使用前希望慎重考虑。
这里用了两个锁,两个 Condition,简单介绍如下:
takeLock 和 notEmpty 怎么搭配:如果要获取(take)一个元素,需要获取 takeLock 锁,但是获取了锁还不够,如果队列此时为空,还需要队列不为空(notEmpty)这个条件(Condition)。
putLock 需要和 notFull 搭配:如果要插入(put)一个元素,需要获取 putLock 锁,但是获取了锁还不够,如果队列此时已满,还需要队列不是满的(notFull)这个条件(Condition)。
下面我们看看其其内部添加过程和删除过程是如何实现的。
添加方法的实现原理
对于添加方法,主要指的是add,offer以及put,这里先看看add方法和offer方法的实现
public boolean add(E e) {
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
从源码可以看出,add方法间接调用的是offer方法,如果add方法添加失败将抛出IllegalStateException异常,添加成功则返回true,那么下面我们直接看看offer的相关方法实现
public boolean offer(E e) {
//添加元素为null直接抛出异常
if (e == null) throw new NullPointerException();
//获取队列的个数
final AtomicInteger count = this.count;
//判断队列是否已满
if (count.get() == capacity)
return false;
int c = -1;
//构建节点
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
//此时可能有多个线程都在执行添加操作,抢占锁
//没有抢占到锁的线程会加入到putLock的阻塞队列,并且挂起
putLock.lock();
try {
//再次判断队列是否已满,考虑并发情况
if (count.get() < capacity) {
enqueue(node);//添加元素
c = count.getAndIncrement();//拿到当前未添加新元素时的队列长度
//如果容量还没满
if (c + 1 < capacity)
//此时会唤醒上面第15行处添加到putLock的阻塞队列的线程,被唤醒的线程满足条件后接着唤醒下一个,直到队列被添加满
notFull.signal();//唤醒下一个添加线程,执行添加操作
}
} finally {
putLock.unlock();
}
// 由于存在添加锁和消费锁,而消费锁和添加锁都会持续唤醒等到线程,因此count肯定会变化。
//这里的if条件表示如果队列中还有1条数据
if (c == 0)
signalNotEmpty();//如果还存在数据那么就唤醒消费锁
return c >= 0; // 添加成功返回true,否则返回false
}
//入队操作
private void enqueue(Node<E> node) {
//队列尾节点指向新的node节点
last = last.next = node;
}
//signalNotEmpty方法
private void signalNotEmpty() {
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
//唤醒获取并删除元素的线程
notEmpty.signal();
} finally {
takeLock.unlock();
}
}
这里的Offer()方法做了两件事,第一件事是判断队列是否满,满了就直接释放锁,没满就将节点封装成Node入队,然后再次判断队列添加完成后是否已满,不满就继续唤醒等到在条件对象notFull上的添加线程。第二件事是,判断是否需要唤醒等到在notEmpty条件对象上的消费线程。这里我们可能会有点疑惑,为什么添加完成后是继续唤醒在条件对象notFull上的添加线程而不是像ArrayBlockingQueue那样直接唤醒notEmpty条件对象上的消费线程?而又为什么要当if (c == 0)时才去唤醒消费线程呢?
唤醒添加线程的原因,在添加新元素完成后,会判断队列是否已满,不满就继续唤醒在条件对象notFull上的添加线程,这点与前面分析的ArrayBlockingQueue很不相同,在ArrayBlockingQueue内部完成添加操作后,会直接唤醒消费线程对元素进行获取,这是因为ArrayBlockingQueue只用了一个ReenterLock同时对添加线程和消费线程进行控制,这样如果在添加完成后再次唤醒添加线程的话,消费线程可能永远无法执行,而对于LinkedBlockingQueue来说就不一样了,其内部对添加线程和消费线程分别使用了各自的ReenterLock锁对并发进行控制,也就是说添加线程和消费线程是不会互斥的,所以添加锁只要管好自己的添加线程即可,添加线程自己直接唤醒自己的其他添加线程,如果没有等待的添加线程,直接结束了。如果有就直到队列元素已满才结束挂起,当然offer方法并不会挂起,而是直接结束,只有put方法才会当队列满时才执行挂起操作。注意消费线程的执行过程也是如此。这也是为什么LinkedBlockingQueue的吞吐量要相对大些的原因。
为什么要判断if (c == 0)时才去唤醒消费线程呢,这是因为消费线程一旦被唤醒是一直在消费的(前提是有数据),所以c值是一直在变化的,c值是添加完元素前队列的大小,此时c只可能是0或c>0,如果是c=0,那么说明之前消费线程已停止,条件对象上可能存在等待的消费线程,添加完数据后应该是c+1,那么有数据就直接唤醒等待消费线程,如果没有就结束啦,等待下一次的消费操作。如果c>0那么消费线程就不会被唤醒,只能等待下一个消费操作(poll、take、remove)的调用,那为什么不是条件c>0才去唤醒呢?我们要明白的是消费线程一旦被唤醒会和添加线程一样,一直不断唤醒其他消费线程,如果添加前c>0,那么很可能上一次调用的消费线程后,数据并没有被消费完,条件队列上也就不存在等待的消费线程了,还有可能,消费线程正在消费,消费队列中也有等待线程,但是消费线程消费完会自动唤醒下一个等待的消费线程,所以c>0唤醒消费线程得意义不是很大,当然如果添加线程一直添加元素,那么一直c>0,消费线程执行的换就要等待下一次调用消费操作了(poll、take、remove)。
我们来看看带超时的offer()
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
return offerLast(e, timeout, unit);
} public boolean offerLast(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
Node<E> node = new Node<E>(e);
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
//加入队列失败就进入while循环
while (!linkLast(node)) {
if (nanos <= 0)
//过了nano还没有入队成功,返回false
return false;
//如果没有被signal,就一直挂起nanos纳秒后醒来
nanos = notFull.awaitNanos(nanos);
}
//走到这里说明入队成功,返回true
return true;
} finally {
lock.unlock();
}
}
我们可以知道offer方法进行了阻塞超时处理,在 timeout 时间内没有入队成功,就一直阻塞,入队成功,返回false,超过 timeout 还没入队成功,返回false。
接下来我们看看put方法,它是一个阻塞添加的方法:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
// 如果队列满,等待 notFull 的条件满足。
while (count.get() == capacity) {
notFull.await();
}
// 入队
enqueue(node);
// count 原子加 1,c 还是加 1 前的值
c = count.getAndIncrement();
if (c + 1 < capacity)
notFull.signal();
} finally {
// 入队后,释放掉 putLock
putLock.unlock();
}
if (c == 0)
signalNotEmpty();
}
put 和 offer最大的区别是put方法是阻塞的,看offer 方法中的第6行,如果队列满了,则直接返回false;put方法的第10行,如果队列满了,则添加到 notFull 的等待队列中并挂起,其他的基本都一样。
移除方法的实现原理
我们先来看看poll()方法
public E poll() {
//获取当前队列的大小
final AtomicInteger count = this.count;
if (count.get() == 0)//如果没有元素直接返回null
return null;
E x = null;
int c = -1;
final ReentrantLock takeLock = this.takeLock;
takeLock.lock();
try {
//判断队列是否有数据
if (count.get() > 0) {
//如果有,直接删除并获取该元素值
x = dequeue();
//当前队列大小减一
c = count.getAndDecrement();
//如果队列未空,继续唤醒等待在条件对象notEmpty上的消费线程
if (c > 1)
notEmpty.signal();
}
} finally {
takeLock.unlock();
}
//判断c是否等于capacity,这是因为如果满说明NotFull条件对象上
//可能存在等待的添加线程
if (c == capacity)
signalNotFull();
return x;
}
private E dequeue() {
Node<E> h = head;//获取头结点
Node<E> first = h.next; 获取头结的下一个节点(要删除的节点)
h.next = h; // help GC//自己next指向自己,即被删除
head = first;//更新头结点
E x = first.item;//获取删除节点的值
first.item = null;//清空数据,因为first变成头结点是不能带数据的,这样也就删除队列的带数据的第一个节点
return x;
}
poll方法也比较简单,如果队列没有数据就返回null,如果队列有数据,那么就取出来,如果队列还有数据那么唤醒等待在条件对象notEmpty上的消费线程。然后判断if (c == capacity)为true就唤醒添加线程,这点与前面分析if(c==0)是一样的道理。因为只有可能队列满了,notFull条件对象上才可能存在等待的添加线程。
我们再看看take()方法
public E take() throws InterruptedException {
E x;
int c = -1;
//获取当前队列大小
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();//可中断
try {
//如果队列没有数据,挂机当前线程到条件对象的等待队列中
while (count.get() == 0) {
notEmpty.await();
}
//如果存在数据直接删除并返回该数据
x = dequeue();
c = count.getAndDecrement();//队列大小减1
if (c > 1)
notEmpty.signal();//还有数据就唤醒后续的消费线程
} finally {
takeLock.unlock();
}
//满足条件,唤醒条件对象上等待队列中的添加线程
if (c == capacity)
signalNotFull();
return x;
}
take方法是一个可阻塞可中断的移除方法,主要做了两件事,一是,如果队列没有数据就挂起当前线程到 notEmpty条件对象的等待队列中一直等待,如果有数据就删除节点并返回数据项,同时唤醒后续消费线程,二是尝试唤醒条件对象notFull上等待队列中的添加线程。 到此关于remove、poll、take的实现也分析完了,其中只有take方法具备阻塞功能。
LinkedBlockingQueue和ArrayBlockingQueue迥异
对于LinkedBlockingQueue和ArrayBlockingQueue的基本使用以及内部实现原理我们已较为熟悉了,这里我们就对它们两间的区别来个小结
1.队列大小有所不同,ArrayBlockingQueue是有界的初始化必须指定大小,而LinkedBlockingQueue可以是有界的也可以是无界的(Integer.MAX_VALUE),对于后者而言,当添加速度大于移除速度时,在无界的情况下,可能会造成内存溢出等问题。
2.数据存储容器不同,ArrayBlockingQueue采用的是数组作为数据存储容器,而LinkedBlockingQueue采用的则是以Node节点作为连接对象的链表。
3.由于ArrayBlockingQueue采用的是数组的存储容器,因此在插入或删除元素时不会产生或销毁任何额外的对象实例,而LinkedBlockingQueue则会生成一个额外的Node对象。这可能在长时间内需要高效并发地处理大批量数据的时,对于GC可能存在较大影响。
4.两者的实现队列添加或移除的锁不一样,ArrayBlockingQueue实现的队列中的锁是没有分离的,即添加操作和移除操作采用的同一个ReenterLock锁,而LinkedBlockingQueue实现的队列中的锁是分离的,其添加采用的是putLock,移除采用的则是takeLock,这样能大大提高队列的吞吐量,也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
并发编程(九)—— Java 并发队列 BlockingQueue 实现之 LinkedBlockingQueue 源码分析的更多相关文章
- 并发编程(八)—— Java 并发队列 BlockingQueue 实现之 ArrayBlockingQueue 源码分析
开篇先介绍下 BlockingQueue 这个接口的规则,后面再看其实现. 阻塞队列概要 阻塞队列与我们平常接触的普通队列(LinkedList或ArrayList等)的最大不同点,在于阻塞队列的阻塞 ...
- 并发编程(十)—— Java 并发队列 BlockingQueue 实现之 SynchronousQueue源码分析
BlockingQueue 实现之 SynchronousQueue SynchronousQueue是一个没有数据缓冲的BlockingQueue,生产者线程对其的插入操作put必须等待消费者的移除 ...
- Java核心复习——J.U.C LinkedBlockingQueue源码分析
参考文档 LinkedBlockingQueue和ArrayBlockingQueue的异同
- 消息队列的一些场景及源码分析,RocketMQ使用相关问题及性能优化
前文目录链接参考: 消息队列的一些场景及源码分析,RocketMQ使用相关问题及性能优化 https://www.cnblogs.com/yizhiamumu/p/16694126.html 消息队列 ...
- java中的==、equals()、hashCode()源码分析(转载)
在java编程或者面试中经常会遇到 == .equals()的比较.自己看了看源码,结合实际的编程总结一下. 1. == java中的==是比较两个对象在JVM中的地址.比较好理解.看下面的代码: ...
- Java的三种代理模式&完整源码分析
Java的三种代理模式&完整源码分析 参考资料: 博客园-Java的三种代理模式 简书-JDK动态代理-超详细源码分析 [博客园-WeakCache缓存的实现机制](https://www.c ...
- java 日志体系(四)log4j 源码分析
java 日志体系(四)log4j 源码分析 logback.log4j2.jul 都是在 log4j 的基础上扩展的,其实现的逻辑都差不多,下面以 log4j 为例剖析一下日志框架的基本组件. 一. ...
- Java SPI机制实战详解及源码分析
背景介绍 提起SPI机制,可能很多人不太熟悉,它是由JDK直接提供的,全称为:Service Provider Interface.而在平时的使用过程中也很少遇到,但如果你阅读一些框架的源码时,会发现 ...
- 【并发编程】Java并发编程传送门
本博客系列是学习并发编程过程中的记录总结.由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅. [并发编程系列博客传送门](https://www.cnblogs.com/54 ...
随机推荐
- 研究比对搞定博客 canvas-nest.js
经过比对网站源码,发现大的差异,复制代码添加成功. 参考:https://www.cnblogs.com/kexing/p/7264767.html 申请js权限 编辑 具体编辑请自行实验, 附上 ...
- Python + Anaconda + vscode环境重装(2019.4.20)
目录 卸载程序 安装Ananconda 检查系统环境变量 更换国内镜像源 设置VS CODE 用户配置及工作环境配置 @(Python + Anaconda + vscode环境重装) 工程目录的使用 ...
- 什么是HTTP及RFC
HTTP:超文本传输协议(HyperText Transfer Protocol),是互联网上应用最为广泛的一种网络协议. 所有的www文件都必须遵守这个标准.设计HTTP最初的目的是为了提供发布 ...
- 使用vue-awesome-swiper的相关问题
最近自己在仿做一个旅游网站的vue项目,在首页中使用了vue-awesome-swiper插件来实现轮播图的效果,发现了以下几种问题: 一.需要额外引入swiper.css 原来使用vue-aweso ...
- PBRT笔记(9)——贴图
采样与抗锯齿 当高分辨率贴图被缩小时,贴图会出现严重的混淆现象.虽然第7章中的非均匀采样技术可以减少这种混叠的视觉影响,但是更好的解决方案是实现基于分辨率进行采样的纹理函数. 可以在使用贴图时先对贴图 ...
- BZOJ4668: 冷战 [并查集 按秩合并]
BZOJ4668: 冷战 题意: 给定 n 个点的图.动态的往图中加边,并且询问某两个点最早什 么时候联通,强制在线. 还可以这样乱搞 并查集按秩合并的好处: 深度不会超过\(O(\log n)\) ...
- Unity3D 代码入口
最近有人提出一个unity一键导出html项目的设想,所以又回头看了一下unity 发现现在的untiy和我熟悉的有很大的不同了 在看unity的 entity 系统时,注意到,这个系统的入口比较特殊 ...
- 2018-2019-2 网络对抗技术 20162329 Exp6 信息搜集与漏洞扫描
目录 Exp6 信息搜集与漏洞扫描 一.实践原理 1. 间接收集 2. 直接收集 3. 社会工程学 二.间接收集 1. Zoomeye 2. FOFA 3. GHDB 4. whois 5. dig ...
- Hive中的Order by与关系型数据库中的order by语句的异同点
在Hive中,ORDER BY语句是对查询结果集进行整体的排序,最终将会产生一个reducer进行全局的排序,达到的最终结果是和传统的关系型数据库是一样的. 在数据量非常大的时候,全局排序的单个red ...
- javascript 变量的引入、变量的声明、变量的初始化
变量的引入及声明和初始化: 变量: 操作的数据都是在内存中操作 Js中存储数据使用变量的方式(名称,值--->数据) Js中声明变量都用var--->存储数据,数据应该有对应的数据类型 存 ...