Lucene 06 - 使用Lucene的Query API查询数据
Lucene是使用Query对象执行查询的, 由Query对象生成查询的语法. 如bookName:java, 表示搜索bookName域中包含java的文档数据.
1 Query对象的创建(方式一): 使用子类对象
1.1 常用的Query子类对象
| 子类对象 | 说明 |
|---|---|
| TermQuery | 不使用分析器, 对关键词做精确匹配搜索. 如:订单编号、身份证号 |
| NumericRangeQuery | 数字范围查询, 比如: 图书价格大于80, 小于100 |
| BooleanQuery | 布尔查询, 实现组合条件查询. 组合关系有: 1. MUST与MUST: 表示“与”, 即“交集” 2. MUST与MUST NOT: 包含前者, 排除后者 3. MUST NOT与MUST NOT: 没有意义 4. SHOULD与MUST: 表示MUST, SHOULD失去意义 5. SHOULD与MUST NOT: 等于MUST与MUST NOT 6. SHOULD与SHOULD表示“或”, 即“并集” |
1.2 常用的Query子类对象使用
1.2.1 使用TermQuery
(1) 需求: 查询图书名称中包含java的图书.
/**
* 搜索索引(封装搜索方法)
*/
private void seracher(Query query) throws Exception {
// 打印查询语法
System.out.println("查询语法: " + query);
// 1.创建索引库目录位置对象(Directory), 指定索引库的位置
Directory directory = FSDirectory.open(new File("/Users/healchow/Documents/index"));
// 2.创建索引读取对象(IndexReader), 用于读取索引
IndexReader reader = DirectoryReader.open(directory);
// 3.创建索引搜索对象(IndexSearcher), 用于执行搜索
IndexSearcher searcher = new IndexSearcher(reader);
// 4. 使用IndexSearcher对象执行搜索, 返回搜索结果集TopDocs
// 参数一:使用的查询对象, 参数二:指定要返回的搜索结果排序后的前n个
TopDocs topDocs = searcher.search(query, 10);
// 5. 处理结果集
// 5.1 打印实际查询到的结果数量
System.out.println("实际查询到的结果数量: " + topDocs.totalHits);
// 5.2 获取搜索的结果数组
// ScoreDoc中有文档的id及其评分
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for (ScoreDoc scoreDoc : scoreDocs) {
System.out.println("= = = = = = = = = = = = = = = = = = =");
// 获取文档的id和评分
int docId = scoreDoc.doc;
float score = scoreDoc.score;
System.out.println("文档id= " + docId + " , 评分= " + score);
// 根据文档Id, 查询文档数据 -- 相当于关系数据库中根据主键Id查询数据
Document doc = searcher.doc(docId);
System.out.println("图书Id: " + doc.get("bookId"));
System.out.println("图书名称: " + doc.get("bookName"));
System.out.println("图书价格: " + doc.get("bookPrice"));
System.out.println("图书图片: " + doc.get("bookPic"));
System.out.println("图书描述: " + doc.get("bookDesc"));
}
// 6. 关闭资源
reader.close();
}
(2) 测试使用TermQuery:
/**
* 测试使用TermQuery: 需求: 查询图书名称中包含java的图书
*/
@Test
public void testTermQuery() throws Exception {
//1. 创建TermQuery对象
TermQuery termQuery = new TermQuery(new Term("bookName", "java"));
// 2.执行搜索
this.seracher(termQuery);
}
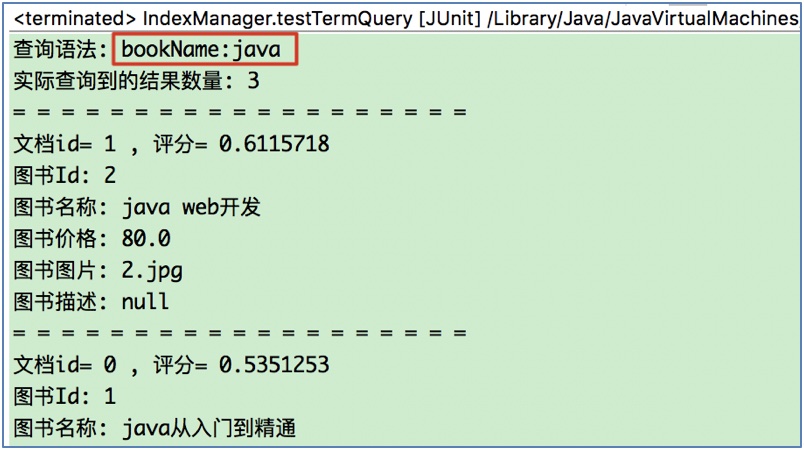
1.2.2 使用NumericRangeQuery
(1) 需求: 查询图书价格在80-100之间的图书(不包含80和100):
/**
* 测试使用NumericRangeQuery: 需求: 查询图书价格在80-100之间的图书
*/
@Test
public void testNumericRangeQuery() throws Exception{
// 1.创建NumericRangeQuery对象, 参数说明:
// field: 搜索的域; min: 范围最小值; max: 范围最大值
// minInclusive: 是否包含最小值(左边界); maxInclusive: 是否包含最大值(右边界)
NumericRangeQuery numQuery = NumericRangeQuery.newFloatRange("bookPrice", 80f, 100f, false, false);
// 2.执行搜索
this.seracher(numQuery);
}
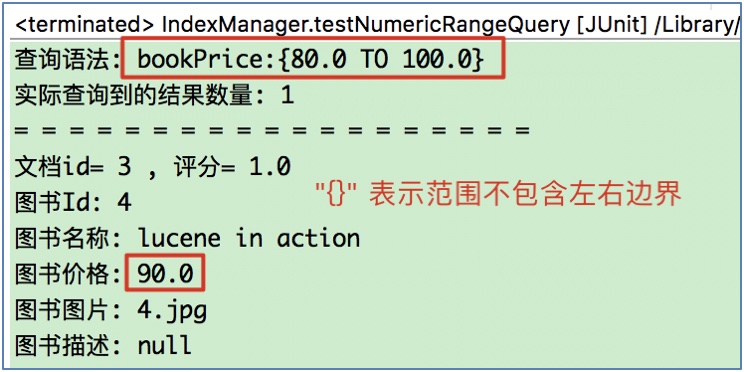
(2) 测试包含80和100:
// 测试包含80和100
NumericRangeQuery numQuery = NumericRangeQuery.newFloatRange("bookPrice", 80f, 100f, true, true);
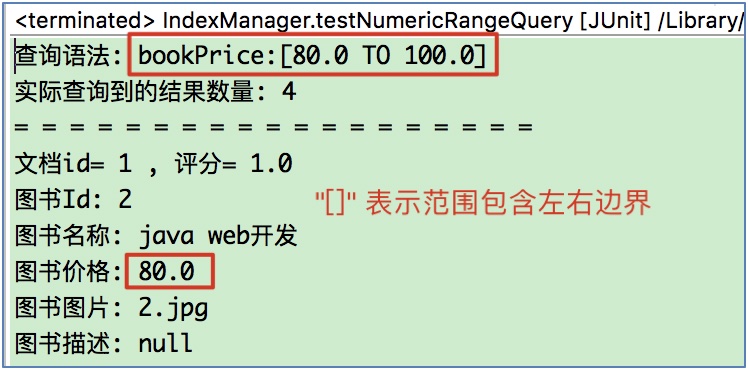
1.2.3 使用BooleanQuery
- 需求: 查询图书名称中包含Lucene, 并且价格在80-100之间的图书.
/**
* 测试使用BooleanQuery: 需求: 查询图书名称中包含Lucene, 且价格在80-100之间的图书
*/
@Test
public void testBooleanQuery() throws Exception {
// 1.创建查询条件
// 1.1.创建查询条件一
TermQuery query1 = new TermQuery(new Term("bookName", "lucene"));
// 1.2.创建查询条件二
NumericRangeQuery query2 = NumericRangeQuery.newFloatRange("bookPrice", 80f, 100f, true, true);
// 2.创建组合查询条件
BooleanQuery bq = new BooleanQuery();
// add方法: 添加组合的查询条件
// query参数: 查询条件对象
// occur参数: 组合条件
bq.add(query1, Occur.MUST);
bq.add(query2, Occur.MUST);
// 3.执行搜索
this.seracher(bq);
}
查询语法中, "+"表示并且条件, "-"表示不包含后面的条件:
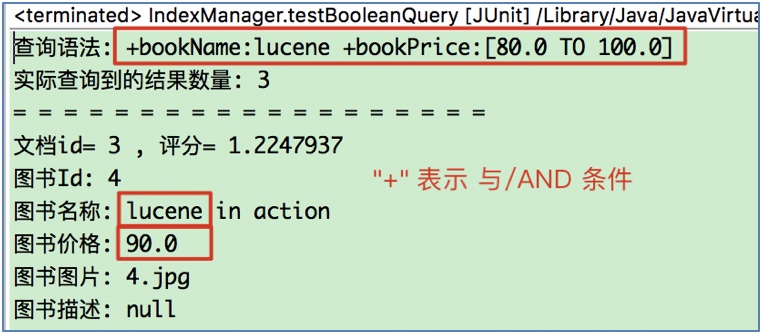
2 Query对象的创建(方式二): 使用QueryParser
说明: 使用QueryParser对象解析查询表达式, 实例化Query对象.
2.1 QueryParse表达式语法
(1) 关键词基本查询: 域名+":"+关键词, 比如: bookname:lucene
(2) 范围查询: 域名+":"+[最小值 TO 最大值], 比如: price:[80 TO 100].
**需要注意的是: QueryParser不支持数字范围查询, 仅适用于字符串范围查询. 如果有数字范围查询需求, 请使用NumericRangeQuery. **
(3) 组合查询:
| 条件表示符 | 符号说明 | 符号表示 |
|---|---|---|
| Occur.MUST | 搜索条件必须满足, 相当于AND | + |
| Occur.SHOULD | 搜索条件可选, 相当于OR | 空格 |
| Occur.MUST_NOT | 搜索条件不能满足, 相当于NOT非 | - |
2.2 使用QueryParser
需求: 查询图书名称中包含java, 并且图书名称中包含"Lucene"的图书.
/**
* 测试使用QueryParser: 需求: 查询图书名称中包含Lucene, 且包含java的图书
*/
@Test
public void testQueryParser() throws Exception {
// 1.创建查询对象
// 1.1.创建分析器对象
Analyzer analyzer = new IKAnalyzer();
// 1.2.创建查询解析器对象
QueryParser qp = new QueryParser("bookName", analyzer);
// 1.3.使用QueryParser解析查询表达式
Query query = qp.parse("bookName:java AND bookName:lucene");
// 2.执行搜索
this.seracher(query);
}
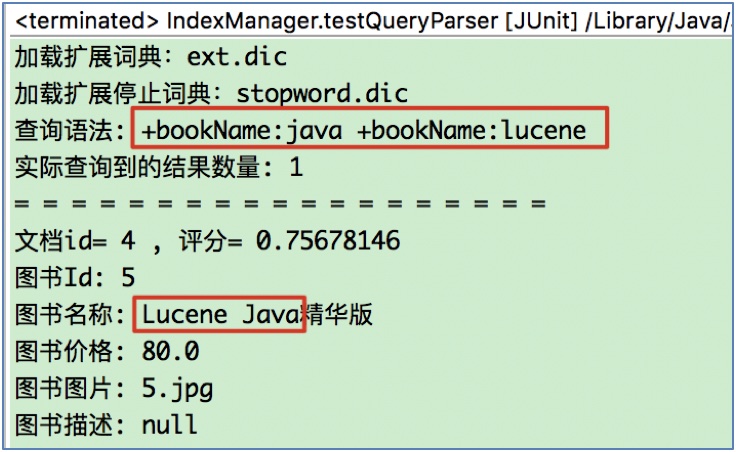
注意: 使用QueryParser, 表达式中的组合关键字AND/OR/NOT必须要大写. 设置了默认搜索域后, 若查询的域没有改变, 则可不写.
版权声明
作者: 马瘦风
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但请保留此段声明, 并在文章页面明显位置给出原文链接, 否则博主保留追究相关人员法律责任的权利.
Lucene 06 - 使用Lucene的Query API查询数据的更多相关文章
- Studio 3T 如何使用 Query Builder 查询数据
Studio 3T 是一款对 MongoDB 进行数据操作的可视化工具. 在 Studio 3T 中,我们可以借助 Query Builder 的 Drag & Drop 来构建查询条件. 具 ...
- Yii2 数据操作Query Builder查询数据
Query Builder $rows = (new \yii\db\Query()) ->select(['dyn_id', 'dyn_name']) ->from('zs_dynast ...
- 使用Dynamics 365 CE Web API查询数据加点料及选项集字段常用查询
微软动态CRM专家罗勇 ,回复336或者20190516可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me. 紧接上文:配置Postman通过OAuth 2 implicit ...
- elasticsearch6.7 05. Document APIs(5)Delete By Query API
4.Delete By Query API _delete_by_query API可以删除某个匹配条件的文档: POST twitter/_delete_by_query { "query ...
- lucene查询索引之Query子类查询——(七)
0.文档名字:(根据名字索引查询文档)
- Lucene核心--构建Lucene搜索(上篇,理论篇)
2.1构建Lucene搜索 2.1.1 Lucene内容模型 一个文档(document)就是Lucene建立索引和搜索的原子单元,它由一个或者多个字段(field)组成,字段才是Lucene的真实内 ...
- Elasticsearch学习笔记-Delete By Query API
记录关于Elasticsearch的文档删除API的学习 首先官网上Document APIs介绍了 Delete API 和Delete By Query API. Delete API可以通过指定 ...
- Elasticsearch Span Query跨度查询
ES基于Lucene开发,因此也继承了Lucene的一些多样化的查询,比如本篇说的Span Query跨度查询,就是基于Lucene中的SpanTermQuery以及其他的Query封装出的DSL,接 ...
- Lucene系列二:Lucene(Lucene介绍、Lucene架构、Lucene集成)
一.Lucene介绍 1. Lucene简介 最受欢迎的java开源全文搜索引擎开发工具包.提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言).Lucene的目的是为软件开发人 ...
随机推荐
- Scrapy:Python实现scrapy框架爬虫两个网址下载网页内容信息——Jason niu
import scrapy class DmozSpider(scrapy.Spider): name ="dmoz" allowed_domains = ["dmoz. ...
- angularjs和jquery前端发送以http请求formdata数据
formdata是比较常见的前端发送给后端的请求,不仅可以上传数据,而且同时可以上传文件. jquery使用http请求上传formdata数据的方法: var formdata = new Form ...
- 勾勾街:用最小的成本封装一个苹果IOS APP! 封装技术再度升级~
勾勾街自上线以来,“遭到”大量群众的喜爱... 只能用遭到这个词儿,因为大家好像都被憋了很久了,哈哈哈! 我们的技术是先进的,也是首创的,但最近发现了另一个网站,把我们的技术抄走了.... 本来这个事 ...
- 菜鸟安卓学习路——更强大的滚动控件--RecycleView
- C++入门笔记(一)零碎基础知识
零碎基础知识 一.创建和运行程序 1.使用文本编辑器编写程序,保存为文件,该文件就叫源代码. 2.编译源代码:运行一个程序,将源代码翻译为主机使用的内部语言----机器语言.包含了 编译后程序的文件就 ...
- golang struct 和 byte互转
相比于encoding, 使用unsafe性能更高 type MyStruct struct { A int B int } var sizeOfMyStruct = int(unsafe.Sizeo ...
- linux仅修改文件夹权限 分别批量修改文件和文件夹权限
比如我想把/var/www/html下的文件全部改成664,文件夹改成775,怎么做呢 方法一: 先把所有文件及文件夹改成664,然后把所有文件夹改成775 chmod -R 664 ./ find ...
- zookeeper使用和原理探究
转:http://www.blogjava.net/BucketLi/archive/2010/12/21/341268.html zookeeper介绍 zookeeper是一个为分布式应用提供一致 ...
- wait event & wake up
在linux驱动中一个常用的场景, 驱动需要等待中断的响应, 才得以执行后续的代码,达到一个原子操作的目的 /* 静态申请队列 */ static DECLARE_WAIT_QUEUE_HEAD(s_ ...
- vue - 新建一个项目
首先: 要先安装node 及 npm Node.js官方安装包及源码下载地址:http://nodejs.org/ 双击安装,在安装界面一直Next 直到Finish完成安装. 打开控制命令行程序(C ...