selenium、UA池、ip池、scrapy-redis的综合应用案例
案例:
网易新闻的爬取:
爬取的内容为一下4大板块中的新闻内容

爬取:
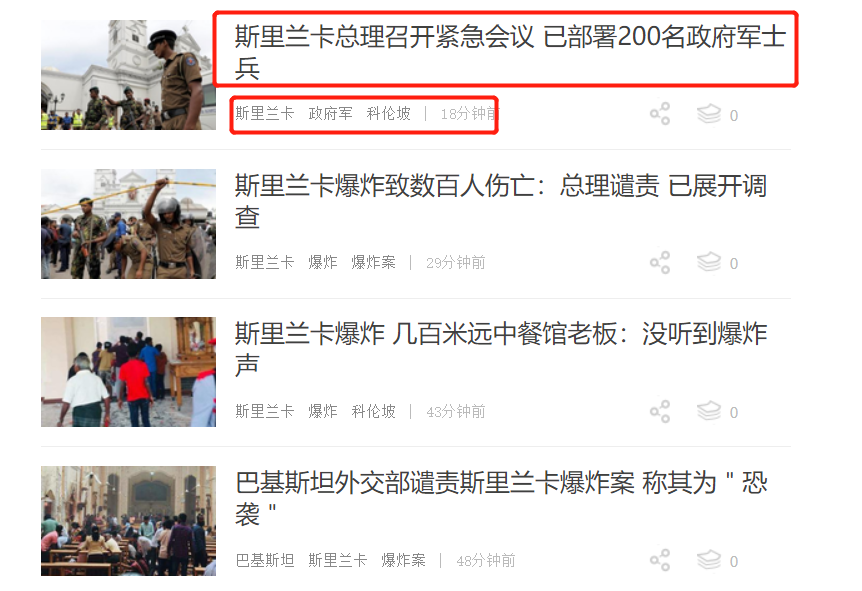
特点:
动态加载数据 ,用 selenium
爬虫
1. 创建项目
scrapy startproject wy
2. 创建爬虫
scrapy genspider wangyi www.wangyi.com
撰写爬虫
1. 获取板块url
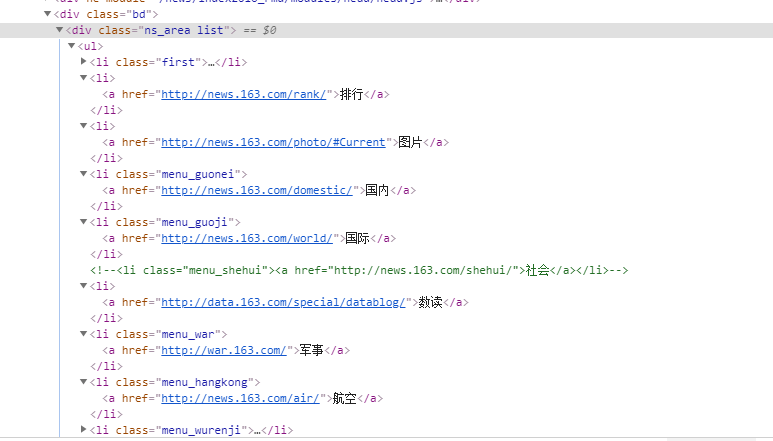
import scrapy class WangyiSpider(scrapy.Spider):
name = 'wangyi'
# allowed_domains = ['www.wangyi.com']
start_urls = ['https://news.163.com/'] def parse(self, response): # 获取4大板块的url 国内、国际、军事、航空 li_list = response.xpath("//div[@class='ns_area list']/ul/li")
item_list =[]
for li in li_list: url = li.xpath("./a/@href").extract_first()
title = li.xpath('./a/text()').extract_first().strip()
# 过滤出 国内、国际、军事、航空
if title in ['国内','国际','军事','航空']:
item = {}
item['title'] = title
item['url'] = url print(item)
1.过滤出想要板块的url和板块名爬虫
settings.py 文件中:
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
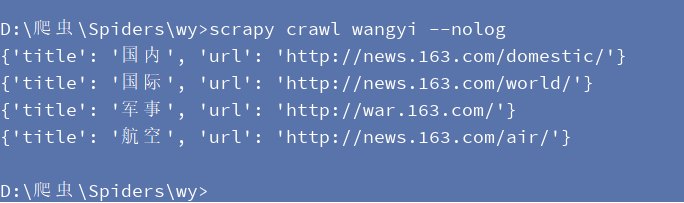
执行爬虫效果
2. 每个板块页面的爬取:
爬虫代码:
# 提取板块中的数据
def parse_content(self,response): title = response.meta.get('title')
div_list =response.xpath("//div[@class='ndi_main']/div") print(len(div_list))
for div in div_list:
item={}
item['group'] = title
img_url = div.xpath('./a/img/@src').extract_first()
article_url = div.xpath('./a/img/@href').extract_first()
head = div.xpath('./a/img/@alt').extract_first()
keywords = div.xpath('//div[@class="keywords"]//text()').extract()
# 将列表内容转换成字符串
content = "".join([i.strip() for i in keywords])
item['img_url'] = img_url
item['article_url'] = article_url
item['head'] = head
item['keywords'] = keywords yield scrapy.Request(
url=article_url,
callback=self.parse_detail,
meta={'item':copy.deepcopy(item)}
)
启动爬虫时没有打印出结果:
用xpath help 插件检查,发现所写的xpath表达式没有错,说明,该页面的数据可能是动态加载的数据

xpath显示有数据
解决动态数据使用selenium:
scrapy 中使用selenium 爬取步骤:
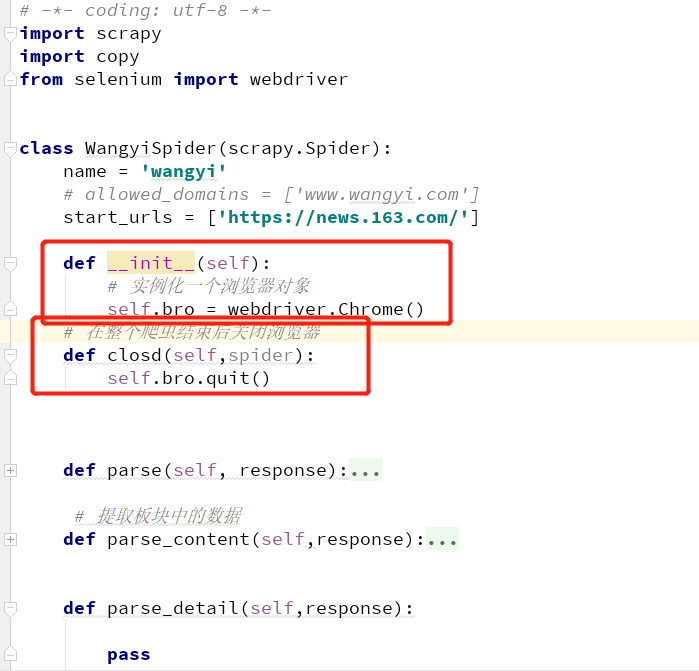
1. 在爬虫类中,重新构造方法 __init__,和写爬虫结束时关闭浏览器
2. 在下载中间键中
from scrapy.http import HtmlResponse
class WyDownloaderMiddleware(object): def process_request(self, request, spider): return None def process_response(self, request, response, spider):
# 拦截 响应
if request.url in [ 'http://news.163.com/domestic/','http://news.163.com/world/','http://war.163.com/','http://news.163.com/air/']: spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(3)
page_text=spider.bro.page_source return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8') else: return response
3. settings.py中,开启下载中间件
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'wy.middlewares.WyDownloaderMiddleware': 300,
}
UA池
1.在中间中自定义一个user_agent 中间件类 ,继承UserAgentMiddleware
#单独给UA池封装一个 下载中间件的类
# 需要导包 userAgentMiddleware
class RandomUserAgent(UserAgentMiddleware):
'''
UA池类
# 用faker 模块进行随机生成一个user_agent '''
def process_request(self, request, spider):
fake = Factory.create()
# 通过 faker模块随机生成一个ua
user_agent = fake.user_agent() request.headers.setdefault('User_Agent',user_agent)
2. 在settings.py 配置文件中:
DOWNLOADER_MIDDLEWARES = {
'wy.middlewares.WyDownloaderMiddleware': 300,
'wy.middlewares.RandomUserAgent': 543,
}
IP池
1. 中间件中:
# 批量对拦截到的请求对ip 进行更换 ,自定义一个ip代理类
class Proxy(object):
def process_request(self,request,spider):
# 两种 ip 池
proxy_http=['206.189.231.239:8080','66.42.116.151:8080']
proxy_https=['113.140.1.82:53281','36.79.152.0:8080']
# request.url 返回值 :http://www.xxx.com 或 https://www.xxx.com
h = request.url.split(":")[0]
if h=="http:":
ip = random.choices(proxy_http)
request.meta['proxy']='http://'+ip
else:
ip = random.choices(proxy_https)
request.meta['proxy'] = 'https://'+ip
2. settings.py 配置
DOWNLOADER_MIDDLEWARES = {
'wy.middlewares.WyDownloaderMiddleware': 543,
'wy.middlewares.RandomUserAgent': 542,
'wy.middlewares.Proxy': 541,
}
改为分布式爬虫
1. redis 配置文件redis.conf 进行修改
注释该行:#bind 127.0.0.1,表示可以让其他ip访问
将yes该为no:protected-mode no,表示可以让其他ip操作redis
2. 对爬虫进行修改
将爬虫类的父类修改成基于RedisSpider或者RedisCrawlSpider。注意:如果原始爬虫文件是基于Spider的,则应该将父类修改成RedisSpider,如果原始爬虫文件是基于CrawlSpider的,则应该将其父类修改成RedisCrawlSpider。
- 注释或者删除start_urls列表,切加入redis_key属性,属性值为scrpy-redis组件中调度器队列的名称
3. 在配置文件中进行相关配置,开启使用scrapy-redis组件中封装好的管道
ITEM_PIPELINES = { 'scrapy_redis.pipelines.RedisPipeline': }
4. 在配置文件中进行相关配置,开启使用scrapy-redis组件中封装好的调度器
# 使用scrapy-redis组件的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 是否允许暂停
SCHEDULER_PERSIST = True
5.在配置文件中进行爬虫程序链接redis的配置
REDIS_HOST = 'redis服务的ip地址'
REDIS_PORT = 6379
REDIS_ENCODING = ‘utf-8’
#REDIS_PARAMS = {‘password’:’123456’} # 有密码就需要写
6 开启redis服务器:redis-server 配置文件

7开启redis客户端:redis-cli
8 运行爬虫文件:
scrapy crawl wangyi
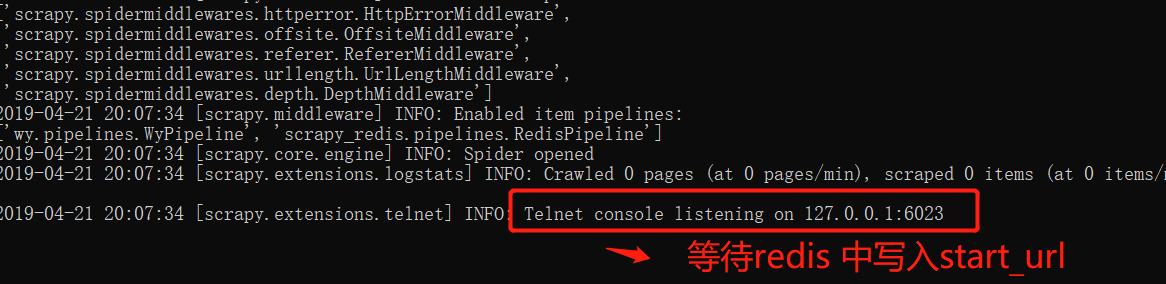
9 向调度器队列中扔入一个起始url(在redis客户端中操作):lpush redis_key属性值 起始url

selenium、UA池、ip池、scrapy-redis的综合应用案例的更多相关文章
- UA池 代理IP池 scrapy的下载中间件
# 一些概念 - 在scrapy中如何给所有的请求对象尽可能多的设置不一样的请求载体身份标识 - UA池,process_request(request) - 在scrapy中如何给发生异常的请求设置 ...
- scrapy版本爬取某网站,加入了ua池,ip池,不限速不封号,100个线程爬崩网站
目录 scrapy版本爬取妹子图 关键所在下载图片 前期准备 代理ip池 UserAgent池 middlewares中间件(破解反爬) settings配置 正题 爬虫 保存下载图片 scrapy版 ...
- 在Scrapy中使用IP池或用户代理更新版(python3)
middlewares.py # -*- coding: utf-8 -*- # 导入随机模块 import random # 导入有关IP池有关的模块 from scrapy.downloaderm ...
- 在Scrapy中使用IP池或用户代理(python3)
一.创建Scrapy工程 scrapy startproject 工程名 二.进入工程目录,根据爬虫模板生成爬虫文件 scrapy genspider -l # 查看可用模板 scrapy gensp ...
- Python爬虫代理IP池
目录[-] 1.问题 2.代理池设计 3.代码模块 4.安装 5.使用 6.最后 在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代 ...
- java爬虫进阶 —— ip池使用,iframe嵌套,异步访问破解
写之前稍微说一下我对爬与反爬关系的理解 一.什么是爬虫 爬虫英文是splider,也就是蜘蛛的意思,web网络爬虫系统的功能是下载网页数据,进行所需数据的采集.主体也就是根据开始的超链接,下 ...
- springboot实现java代理IP池 Proxy Pool,提供可用率达到95%以上的代理IP
一.背景 前段时间,写java爬虫来爬网易云音乐的评论.不料,爬了一段时间后ip被封禁了.由此,想到了使用ip代理,但是找了很多的ip代理网站,很少有可以用的代理ip.于是,抱着边学习的心态,自己开发 ...
- 自己设计代理IP池
大体思路 使用redis作为队列,买了一份蘑菇代理,但是这个代理每5秒可以请求一次,我们将IP请求出来,从redis列表队列的左侧插入,要用的时候再从右侧取出,请求成功证明该IP是可用的,将该代理IP ...
- 封装IP池和用户代理相应的类(python3)
一.middlewares.py源代码: # -*- coding: utf-8 -*- # 导入随机模块 import random # 导入有关IP池有关的模块 from scrapy.contr ...
随机推荐
- MQ消息队列配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- C#保存日志文件到txt中,可追加保存,定时删除最后一次操作半年前日志文件
/// <summary> /// 输出指定信息到文本文件 /// </summary> /// <param name="msg">输出信息& ...
- IOT
文档地址:http://www.owasp.org.cn/owasp-project/owasp-things?searchterm=iot 今天面试,面试官问到iot
- 配置php环境的一个nginx.conf
文件:nginx.conf 内容: #user nobody;worker_processes 1; #error_log logs/error.log;#error_log logs/err ...
- MAVEN简介之——pom.xml
maven构建的生命周期 maven是围绕着构建生命周期这个核心概念为基础的.maven里有3个内嵌的构建生命周期,default,clean和site. default是处理你项目部署的:clean ...
- python中sorted()和set()去重,排序
前言 在看一个聊天机器人的神经网络模型训练前准备训练数据,需要对训练材料做处理(转化成张量)需要先提炼词干,然后对词干做去重和排序 words = sorted(list(set(words))) 对 ...
- redis-使用问题
记录一下相关的问题,使用参考http://www.runoob.com/redis/ 1.DENIED Redis is running in protected mode 这个是启用了保护模式,这个 ...
- Redis的数据结构、通用操作及其特性
Redis的数据结构 五种数据类型: 字符串(String).字符串列表(list).字符串集合(set).有序字符串集合(sorted set).哈希(hash) key定义的注意点: 不要过长,不 ...
- python模块部分----模块、包、常用模块
0.来源:https://www.cnblogs.com/jin-xin/articles/9987155.html 1.导入模块 1.1模块就是一个python文件,模块名是文件名 1.2导入模块的 ...
- zabbix3.4实现sendEmail邮件报警
一.安装软件 wget http://caspian.dotconf.net/menu/Software/SendEmail/sendEmail-v1.56.tar.gz 创建目录 mkdir /us ...