抓包分析、多线程爬虫及xpath学习
1、抓包分析
1.1 Fiddler安装及基本操作
由于很多网站采用的是HTTPS协议,而fiddler默认不支持HTTPS,先通过设置使fiddler能抓取HTTPS网站,过程可参考(https://www.cnblogs.com/liulinghua90/p/9109282.html)。使用clear可以将当前fiddler清屏。
1.2 通过抓包爬取腾讯视频评论
unicode转码:在Python中转码可以直接输入u'需要转码的内容'
由于每个视频后面的评论需要自动加载,在源代码中未发现有关评论的相关链接,此时就需要使用fiddler进行抓包分析,打开视频网站后,可以先使用clear清屏,找到JS包,可以复制它的url,打开后发现评论都是使用的Unicode编码,此时就需要解码。由于需要自动加载后面的评论,此时需要分析网页的构成。再使用一次clear,在网页上点击加载更多评论,在fiddler中找到JS包,复制url,将之与之前的url进行对比,重复几次该操作,构造评论url。
下面给出爬取腾讯视频中权力的游戏第八季评论:

1.3 微信文章爬取
进入weixin.sougou.com,搜索关键词为“Python”,也采取抓包分析,不过增加了代理,其余操作步骤与1.2类似。
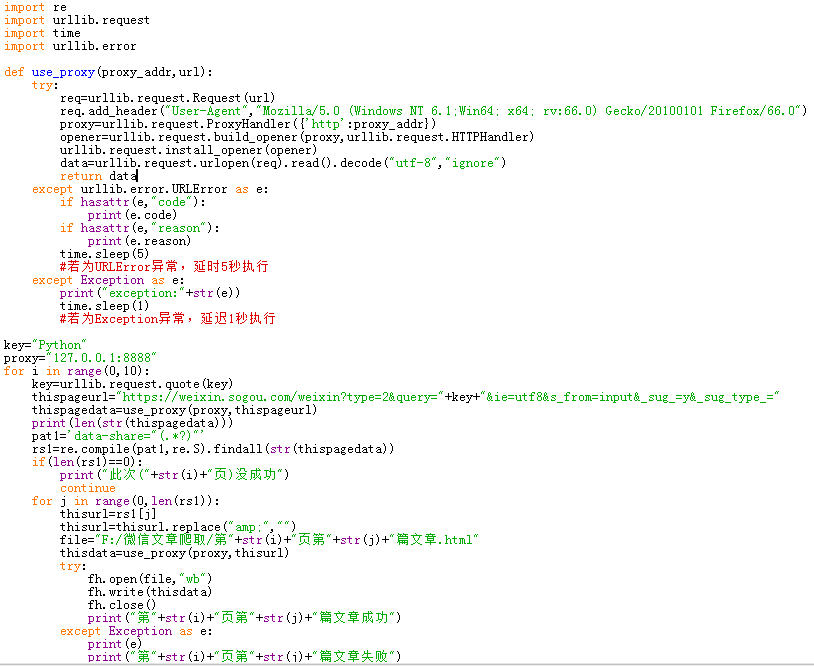
2、多线程爬虫
多线程,即程序中的某些程序段并行执行,合理地设置多线程,可以让爬虫的效率更高。

运行之后的结果为:

可以看出两个线程是同时开始工作的,那么如果用多线程爬取多个网页的话,就可以更加高效。下面将用多线程爬取糗事百科的文字内容:

首先需要分析网页的构造,通过翻页将规律找出来,实现在程序中实现自动翻页加载文本,其次需要将内容解码输出,最后需要加上异常处理。
3、scrapy xpath
/标签名:从顶端开始,如/html从顶端开始寻找html这个标签,找到的是这个标签内的内容
//标签名:寻找所有该标签
text():提取文本信息
@属性:提取属性信息
命令行输入:scrapy startproject 爬虫名,表示新建一个爬虫;如果新建一个自动爬虫,则先输入:scrapy startproject 爬虫名,再输入:scrapy genspider -t crawl 爬虫名 网址
items.py主要用来设置爬取的目标
pipelines.py设置后续的处理
settings.py主要用于配置信息
抓包分析、多线程爬虫及xpath学习的更多相关文章
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续一)
通过前一节得出地址可能的构建规律,如下: https://s.taobao.com/search?data-key=s&data-value=44&ajax=true&_ksT ...
- 爬虫系列(二) Chrome抓包分析
在这篇文章中,我们将尝试使用直观的网页分析工具(Chrome 开发者工具)对网页进行抓包分析,更加深入的了解网络爬虫的本质与内涵 1.测试环境 浏览器:Chrome 浏览器 浏览器版本:67.0.33 ...
- python爬虫(3)——用户和IP代理池、抓包分析、异步请求数据、腾讯视频评论爬虫
用户代理池 用户代理池就是将不同的用户代理组建成为一个池子,随后随机调用. 作用:每次访问代表使用的浏览器不一样 import urllib.request import re import rand ...
- FTP协议的粗浅学习--利用wireshark抓包分析相关tcp连接
一.为什么写这个 昨天遇到个ftp相关的问题,关于ftp匿名访问的.花费了大量的脑细胞后,终于搞定了服务端的配置,现在客户端可以像下图一样,直接在浏览器输入url,即可直接访问. 期间不会弹出输入用户 ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析(续二)
一.URL分析 通过对“Python机器学习”结果抓包分析,有两个无规律的参数:_ksTS和callback.通过构建如下URL可以获得目标关键词的检索结果,如下所示: https://s.taoba ...
- Python 爬虫知识点 - 淘宝商品检索结果抓包分析
一.抓包基础 在淘宝上搜索“Python机器学习”之后,试图抓取书名.作者.图片.价格.地址.出版社.书店等信息,查看源码发现html-body中没有这些信息,分析脚本发现,数据存储在了g_page_ ...
- Java网络编程学习A轮_02_抓包分析TCP三次握手过程
参考资料: https://huoding.com/2013/11/21/299 https://hpbn.co/building-blocks-of-tcp/#three-way-handshake ...
- 抓包分析SSL/TLS连接建立过程【总结】
1.前言 最近在倒腾SSL方面的项目,之前只是虽然对SSL了解过,但是不够深入,正好有机会,认真学习一下.开始了解SSL的是从https开始的,自从百度支持https以后,如今全站https的趋势越来 ...
- wireshark 抓包分析 TCPIP协议的握手
wireshark 抓包分析 TCPIP协议的握手 原网址:http://www.cnblogs.com/TankXiao/archive/2012/10/10/2711777.html 之前写过一篇 ...
随机推荐
- gitlab服务器搭建
当然喜欢英文的可以参考官方文档:https://about.gitlab.com/downloads/ 1. 根据自己的操作系统选择相应的安装方法,我这边是阿里云 centos 7的 sudo yu ...
- JVM的垃圾回收机制 总结(垃圾收集、回收算法、垃圾回收器)
相信和小编一样的程序猿们在日常工作或面试当中经常会遇到JVM的垃圾回收问题,有没有在夜深人静的时候详细捋一捋JVM垃圾回收机制中的知识点呢?没时间捋也没关系,因为小编接下来会给你捋一捋. 一. 技术 ...
- 【easy】206. Reverse Linked List 链表反转
链表反转,一发成功~ /** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; ...
- cocos2dx-lua 文件操作
print("开始") --检查文件是否存在 local path = "ABC.txt" local fileExist = cc.FileUtils:get ...
- LuoGu P4996 咕咕咕
题目描述 小 F 是一个能鸽善鹉的同学,他经常把事情拖到最后一天才去做,导致他的某些日子总是非常匆忙. 比如,时间回溯到了 2018 年 11 月 3 日.小 F 望着自己的任务清单: 看 iG 夺冠 ...
- 1、Filebeat概述
Filebeat是一个轻量级的日志托运工具,用于转发和集中日志数据. Filebeat作为代理安装在服务器上,监控指定的日志文件或目录,收集日志事件,并将它们转发到Elasticsearch或Logs ...
- Zombie Scanning
1.theree -way handshake A TCP SYN packet is sent from the device that wishes to establish a connecti ...
- ycmd for emacs 代码自动补全
YCMD FOR EMACS Table of Contents 1. 安装 1.1. 下载 1.2. 安装相关依赖 1.3. 更新submodules 1.4. 安装 2. 配置 1 安装 1. ...
- 如何破解Excel VBA密码
首先,如果文件格式是(.xslm),需要先打开Excel文件,另存为2003版格式(.xls). 然后用普通的文本编辑器(我用的是NotePad++)打开这个文件,注意文件类型选“所有文件”. 然后在 ...
- Leetcode | 组目录
数组 [1]999. 车的可用捕获量 [2]989. 数组形式的整数加法