Python笔记(十四):操作excel openpyxl模块
(一) 常遇到的情况
就我自己来说,常遇到的情况可能就下面几种:
- 读取excel整个sheet页的数据。
- 读取指定行、列的数据
- 往一个空白的excel文档写数据
- 往一个已经有数据的excel文档追加数据
下面就以这几种情况为例进行说明。
(二) 涉及的模块及函数说明
就我知道的,有3个模块可以操作excel文档,3个模块通过pip都可以直接安装。
xlrd:读数据
xlwt:写数据
openpyxl:可以读数据,也可以写数据
这里就就只说明openpyxl了,因为这个模块能满足上面的需要了。
openpyxl函数
|
函数 |
说明 |
|
load_workbook(filename) |
打开excel,并返回所有sheet页 访问指定sheet页的方法: #打开excel文档 #关闭excel文档 wb.close() |
Workbook() |
创建excel文档 wb = openpyxl.Workbook() #保存excel文档 wb.save('文件名.xlsx') |
|
下面的函数是针对sheet页的 sheet = wb[‘sheet页的名称’] 访问指定单元格的方式sheet['A1']、sheet['B1']... |
|
|
min_row |
返回包含数据的最小行索引,索引从1开始 例如:sheet.min_row |
|
max_row |
返回包含数据的最大行索引,索引从1开始 |
|
min_column |
返回包含数据的最小列索引,索引从1开始 |
|
max_column |
返回包含数据的最大列索引,索引从1开始 |
|
values |
获取excel文档所有的数据,返回的是一个generator对象 |
|
iter_rows(min_row=None, max_row=None, min_col=None, max_col=None) |
min_row:最小行索引 max_row:最大行索引 min_col:最小列索引 max_col:最大列索引 获取指定行、列的单元格,没指定就是获取所有的 |
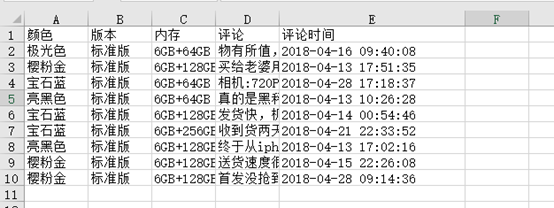
现在我有这么一个excel,下面以这个excel进行说明。
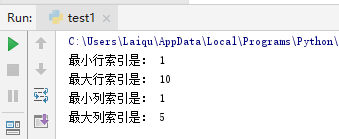
关于min_row、max_row这些,看下面的输出就很直观了
import openpyxl def get_data_openpyxl(file_name,sheet):
#打开excel文档
wb = openpyxl.load_workbook(file_name)
#访问sheet页
sheet = wb[sheet]
# 包含数据的最小行索引,从1开始
minRow = sheet.min_row
print("最小行索引是:", minRow)
#包含数据的最大行索引,从1开始
maxRow = sheet.max_row
print("最大行索引是:",maxRow)
#包含数据的最小列索引
minColumn = sheet.min_column
print("最小列索引是:",minColumn)
#包含数据的最大列索引
maxColumn = sheet.max_column
print("最大列索引是:", maxColumn)
wb.close()
get_data_openpyxl('测试.xlsx','Sheet')
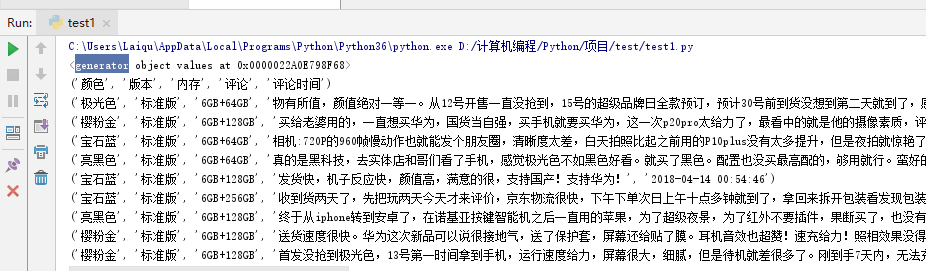
(三) 读取excel整个sheet页的数据
下面的代码都是没加异常处理的,要加的话自己看情况加上异常处理就行了。
import openpyxl def get_data_openpyxl(file_name,sheet):
#打开excel文档
wb = openpyxl.load_workbook(file_name)
#访问sheet页
sheet = wb[sheet]
# 获取excel文档所有的数据,返回的是一个generator对象
data = sheet.values
print(data)
#迭代输出所有数据
for i in data:
print(i)
wb.close()
get_data_openpyxl('测试.xlsx','Sheet')
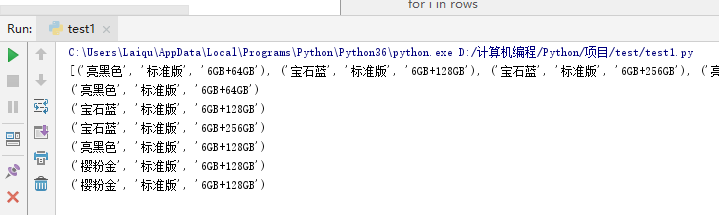
(四) 读取指定行、列的数据
这里有个问题就是,openpyxl模块貌似没有读取指定行、列数据的函数,不过没关系,自己封装一个函数去实现就行了,这个是通用的(前提是已经安装openpyxl),可以创建一个类(可以根据函数的作用创建多个不同的类,这个看自己了),放一些自己写的常用函数。
import openpyxl def get_data_iter(file_name,sheet, max_row=None,min_row=None,max_col=None,min_col=None):
''' :param file_name: excel文件名称
:param sheet: sheet页名称
:param max_row:最大行索引,未指定则获取所有行的数据
:param min_row: 最小行索引,未指定则从第一行开始
:param min_col:最小列索引,未指定则从第一列开始
:param max_col:最大列索引,未指定则获取所有列的数据
:return:返回指定行、列的数据
'''
# 打开excel文档
wb = openpyxl.load_workbook(file_name)
# 访问sheet页
sheet = wb[sheet]
# 获得指定行列的单元格
cell = sheet.iter_rows(max_row=max_row, min_row=min_row, max_col=max_col, min_col=min_col)
all_rows = []
# 获取单元格的值
for row in cell:
rows = []
for c in row:
rows.append(c.value)
all_rows.append(tuple(rows))
wb.close()
return all_rows rows = get_data_iter('测试.xlsx','Sheet',max_row=10,min_row=5,max_col=3,min_col=1)
print(rows)
for i in rows:
print(i)
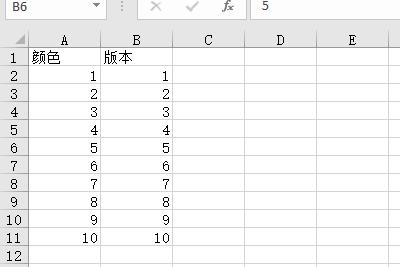
(五) 往空白的excel文档写数据
import openpyxl #创建excel文档
wb =openpyxl.Workbook()
sheet = wb['Sheet']
sheet['A1'] = '颜色'
sheet['B1'] = '版本'
x = 2
for i in range(10):
sheet['A'+str(x)] = i+1
sheet['B'+str(x)] = i+1
x += 1 wb.save('测试写数据.xlsx')
执行后,可以在当前工作目录下看到这个excel文档
(六) 往一个已经有数据的excel文档追加数据
要追加数据的话,获取已经有数据的最大索引就行了,从下一行开始添加数据,这里X的初始值忘记加1了,代码就不修改了,能看明白就行了
import openpyxl # 打开excel文档
wb = openpyxl.load_workbook('测试写数据.xlsx')
# 访问sheet页
sheet = wb['Sheet']
#获取最大行索引
maxRow = sheet.max_row
x = maxRow
for i in range(10):
sheet['A'+str(x)] = '追加数据'
sheet['B'+str(x)] = '追加数据'
x += 1 wb.save('测试写数据.xlsx')
执行完后:

Python笔记(十四):操作excel openpyxl模块的更多相关文章
- Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式
Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式 目录 Pycharm使用技巧(转载) Python第一天 安装 shell 文件 Py ...
- python3操作Excel openpyxl模块的使用
python 与excel 安装模块 本例子中使用的模块为: openpyxl 版本为2.4.8 安装方法请参看以前发表的文章(Python 的pip模块安装方法) Python处理Excel表格 使 ...
- Python笔记(十四)_永久存储pickle
pickle模块:将所有的Python对象转换成二进制文件存放 应用场景:编程时最好将大对象(列表.字典.集合等)用pickle写成永久数据包供程序调用,而不是直接写入程序 写入过程:将list转换为 ...
- python笔记十四(高阶函数——map/reduce、filter、sorted)
一.map/reduce 1.map() map(f,iterable),将一个iterable对象一次作用于函数f,并返回一个迭代器. >>> def f(x): #定义一个函数 ...
- python制作简单excel统计报表2之操作excel的模块openpyxl简单用法
python制作简单excel统计报表2之操作excel的模块openpyxl简单用法 # coding=utf-8 from openpyxl import Workbook, load_workb ...
- VSTO学习笔记(十四)Excel数据透视表与PowerPivot
原文:VSTO学习笔记(十四)Excel数据透视表与PowerPivot 近期公司内部在做一种通用查询报表,方便人力资源分析.统计数据.由于之前公司系统中有一个类似的查询使用Excel数据透视表完成的 ...
- Python第二十四天 binascii模块
Python第二十四天 binascii模块 binascii用来进行进制和字符串之间的转换 import binascii s = 'abcde' h = binascii.b2a_hex(s) # ...
- Python 3标准库 第十四章 应用构建模块
Python 3标准库 The Python3 Standard Library by Example -----------------------------------------第十四章 ...
- 孤荷凌寒自学python第二十四天python类中隐藏的私有方法探秘
孤荷凌寒自学python第二十四天python类中隐藏的私有方法探秘 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天发现了python的类中隐藏着一些特殊的私有方法. 这些私有方法不管我 ...
随机推荐
- Ubuntu 16.04 python和OpenCV安装
Ubuntu 16.04 python和OpenCV安装:最进在做深度学习和计算机视觉的有关内容,因此要在python中用到opencv.我的电脑装的是Ubuntu 16.04,python 2.7和 ...
- Maven - 实例-5-依赖冲突
避免依赖冲突的原则 如果项目中的pom.xml没有指定依赖的信息,而是通过继承来引用依赖,则很有可能发生继承同一个依赖的多个版本,从而产生依赖冲突. Maven通过如下两个原则来避免依赖冲突: 1- ...
- 昕有灵犀-xyFS私有文件云存储OSS服务
本工程为本人开发的开源项目,地址: https://gitee.com/475660/xyFS 介绍: 一站式企业私有文件服务.针对软件开发时提供的文件存储系统,对文件上传.下载.分类.分组.审计.统 ...
- 橙色优学:2019年设计行业怎么样?UI设计行业前景分析
互联网的飞速发展带动了UI行业的火爆,成为时下最热门的高新技术行业.UI设计区别于传统的平面设计,更加注重界面.交互.体验等方面,这使UI设计变为了高薪的行业,对设计师的技能要求也就变得更加严格. 自 ...
- odoo开发笔记 -- 进入后台调试模式
./odoo-bin shell -d test1 -c /home/odoo/odooshare/odoo.conf ./odoo-bin shell -d 数据库名 -c 指定配置文件
- 使用Jenkins部署Spring Boot项目
jenkins是devops神器,本篇文章介绍如何安装和使用jenkins部署Spring Boot项目 jenkins搭建 部署分为三个步骤: 第一步,jenkins安装 第二步,插件安装和配置 第 ...
- antd tree组件文件名换行 + 点击展开时,自动收起同级其他展开目录
1.在项目中用 antd的tree组件的时候,遇到两个问题 1.文件名太长的话 会超出容器 很难看,解决方法如下 ` 引入css在global下设置 :global { .ant-tree li .a ...
- 从零开始学 Web 之 Ajax(三)Ajax 概述,快速上手
大家好,这里是「 从零开始学 Web 系列教程 」,并在下列地址同步更新...... github:https://github.com/Daotin/Web 微信公众号:Web前端之巅 博客园:ht ...
- Windows10安装Docker
一.Docker下载安装 一般情况下,我们可以从Docker官网docker下载安装文件,但是官方网站由于众所周知的原因,不是访问慢,就是下载慢.下载docker安装包动不动就要个把小时,真是极大的影 ...
- C# 微信公众号开发--准备工作
前言 最初打算熟悉下微信开发打算用node.js开发,结果底气不足先用C#开发,先踩了踩坑. 准备工作 微信公众平台开发者文档. 这个先多看几遍. 测试公众号,申请开通后会看到微信号,appID,ap ...