Python笔记(十四):操作excel openpyxl模块
(一) 常遇到的情况
就我自己来说,常遇到的情况可能就下面几种:
- 读取excel整个sheet页的数据。
- 读取指定行、列的数据
- 往一个空白的excel文档写数据
- 往一个已经有数据的excel文档追加数据
下面就以这几种情况为例进行说明。
(二) 涉及的模块及函数说明
就我知道的,有3个模块可以操作excel文档,3个模块通过pip都可以直接安装。
xlrd:读数据
xlwt:写数据
openpyxl:可以读数据,也可以写数据
这里就就只说明openpyxl了,因为这个模块能满足上面的需要了。
openpyxl函数
|
函数 |
说明 |
|
load_workbook(filename) |
打开excel,并返回所有sheet页 访问指定sheet页的方法: #打开excel文档 #关闭excel文档 wb.close() |
Workbook() |
创建excel文档 wb = openpyxl.Workbook() #保存excel文档 wb.save('文件名.xlsx') |
|
下面的函数是针对sheet页的 sheet = wb[‘sheet页的名称’] 访问指定单元格的方式sheet['A1']、sheet['B1']... |
|
|
min_row |
返回包含数据的最小行索引,索引从1开始 例如:sheet.min_row |
|
max_row |
返回包含数据的最大行索引,索引从1开始 |
|
min_column |
返回包含数据的最小列索引,索引从1开始 |
|
max_column |
返回包含数据的最大列索引,索引从1开始 |
|
values |
获取excel文档所有的数据,返回的是一个generator对象 |
|
iter_rows(min_row=None, max_row=None, min_col=None, max_col=None) |
min_row:最小行索引 max_row:最大行索引 min_col:最小列索引 max_col:最大列索引 获取指定行、列的单元格,没指定就是获取所有的 |
现在我有这么一个excel,下面以这个excel进行说明。
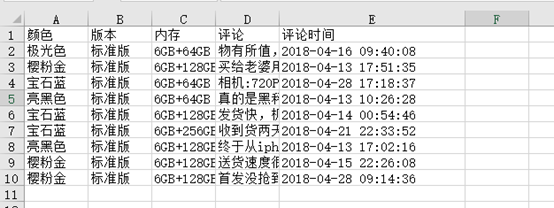
关于min_row、max_row这些,看下面的输出就很直观了
import openpyxl def get_data_openpyxl(file_name,sheet):
#打开excel文档
wb = openpyxl.load_workbook(file_name)
#访问sheet页
sheet = wb[sheet]
# 包含数据的最小行索引,从1开始
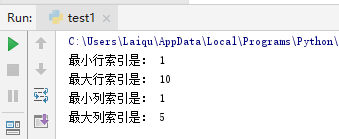
minRow = sheet.min_row
print("最小行索引是:", minRow)
#包含数据的最大行索引,从1开始
maxRow = sheet.max_row
print("最大行索引是:",maxRow)
#包含数据的最小列索引
minColumn = sheet.min_column
print("最小列索引是:",minColumn)
#包含数据的最大列索引
maxColumn = sheet.max_column
print("最大列索引是:", maxColumn)
wb.close()
get_data_openpyxl('测试.xlsx','Sheet')
(三) 读取excel整个sheet页的数据
下面的代码都是没加异常处理的,要加的话自己看情况加上异常处理就行了。
import openpyxl def get_data_openpyxl(file_name,sheet):
#打开excel文档
wb = openpyxl.load_workbook(file_name)
#访问sheet页
sheet = wb[sheet]
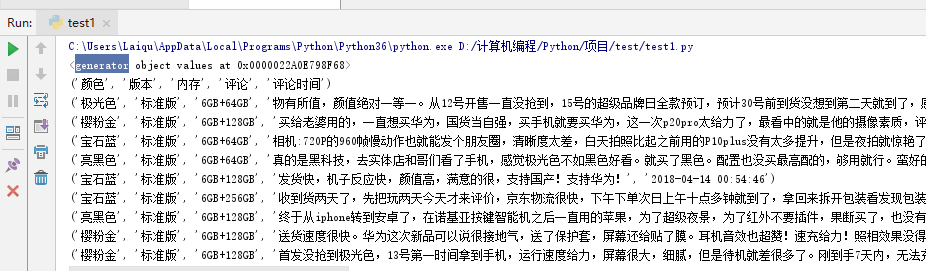
# 获取excel文档所有的数据,返回的是一个generator对象
data = sheet.values
print(data)
#迭代输出所有数据
for i in data:
print(i)
wb.close()
get_data_openpyxl('测试.xlsx','Sheet')
(四) 读取指定行、列的数据
这里有个问题就是,openpyxl模块貌似没有读取指定行、列数据的函数,不过没关系,自己封装一个函数去实现就行了,这个是通用的(前提是已经安装openpyxl),可以创建一个类(可以根据函数的作用创建多个不同的类,这个看自己了),放一些自己写的常用函数。
import openpyxl def get_data_iter(file_name,sheet, max_row=None,min_row=None,max_col=None,min_col=None):
''' :param file_name: excel文件名称
:param sheet: sheet页名称
:param max_row:最大行索引,未指定则获取所有行的数据
:param min_row: 最小行索引,未指定则从第一行开始
:param min_col:最小列索引,未指定则从第一列开始
:param max_col:最大列索引,未指定则获取所有列的数据
:return:返回指定行、列的数据
'''
# 打开excel文档
wb = openpyxl.load_workbook(file_name)
# 访问sheet页
sheet = wb[sheet]
# 获得指定行列的单元格
cell = sheet.iter_rows(max_row=max_row, min_row=min_row, max_col=max_col, min_col=min_col)
all_rows = []
# 获取单元格的值
for row in cell:
rows = []
for c in row:
rows.append(c.value)
all_rows.append(tuple(rows))
wb.close()
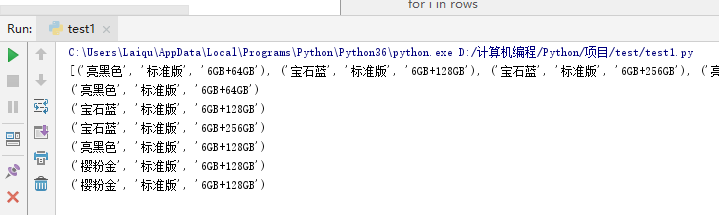
return all_rows rows = get_data_iter('测试.xlsx','Sheet',max_row=10,min_row=5,max_col=3,min_col=1)
print(rows)
for i in rows:
print(i)
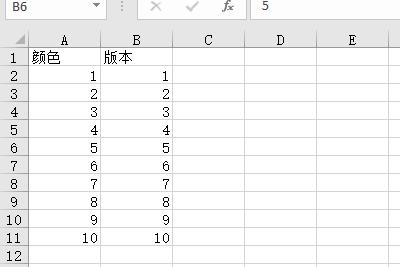
(五) 往空白的excel文档写数据
import openpyxl #创建excel文档
wb =openpyxl.Workbook()
sheet = wb['Sheet']
sheet['A1'] = '颜色'
sheet['B1'] = '版本'
x = 2
for i in range(10):
sheet['A'+str(x)] = i+1
sheet['B'+str(x)] = i+1
x += 1 wb.save('测试写数据.xlsx')
执行后,可以在当前工作目录下看到这个excel文档
(六) 往一个已经有数据的excel文档追加数据
要追加数据的话,获取已经有数据的最大索引就行了,从下一行开始添加数据,这里X的初始值忘记加1了,代码就不修改了,能看明白就行了
import openpyxl # 打开excel文档
wb = openpyxl.load_workbook('测试写数据.xlsx')
# 访问sheet页
sheet = wb['Sheet']
#获取最大行索引
maxRow = sheet.max_row
x = maxRow
for i in range(10):
sheet['A'+str(x)] = '追加数据'
sheet['B'+str(x)] = '追加数据'
x += 1 wb.save('测试写数据.xlsx')
执行完后:

Python笔记(十四):操作excel openpyxl模块的更多相关文章
- Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式
Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式 目录 Pycharm使用技巧(转载) Python第一天 安装 shell 文件 Py ...
- python3操作Excel openpyxl模块的使用
python 与excel 安装模块 本例子中使用的模块为: openpyxl 版本为2.4.8 安装方法请参看以前发表的文章(Python 的pip模块安装方法) Python处理Excel表格 使 ...
- Python笔记(十四)_永久存储pickle
pickle模块:将所有的Python对象转换成二进制文件存放 应用场景:编程时最好将大对象(列表.字典.集合等)用pickle写成永久数据包供程序调用,而不是直接写入程序 写入过程:将list转换为 ...
- python笔记十四(高阶函数——map/reduce、filter、sorted)
一.map/reduce 1.map() map(f,iterable),将一个iterable对象一次作用于函数f,并返回一个迭代器. >>> def f(x): #定义一个函数 ...
- python制作简单excel统计报表2之操作excel的模块openpyxl简单用法
python制作简单excel统计报表2之操作excel的模块openpyxl简单用法 # coding=utf-8 from openpyxl import Workbook, load_workb ...
- VSTO学习笔记(十四)Excel数据透视表与PowerPivot
原文:VSTO学习笔记(十四)Excel数据透视表与PowerPivot 近期公司内部在做一种通用查询报表,方便人力资源分析.统计数据.由于之前公司系统中有一个类似的查询使用Excel数据透视表完成的 ...
- Python第二十四天 binascii模块
Python第二十四天 binascii模块 binascii用来进行进制和字符串之间的转换 import binascii s = 'abcde' h = binascii.b2a_hex(s) # ...
- Python 3标准库 第十四章 应用构建模块
Python 3标准库 The Python3 Standard Library by Example -----------------------------------------第十四章 ...
- 孤荷凌寒自学python第二十四天python类中隐藏的私有方法探秘
孤荷凌寒自学python第二十四天python类中隐藏的私有方法探秘 (完整学习过程屏幕记录视频地址在文末,手写笔记在文末) 今天发现了python的类中隐藏着一些特殊的私有方法. 这些私有方法不管我 ...
随机推荐
- 使用Swagger 搭建高可读性ASP.Net WebApi文档
一.前言 在最近一个商城项目中,使用WebApi搭建API项目.但开发过程中,前后端工程师对于沟通接口的使用,是非常耗时的.之前也有用过Swagger构建WebApi文档,但是API文档的可读性并不高 ...
- vue 自学笔记(6) axios的使用
前情提要:axios 的使用 axios是一个ajax 的包,主要在node.js 使用 axios 的官网 https://www.kancloud.cn/yunye/axios/234845 一: ...
- postgresql-删除重复数据
greenplum最终的方法是: delete from test where (gp_segment_id, ctid) not in (select gp_segment_id, min(ct ...
- [COI2007] Sabor
下面给出这道一脸不可做的题的鬼畜性质: 1)对于一个点来说,其归属状态是确定的:走不到.A党或B党 .(黑白格染色) 方便起见,将包含所有不可达的点的极小矩形向外扩展一圈,设为矩形M. 2)矩形M的最 ...
- 使用git往gitee传数据时pull命令的使用
按‘i’进入编辑模式------->写入内容------>按Esc键退出-------->在左下角的冒号后面输入‘wq’,表示退出并保存
- springboot+cloud 学习(四)Zuul整合Swagger2
前言 在微服务架构下,服务是分散的,怎么把所有服务接口整合到一起是我们需要关注的. 下面举例用zuul作为分布式系统的网关,同时使用swagger生成文档,想把整个系统的文档整合在同一个页面上来说明. ...
- Shell 数组定义与获取
Shell 数组 bash支持一维数组(不支持多维数组),并且没有限定数组的大小. 类似与 C 语言,数组元素的下标由 0 开始编号.获取数组中的元素要利用下标,下标可以是整数或算术表达式,其值应大于 ...
- Vim 匹配相同的单词并高亮
将光标移动到要匹配的单词处: "g + d" :高亮显示所有相同的单词 shift + "*" :向下查找相同单词并高亮显示 shift + "#&q ...
- angularjs小练习(分别通过ng-repeat和ng-option动态生成select下拉框)
本次做一个简单的关于动态生成select的练习 在实现上有两种方式: 其一.通过ng-repeat来实现 其二.通过ng-option来实现 在页面效果上,两种实现的效果都一样 但是在数据选择的数据从 ...
- CentOS6.5安装mysql以及常见问题的解决
前言 最近在学习Linux系统,今天在安装MySQL数据库时出现很多问题,花费了两个小时终于解决,故记录下来以供大家参考.(本人目前还在学习阶段,下面写到的是自己结合网上查到的资料以及各位前辈给出的解 ...