1.11 flask
2019-1-11 16:14:34
还有一天flask剩下的就是爬虫了!
越努力,越幸运!永远不要高估自己!
别人玩,你在默默努力!上帝不会亏待你的!
Flask-SQLAlchemy参考连接
https://www.cnblogs.com/wupeiqi/articles/8259356.html
wtforms组件会用就好,没必要非得搞明白源码!
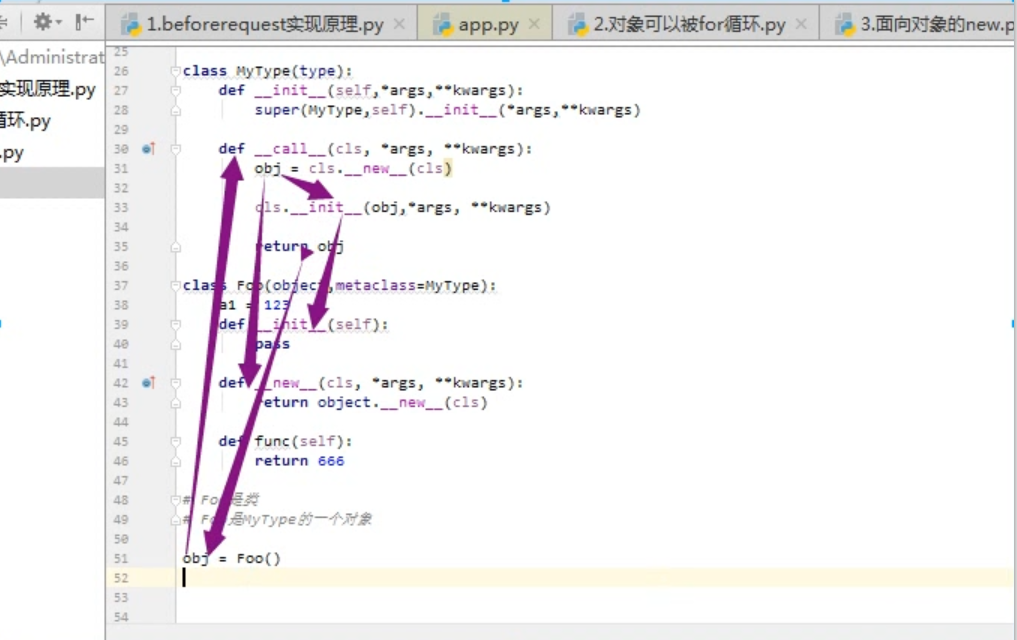
创建个对象过程
wtforms实现,py
from flask import Flask,request,render_template,session,current_app,g,redirect
from wtforms import Form
from wtforms.csrf.core import CSRF
from wtforms.fields import simple
from wtforms.fields import html5
from wtforms.fields import core
from hashlib import md5 from wtforms import widgets
from wtforms import validators app = Flask(__name__) class LoginForm(Form):
name = simple.StringField(
validators=[
validators.DataRequired(message='用户名不能为空.'),
],
widget=widgets.TextInput(),
render_kw={'placeholder':'请输入用户名'}
)
pwd = simple.PasswordField(
validators=[
validators.DataRequired(message='密码不能为空.'), ],
render_kw={'placeholder':'请输入密码'}
) def validate_name(self, field):
"""
自定义name字段规则
:param field:
:return:
"""
# 最开始初始化时,self.data中已经有所有的值
print('钩子函数获取的值',field.data)
if not field.data.startswith('old'):
raise validators.ValidationError("用户名必须以old开头") # 继续后续验证
# raise validators.StopValidation("用户名必须以old开头") # 不再继续后续验证 @app.route('/login',methods=['GET','POST'])
def login():
if request.method == "GET":
form = LoginForm()
return render_template('login.html',form=form) form = LoginForm(formdata=request.form)
if form.validate():
print(form.data)
return redirect('https://www.luffycity.com/home')
else:
return render_template('login.html', form=form) if __name__ == '__main__':
app.run()
models.py
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column
from sqlalchemy import Integer,String,Text,Date,DateTime,ForeignKey,UniqueConstraint, Index
from sqlalchemy import create_engine
from sqlalchemy.orm import relationship Base = declarative_base() class Depart(Base):
__tablename__ = 'depart'
id = Column(Integer, primary_key=True)
title = Column(String(32), index=True, nullable=False) class Users(Base):
__tablename__ = 'users' id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False)
depart_id = Column(Integer,ForeignKey("depart.id")) dp = relationship("Depart", backref='pers') class Student(Base):
__tablename__ = 'student'
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False) course_list = relationship('Course', secondary='student2course', backref='student_list') class Course(Base):
__tablename__ = 'course'
id = Column(Integer, primary_key=True)
title = Column(String(32), index=True, nullable=False) class Student2Course(Base):
__tablename__ = 'student2course'
id = Column(Integer, primary_key=True, autoincrement=True)
student_id = Column(Integer, ForeignKey('student.id'))
course_id = Column(Integer, ForeignKey('course.id')) __table_args__ = (
UniqueConstraint('student_id', 'course_id', name='uix_stu_cou'), # 联合唯一索引
# Index('ix_id_name', 'name', 'extra'), # 联合索引
) def create_all():
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
) Base.metadata.create_all(engine) def drop_all():
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
Base.metadata.drop_all(engine) if __name__ == '__main__':
# drop_all()
create_all()
用SQLalchemy查询
s1.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Users engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查
session = SessionFactory() # ############################## 基本增删改查 ###############################
# 1. 增加
# obj = Users(name='alex')
# session.add(obj)
# session.commit() # session.add_all([
# Users(name='小东北'),
# Users(name='龙泰')
# ])
# session.commit() # 2. 查
# result = session.query(Users).all()
# for row in result:
# print(row.id,row.name) # result = session.query(Users).filter(Users.id >= 2)
# for row in result:
# print(row.id,row.name) # result = session.query(Users).filter(Users.id >= 2).first()
# print(result) # 3.删
# session.query(Users).filter(Users.id >= 2).delete()
# session.commit() # 4.改
# session.query(Users).filter(Users.id == 4).update({Users.name:'东北'})
# session.query(Users).filter(Users.id == 4).update({'name':'小东北'})
# session.query(Users).filter(Users.id == 4).update({'name':Users.name+"DSB"},synchronize_session=False)
# session.commit() # ############################## 其他常用 ###############################
# 1. 指定列
# select id,name as cname from users;
# result = session.query(Users.id,Users.name.label('cname')).all()
# for item in result:
# print(item[0],item.id,item.cname)
# 2. 默认条件and
# session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
# 3. between
# session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
# 4. in
# session.query(Users).filter(Users.id.in_([1,3,4])).all()
# session.query(Users).filter(~Users.id.in_([1,3,4])).all()
# 5. 子查询
# session.query(Users).filter(Users.id.in_(session.query(Users.id).filter(Users.name=='eric'))).all()
# 6. and 和 or
# from sqlalchemy import and_, or_
# session.query(Users).filter(Users.id > 3, Users.name == 'eric').all()
# session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
# session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
# session.query(Users).filter(
# or_(
# Users.id < 2,
# and_(Users.name == 'eric', Users.id > 3),
# Users.extra != ""
# )).all() # 7. filter_by
# session.query(Users).filter_by(name='alex').all() # 8. 通配符
# ret = session.query(Users).filter(Users.name.like('e%')).all()
# ret = session.query(Users).filter(~Users.name.like('e%')).all() # 9. 切片
# result = session.query(Users)[1:2] # 10.排序
# ret = session.query(Users).order_by(Users.name.desc()).all()
# ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 11. group by
from sqlalchemy.sql import func # ret = session.query(
# Users.depart_id,
# func.count(Users.id),
# ).group_by(Users.depart_id).all()
# for item in ret:
# print(item)
#
# from sqlalchemy.sql import func
#
# ret = session.query(
# Users.depart_id,
# func.count(Users.id),
# ).group_by(Users.depart_id).having(func.count(Users.id) >= 2).all()
# for item in ret:
# print(item) # 12.union 和 union all
"""
select id,name from users
UNION
select id,name from users;
"""
# q1 = session.query(Users.name).filter(Users.id > 2)
# q2 = session.query(Favor.caption).filter(Favor.nid < 2)
# ret = q1.union(q2).all()
#
# q1 = session.query(Users.name).filter(Users.id > 2)
# q2 = session.query(Favor.caption).filter(Favor.nid < 2)
# ret = q1.union_all(q2).all() session.close()
s2.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Users,Depart engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查
session = SessionFactory() # 1. 查询所有用户
# ret = session.query(Users).all()
# for row in ret:
# print(row.id,row.name,row.depart_id)
# 2. 查询所有用户+所属部门名称
# ret = session.query(Users.id,Users.name,Depart.title).join(Depart,Users.depart_id == Depart.id).all()
# for row in ret:
# print(row.id,row.name,row.title) # query = session.query(Users.id,Users.name,Depart.title).join(Depart,Users.depart_id == Depart.id,isouter=True)
# print(query) # 3. relation字段:查询所有用户+所属部门名称
# ret = session.query(Users).all()
# for row in ret:
# print(row.id,row.name,row.depart_id,row.dp.title) # 4. relation字段:查询销售部所有的人员
# obj = session.query(Depart).filter(Depart.title == '销售').first()
# for row in obj.pers:
# print(row.id,row.name,obj.title) # 5. 创建一个名称叫:IT部门,再在该部门中添加一个员工:田硕
# 方式一:
# d1 = Depart(title='IT')
# session.add(d1)
# session.commit()
#
# u1 = Users(name='田硕',depart_id=d1.id)
# session.add(u1)
# session.commit() # 方式二:
# u1 = Users(name='田硕',dp=Depart(title='IT'))
# session.add(u1)
# session.commit() # 6. 创建一个名称叫:王者荣耀,再在该部门中添加一个员工:龚林峰/长好梦/王爷们
# d1 = Depart(title='王者荣耀')
# d1.pers = [Users(name='龚林峰'),Users(name='长好梦'),Users(name='王爷们'),]
# session.add(d1)
# session.commit() session.close()
s3.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Student,Course,Student2Course engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
SessionFactory = sessionmaker(bind=engine) # 根据Users类对users表进行增删改查
session = SessionFactory() # 1. 录入数据
# session.add_all([
# Student(name='先用'),
# Student(name='佳俊'),
# Course(title='生物'),
# Course(title='体育'),
# ])
# session.commit() # session.add_all([
# Student2Course(student_id=2,course_id=1)
# ])
# session.commit() # 2. 三张表关联
# ret = session.query(Student2Course.id,Student.name,Course.title).join(Student,Student2Course.student_id==Student.id,isouter=True).join(Course,Student2Course.course_id==Course.id,isouter=True).order_by(Student2Course.id.asc())
# for row in ret:
# print(row)
# 3. “先用”选的所有课
# ret = session.query(Student2Course.id,Student.name,Course.title).join(Student,Student2Course.student_id==Student.id,isouter=True).join(Course,Student2Course.course_id==Course.id,isouter=True).filter(Student.name=='先用').order_by(Student2Course.id.asc()).all()
# print(ret) # obj = session.query(Student).filter(Student.name=='先用').first()
# for item in obj.course_list:
# print(item.title) # 4. 选了“生物”的所有人
# obj = session.query(Course).filter(Course.title=='生物').first()
# for item in obj.student_list:
# print(item.name) # 5. 创建一个课程,创建2学生,两个学生选新创建的课程。
# obj = Course(title='英语')
# obj.student_list = [Student(name='为名'),Student(name='广宗')]
#
# session.add(obj)
# session.commit() session.close()
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Student,Course,Student2Course engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
SessionFactory = sessionmaker(bind=engine) def task():
# 去连接池中获取一个连接
session = SessionFactory() ret = session.query(Student).all() # 将连接交还给连接池
session.close() from threading import Thread for i in range(20):
t = Thread(target=task)
t.start()
s5.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session
from models import Student,Course,Student2Course engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
SessionFactory = sessionmaker(bind=engine)
session = scoped_session(SessionFactory) def task():
ret = session.query(Student).all()
# 将连接交还给连接池
session.remove() from threading import Thread for i in range(20):
t = Thread(target=task)
t.start()
s6.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session
from models import Student,Course,Student2Course engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/s9day120?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
SessionFactory = sessionmaker(bind=engine)
session = scoped_session(SessionFactory) def task():
""""""
# 方式一:
"""
# 查询
# cursor = session.execute('select * from users')
# result = cursor.fetchall() # 添加
cursor = session.execute('INSERT INTO users(name) VALUES(:value)', params={"value": 'wupeiqi'})
session.commit()
print(cursor.lastrowid)
"""
# 方式二:
"""
# conn = engine.raw_connection()
# cursor = conn.cursor()
# cursor.execute(
# "select * from t1"
# )
# result = cursor.fetchall()
# cursor.close()
# conn.close()
""" # 将连接交还给连接池
session.remove() from threading import Thread for i in range(20):
t = Thread(target=task)
t.start()
1.11 flask的更多相关文章
- 11.Flask钩子函数
在Flask中钩子函数是使用特定的装饰器的函数.为什么叫做钩子函数呢,是因为钩子函数可以在正常执行的代码中,插入一段自己想要执行的代码,那么这种函数就叫做钩子函数. before_first_requ ...
- Flask Web开发从入门到放弃(一)
第1章 章节一 01 内容概要 02 内容回顾 03 路飞学城之加入购物车 04 路飞学城之结算 05 路飞学城之立即支付 06 路飞学城之后续计划 07 Flask框架简介和快速使用 08 FLas ...
- 11.2,nginx负载均衡实验
Nginx负载均衡概述 Web服务器,直接面向用户,往往要承载大量并发请求,单台服务器难以负荷,我使用多台WEB服务器组成集群,前端使用Nginx负载均衡,将请求分散的打到我们的后端服务器集群中,实现 ...
- Python Flask构建可拓展的RESTful API
1-1 Flask VS Django 1-2 课程更新维护说明: 1-3 环境.开发环境与Flask: 1.3.1 关注版本更新说明: 1-4 初始化项目:
- Python-S9-Day115——Flask Web框架基础
01 今日内容概要 02 内容回顾 03 Flask框架:配置文件导入原理 04 Flask框架:配置文件使用 05 Flask框架:路由系统 06 Flask框架:请求和响应相关 07 示例:学生管 ...
- Python Flask高级编程之RESTFul API前后端分离精讲 (网盘免费分享)
Python Flask高级编程之RESTFul API前后端分离精讲 (免费分享) 点击链接或搜索QQ号直接加群获取其它资料: 链接:https://pan.baidu.com/s/12eKrJK ...
- Flask - 上下文管理(核心)
参考 http://flask.pocoo.org/docs/1.0/advanced_foreword/#thread-locals-in-flask https://zhuanlan.zhihu. ...
- day92:flask:flask简介&基本运行&路由&HTTP请求和响应
目录 1.Flask简介 2.关于使用flask之前的准备 3.flask的基本运行 4.flask加载配置 5.传递路由参数(没有限定类型) 6.传递路由参数(通过路由转换器限定路由参数的类型) 7 ...
- python flask框架详解
Flask是一个Python编写的Web 微框架,让我们可以使用Python语言快速实现一个网站或Web服务.本文参考自Flask官方文档, 英文不好的同学也可以参考中文文档 1.安装flask pi ...
随机推荐
- HTML5 学习01——浏览器问题、新元素
Internet Explorer 浏览器问题 问题:Internet Explorer 8 及更早 IE 版本的浏览器不支持HTML5的方式. <!--[if lt IE 9]> < ...
- 100本Python精品书籍(附pdf电子书下载)
51本Python精品书籍(附下载)链接: https://pan.baidu.com/s/19ydAKCFxM0plkepXMlqQLg 提取码: nnpe 400集python视频教程下载:链接: ...
- SpringBoot项目接口第一次访问慢的问题
SpringBoot的接口第一次访问都很慢,通过日志可以发现,dispatcherServlet不是一开始就加载的,有访问才开始加载的,即懒加载. 2019-01-25 15:23:46.264 IN ...
- 如何在 PhpStorm 使用 Code Generation?
實務上開發專案時,有一些程式碼會不斷的出現,這時可靠 PhpStorm 的 Code Generation 幫我們產生這些 code snippet,除此之外,我們也可以將自己的 code snipp ...
- Hadoop+HBase 集群搭建
Hadoop+HBase 集群搭建 1. 环境准备 说明:本次集群搭建使用系统版本Centos 7.5 ,软件版本 V3.1.1. 1.1 配置说明 本次集群搭建共三台机器,具体说明下: 主机名 IP ...
- 机器学习中Batch Size、Iteration和Epoch的概念
Batch Size:批尺寸.机器学习中参数更新的方法有三种: (1)Batch Gradient Descent,批梯度下降,遍历全部数据集计算一次损失函数,进行一次参数更新,这样得到的方向能够更加 ...
- 数组去重Demo引出的思考
package com.pers.Stream; import java.util.*; import java.util.stream.Collectors; import java.util.st ...
- 【原创 Hadoop&Spark 动手实践 7】Spark 计算引擎剖析与动手实践
[原创 Hadoop&Spark 动手实践 7]Spark计算引擎剖析与动手实践 目标: 1. 理解Spark计算引擎的理论知识 2. 动手实践更深入的理解Spark计算引擎的细节 3. 通过 ...
- jquery.cookie.js写入的值没有定义
这个是插件的基本语法,你写的没错,错就错在你肯定是在本地测试的,cookie是基于域名来储存的.意思您要放到测试服务器上或者本地localhost服务器上才会生效.cookie具有不同域名下储存不可共 ...
- lua中table的遍历,以及删除
Lua 内table遍历 在lua中有4种方式遍历一个table,当然,从本质上来说其实都一样,只是形式不同,这四种方式分别是: 1. ipairs for index, value in ipair ...