Spark记录-Spark on Yarn框架
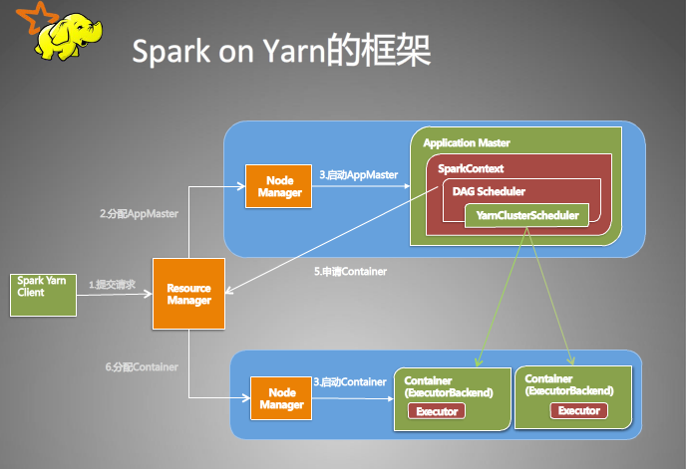
一、客户端进行操作
1、根据yarnConf来初始化yarnClient,并启动yarnClient
2、创建客户端Application,并获取Application的ID,进一步判断集群中的资源是否满足executor和ApplicationMaster申请的资源,如果不满足则抛出IllegalArgumentException;
3、设置资源、环境变量:其中包括了设置Application的Staging目录、准备本地资源(jar文件、log4j.properties)、设置Application其中的环境变量、创建Container启动的Context等;
4、设置Application提交的Context,包括设置应用的名字、队列、AM的申请的Container、标记该作业的类型为Spark;
5、申请Memory,并最终通过yarnClient.submitApplication向ResourceManager提交该Application。
当作业提交到YARN上之后,客户端就没事了,甚至在终端关掉那个进程也没事,因为整个作业运行在YARN集群上进行,运行的结果将会保存到HDFS或者日志中。
二、提交到YARN集群,YARN操作
1、运行ApplicationMaster的run方法;
2、设置好相关的环境变量。
3、创建amClient,并启动;
4、在Spark UI启动之前设置Spark UI的AmIpFilter;
5、在startUserClass函数专门启动了一个线程(名称为Driver的线程)来启动用户提交的Application,也就是启动了Driver。在Driver中将会初始化SparkContext;
6、等待SparkContext初始化完成,最多等待spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超过了配置的,程序将会退出;否则用SparkContext初始化yarnAllocator;
7、当SparkContext、Driver初始化完成的时候,通过amClient向ResourceManager注册ApplicationMaster
8、分配并启动Executeors。在启动Executeors之前,先要通过yarnAllocator获取到numExecutors个Container,然后在Container中启动Executeors。那么这个Application将失败,将Application Status标明为FAILED,并将关闭SparkContext。其实,启动Executeors是通过ExecutorRunnable实现的,而ExecutorRunnable内部是启动CoarseGrainedExecutorBackend的。
9、最后,Task将在CoarseGrainedExecutorBackend里面运行,然后运行状况会通过Akka通知CoarseGrainedScheduler,直到作业运行完成。
三、Spark on Yarn配置参数
1. spark.yarn.applicationMaster.waitTries 5
用于applicationMaster等待Spark master的次数以及SparkContext初始化尝试的次数 (一般不用设置)
2.spark.yarn.am.waitTime 100s
3.spark.yarn.submit.file.replication 3
应用程序上载到HDFS的复制份数
4.spark.preserve.staging.files false
设置为true,在job结束后,将stage相关的文件保留而不是删除。 (一般无需保留,设置成false)
5.spark.yarn.scheduler.heartbeat.interal-ms 5000
Spark application master给YARN ResourceManager 发送心跳的时间间隔(ms)
6.spark.yarn.executor.memoryOverhead 1000
此为vm的开销(根据实际情况调整)
7.spark.shuffle.consolidateFiles true
仅适用于HashShuffleMananger的实现,同样是为了解决生成过多文件的问题,采用的方式是在不同批次运行的Map任务之间重用Shuffle输出文件,也就是说合并的是不同批次的Map任务的输出数据,但是每个Map任务所需要的文件还是取决于Reduce分区的数量,因此,它并不减少同时打开的输出文件的数量,因此对内存使用量的减少并没有帮助。只是HashShuffleManager里的一个折中的解决方案。
8.spark.serializer org.apache.spark.serializer.KryoSerializer
暂时只支持Java serializer和KryoSerializer序列化方式
9.spark.kryoserializer.buffer.max 128m
允许的最大大小的序列化值。
10.spark.storage.memoryFraction 0.3
用来调整cache所占用的内存大小。默认为0.6。如果频繁发生Full GC,可以考虑降低这个比值,这样RDD Cache可用的内存空间减少(剩下的部分Cache数据就需要通过Disk Store写到磁盘上了),会带来一定的性能损失,但是腾出更多的内存空间用于执行任务,减少Full GC发生的次数,反而可能改善程序运行的整体性能。
11.spark.sql.shuffle.partitions 800
一个partition对应着一个task,如果数据量过大,可以调整次参数来减少每个task所需消耗的内存.
12.spark.sql.autoBroadcastJoinThreshold -1
当处理join查询时广播到每个worker的表的最大字节数,当设置为-1广播功能将失效。
13.spark.speculation false
如果设置成true,倘若有一个或多个task执行相当缓慢,就会被重启执行。(事实证明,这种做法会造成hdfs中临时文件的丢失,报找不到文件的错)
14.spark.shuffle.manager tungsten-sort
tungsten-sort是一种类似于sort的shuffle方式,shuffle data还有其他两种方式 sort、hash. (不过官网说 tungsten-sort 应用于spark 1.5版本以上)
15.spark.sql.codegen true
Spark SQL在每次执行次,先把SQL查询编译JAVA字节码。针对执行时间长的SQL查询或频繁执行的SQL查询,此配置能加快查询速度,因为它产生特殊的字节码去执行。但是针对很短的查询,可能会增加开销,因为它必须先编译每一个查询
16.spark.shuffle.spill false
如果设置成true,将会把spill的数据存入磁盘
17.spark.shuffle.consolidateFiles true
我们都知道shuffle默认情况下的文件数据为map tasks * reduce tasks,通过设置其为true,可以使spark合并shuffle的中间文件为reduce的tasks数目。
18.代码中 如果filter过滤后 会有很多空的任务或小文件产生,这时我们使用coalesce或repartition去减少RDD中partition数量。
Spark记录-Spark on Yarn框架的更多相关文章
- Spark记录-Spark On YARN内存分配(转载)
Spark On YARN内存分配(转载) 说明 按照Spark应用程序中的driver分布方式不同,Spark on YARN有两种模式: yarn-client模式.yarn-cluster模式. ...
- Spark记录-spark介绍
Apache Spark是一个集群计算设计的快速计算.它是建立在Hadoop MapReduce之上,它扩展了 MapReduce 模式,有效地使用更多类型的计算,其中包括交互式查询和流处理.这是一个 ...
- Spark记录-Spark性能优化解决方案
Spark性能优化的10大问题及其解决方案 问题1:reduce task数目不合适解决方式:需根据实际情况调节默认配置,调整方式是修改参数spark.default.parallelism.通常,r ...
- Spark记录-spark编程介绍
Spark核心编程 Spark 核心是整个项目的基础.它提供了分布式任务调度,调度和基本的 I/O 功能.Spark 使用一种称为RDD(弹性分布式数据集)一个专门的基础数据结构,是整个机器分区数据的 ...
- Spark记录-Spark性能优化(开发、资源、数据、shuffle)
开发调优篇 原则一:避免创建重复的RDD 通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD:接着对这个RDD执行某个算子操作,然后得到 ...
- Spark记录-spark与storm比对与选型(转载)
大数据实时处理平台市场上产品众多,本文着重讨论spark与storm的比对,最后结合适用场景进行选型. 一.spark与storm的比较 比较点 Storm Spark Streaming 实时计算模 ...
- Spark记录-Spark on mesos配置
1.安装mesos #用centos6的源yum安装 # rpm -Uvh http://repos.mesosphere.io/el/6/noarch/RPMS/mesosphere-el-repo ...
- Spark记录-spark报错Unable to load native-hadoop library for your platform
解决方案一: #cp $HADOOP_HOME/lib/native/libhadoop.so $JAVA_HOME/jre/lib/amd64 #源码编译snappy---./configure ...
- Spark记录-Spark作业调试
在本地IDE里直接运行spark程序操作远程集群 一般运行spark作业的方式有两种: 本机调试,通过设置master为local模式运行spark作业,这种方式一般用于调试,不用连接远程集群. 集群 ...
随机推荐
- Quartz学习(转)
Quartz, 是一个企业级调度工作的框架,帮助Java应用程序到调度工作/任务在指定的日期和时间运行. 一.在Java工程中使用Quartz 1.导入jar包 com.springsource.or ...
- Linux养成笔记
教程来自慕课网@Tony老师的课程 Linux简介 Linux发展史 Andrew S. Tanenbaum为了给学生讲课,买了一个Unix操作系统,参考他开发了Minix,并开放代码作为大学研究,2 ...
- org.springframework.beans.factory.parsing.BeanDefinitionParsingException: Configuration problem: Unexpected failure during bean definition parsing Offending resource: class path resource [applicationC
这个错误是 org.springframework.beans.factory.parsing.BeanDefinitionParsingException: Configuration proble ...
- mybatis集成redis
系统原生集成的Ehcache, 但是监控需要(version 2.7),Ehcache Monitor http://www.ehcache.org/documentation/2.7/operati ...
- jQuery中empty与html("")的区别对比
简单的说empty,首先循环给后代元素移除绑定(释放内存).清除jquery给此dom的cache,然后循环removeFirstChild,而html(''),则是简单暴力的设置innerHTML ...
- Delphi/XE2 使用TIdHttp控件下载Https协议服务器文件[转]
之前的一篇博文详细描述了使用TIdhttp控件下载http协议的文件,在我项目的使用过程中发现对于下载Https协议中的文件与Http协议的文件不同,毕竟Https在HTTP协议基础上增加了SSL协议 ...
- BZOJ1926[Sdoi2010]粟粟的书架——二分答案+主席树
题目描述 幸福幼儿园 B29 班的粟粟是一个聪明机灵.乖巧可爱的小朋友,她的爱好是画画和读书,尤其喜欢 Thomas H. Co rmen 的文章.粟粟家中有一个 R行C 列的巨型书架,书架的每一个位 ...
- [hgoi#2019/3/3]赛后总结
T1--最长公共前缀(lcp) 定义两个字符串S,T 的最长公共前缀lcp(S,T)为最长的字符串R,满足R 既是S 的前缀又是T 的前缀. 给定一个字符串S,下标从1 开始,每次询问给出四个正整数a ...
- 【转】__int64 与long long 的区别
//为了和DSP兼容,TSint64和TUint64设置成TSint40和TUint40一样的数 //结果VC中还是认为是32位的,显然不合适 //typedef signed long int ...
- Raid卷详解
#RAID卷 独立磁盘冗余阵列RAID是一种把多块独立的硬盘(物理硬盘)按不同的方式组合起来形成一个硬盘组(逻辑硬盘),从而提供比单个硬盘更高的存储性能和提供数据备份技术.组成磁盘阵列的不同方式成为R ...