ElasticSearch权威指南学习(分布式集群)
空集群
- 只有一个空节点的集群
- 一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,它们具有相同的cluster.name,它们协同工作,分享数据和负载。当加入新的节点或者删除一个节点时,集群就会感知到并平衡数据。
- 集群中一个节点会被选举为主节点(master),它将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。任何节点都可以成为主节点。我们例子中的集群只有一个节点,所以它会充当主节点的角色。
- 做为用户,我们能够与集群中的任何节点通信,包括主节点。每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上。我们访问的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch处理。
集群健康
- 集群健康有三种状态:green、yellow或red
GET /_cluster/health
{
"cluster_name": "elasticsearch",
"status": "green", //状态
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
| 颜色 | 意义 |
|---|---|
| green | 所有主要分片和复制分片都可用 |
| yellow | 所有主要分片可用,但不是所有复制分片都可用 |
| red | 不是所有的主要分片都可用 |
添加索引
- 为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”。
- 一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。一个分片就是一个Lucene实例
- 您可以在集群节点上保存的分片数量与您可用的堆内存大小成正比,但这在Elasticsearch中没有的固定限制。 一个很好的经验法则是:确保每个节点的分片数量保持在低于每1GB堆内存对应集群的分片在20-25之间。 因此,具有30GB堆内存的节点最多可以有600-750个分片,但是进一步低于此限制,您可以保持更好。 这通常会帮助群体保持处于健康状态。
- 分片大小为50GB通常被界定为适用于各种用例的限制
- 为了演示的目的,我们只分配3个主分片和一个复制分片(每个主分片都有一个复制分片)
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
{
"cluster_name": "elasticsearch",
"status": "yellow", //状态
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3 <2>
}

- 状态为yelloww,因为只有主节点,复制节点没有被分配
增加故障转移
- 在单一节点上运行意味着有单点故障的风险——没有数据备份。幸运的是,要防止单点故障,我们唯一需要做的就是启动另一个节点
- 只要第二个节点与第一个节点有相同的cluster.name(请看./config/elasticsearch.yml文件),它就能自动发现并加入第一个节点所在的集群
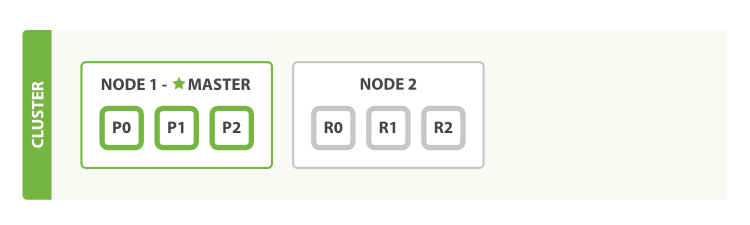
横向扩展
- 如果我们启动第三个节点,我们的集群会重新组织自己
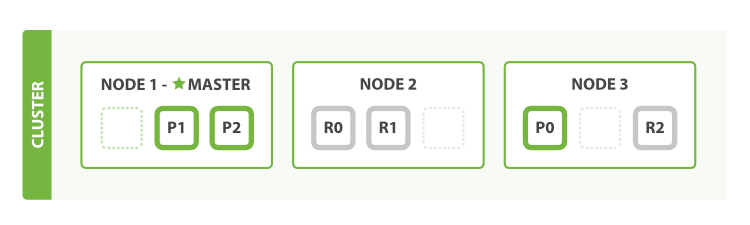
继续扩展
- 主分片的数量在创建索引时已经确定。实际上,这个数量定义了能存储到索引里数据的最大数量(实际的数量取决于你的数据、硬件和应用场景)。然而,主分片或者复制分片都可以处理读请求——搜索或文档检索,所以数据的冗余越多,我们能处理的搜索吞吐量就越大。
- 复制分片的数量从原来的1增加到2
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
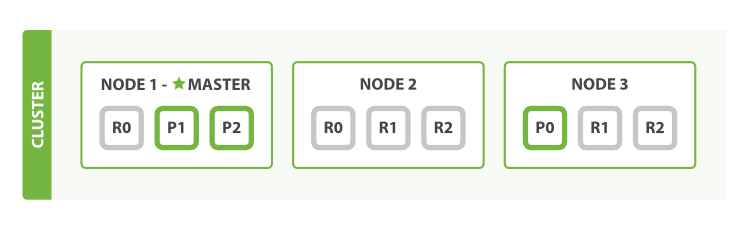
3. 这样使我们的搜索性能相比原始的三节点集群增加三倍
4. 在同样数量的节点上增加更多的复制分片并不能提高性能,因为这样做的话平均每个分片的所占有的硬件资源就减少了
5. 不过这些额外的复制节点使我们有更多的冗余:通过以上对节点的设置,我们能够承受两个节点故障而不丢失数据
应对故障(3个主分片,6个副本节点)
- 杀掉第一个节点的进程
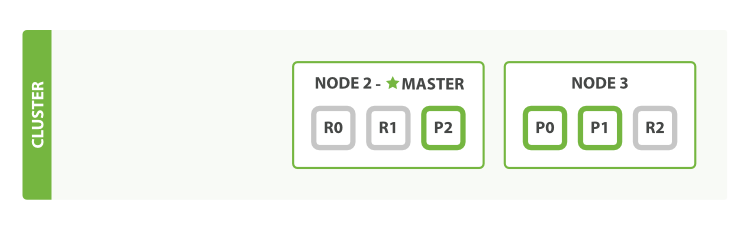
- 我们杀掉的节点是一个主节点。一个集群必须要有一个主节点才能使其功能正常,所以集群做的第一件事就是各节点选举了一个新的主节点:Node 2。
- 主分片1和2在我们杀掉Node 1时已经丢失,我们的索引在丢失主分片时不能正常工作。如果此时我们检查集群健康,我们将看到状态red:不是所有主分片都可用!
- 但丢失的两个主分片的完整拷贝存在于其他节点上,所以新主节点做的第一件事是把这些在Node 2和Node 3上的复制分片升级为主分片,这时集群健康回到yellow状态。这个提升是瞬间完成的,就好像按了一下开关。
- 当我们杀掉Node 2,我们的程序依然可以在没有丢失数据的情况下继续运行,因为Node 3还有每个分片的拷贝。
- 如果我们重启Node 1,集群将能够重新分配丢失的复制分片
ElasticSearch权威指南学习(分布式集群)的更多相关文章
- ElasticSearch权威指南学习(分布式文档存储)
路由文档到分片 当你索引一个文档,它被存储在单独一个主分片上.Elasticsearch是如何知道文档属于哪个分片的呢?当你创建一个新文档,它是如何知道是应该存储在分片1还是分片2上的呢? 进程不能是 ...
- mac 下搭建Elasticsearch 5.4.3分布式集群
一.集群角色 多机集群中的节点可以分为master nodes和data nodes,在配置文件中使用Zen发现(Zen discovery)机制来管理不同节点.Zen发现是ES自带的默认发现机制,使 ...
- ElasticSearch权威指南学习(分布式搜索)
查询阶段 在初始化查询阶段(query phase),查询被向索引中的每个分片副本(原本或副本)广播. 每个分片在本地执行搜索并且建立了匹配document的优先队列(priority queue). ...
- ElasticSearch权威指南学习(索引管理)
创建索引 当我们需要确保索引被创建在适当数量的分片上,在索引数据之前设置好分析器和类型映射. 手动创建索引,在请求中加入所有设置和类型映射,如下所示: PUT /my_index { "se ...
- ElasticSearch权威指南学习(排序)
排序方式 相关性排序 默认情况下,结果集会按照相关性进行排序 -- 相关性越高,排名越靠前. 相关性分值会用_score字段来给出一个浮点型的数值,所以默认情况下,结果集以_score进行倒序排列. ...
- ElasticSearch权威指南学习(结构化查询)
请求体查询 简单查询语句(lite)是一种有效的命令行adhoc查询.但是,如果你想要善用搜索,你必须使用请求体查询(request body search)API. 空查询 我们以最简单的 sear ...
- ElasticSearch权威指南学习(映射和分析)
概念 映射(mapping)机制用于进行字段类型确认,将每个字段匹配为一种确定的数据类型(string, number, booleans, date等).+ 分析(analysis)机制用于进行全文 ...
- ElasticSearch权威指南学习(文档)
什么是文档 在Elasticsearch中,文档(document)这个术语有着特殊含义.它特指最顶层结构或者根对象(root object)序列化成的JSON数据(以唯一ID标识并存储于Elasti ...
- mongodb的分布式集群(4、分片和副本集的结合)
概述 前面3篇博客讲了mongodb的分布式和集群,当中第一种的主从复制我们差点儿不用,没有什么意义,剩下的两种,我们不论单独的使用哪一个.都会出现对应的问题.比較好的一种解决方式就是.分片和副本集的 ...
随机推荐
- Mybaits
1.Mybatis全注解形式 (在注解上不能直接使用动态Sql,必须要在前后面加上<script>SQL</script>标签,否则会报错): @Select("& ...
- week07 13.2 NewsPipeline之 二 News Fetcher - Xpath
我们使用Xpath来专门做一个scrapter 我们专门弄个文件夹 里面全部是 各个新闻源(CNN BBC等)的scraper来抓取网站的text内容 主要函数(就是传入text内容的那个url)然后 ...
- html 提取 公用部分
在写HTML时,总会遇到一些公用部分,如果每个页面都写那就很麻烦,并且代码量大大增加. 网上查询了几种方法: 1.es6 的 embed 标签. <embed src="header. ...
- iosApp上传app遇到的问题
昨天上传了两个app,是由原来的app改版之后产生了新的app上传的,出现了几个问题现在记录一下. 1.证书配置问题:报错如下 解决办法:选择一个team即可.选择完team之后还是报错: 解决方法: ...
- mysql_day02
MySQL-Day01回顾1.MySQL的特点 1.关系型数据库 2.跨平台 3.支持多种编程语言2.MySQL的启动和连接 1.服务端启动 sudo /etc/init.d/mysql start| ...
- mysql数据库字段内容替换
UPDATE 表名 SET 字段名= replace(字段名, '查找内容', '替换成内容') ; UPDATE car_articles SET article_title = replace(a ...
- 业务数据实体(model) 需要克隆的方法
业务数据实体(model) 需要克隆的时候 可以使用 Json.Deserialize<InquireResult>(Json.Serialize<InquireResult> ...
- TZOJ 4244 Sum(单调栈区间极差)
描述 Given a sequence, we define the seqence's value equals the difference between the largest element ...
- 322. Coin Change选取最少的硬币凑整-背包问题变形
[抄题]: You are given coins of different denominations and a total amount of money amount. Write a fun ...
- 微擎开发------day01
微擎的数据常量 $_GPC -- 全局请求变量 类型: array 说明: 合并请求参数, 包括 $_GET, $_POST, $_COOKIE的内容. 相同键名覆盖规则为 $_COOKIE 覆盖 ...