1、Kafka介绍
1、Kafka介绍
1)在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
2)Kafka是一个分布式消息队列。
3)Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer。
此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
2、消息队列内部实现原理
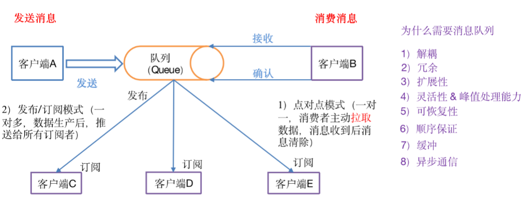
1)点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,这种模型从队列中请求信息,而不是将消息推送到客户端。
这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。
2)发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。
发布订阅模型可以有多种不同的订阅者,
临时订阅者只在主动监听主题时才接收消息,而
持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
3、消息队列的作用
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。
许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3)扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。
如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。
使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。
消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。
大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。
(Kafka保证一个Partition内的消息的有序性)
7)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8)异步通信:
很多时候,用户不想也不需要立即处理消息。
消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。
想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
1、Kafka介绍的更多相关文章
- Apache Kafka - 介绍
原文地址地址: http://blogxinxiucan.sh1.newtouch.com/2017/07/12/Apache-Kafka-介绍/ Apache Kafka教程 之 Apache Ka ...
- [转]kafka介绍
转自 https://www.cnblogs.com/hei12138/p/7805475.html kafka介绍 1.1. 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台 ...
- Kafka介绍及安装部署
本节内容: 消息中间件 消息中间件特点 消息中间件的传递模型 Kafka介绍 安装部署Kafka集群 安装Yahoo kafka manager kafka-manager添加kafka cluste ...
- kafka介绍与搭建(单机版)
一.kafka介绍 1.1 主要功能 根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能: 1:It lets you publish and subscribe to ...
- kafka介绍及安装配置(windows)
Kafka介绍 Kafka是分布式的发布—订阅消息系统.它最初由LinkedIn(领英)公司发布,使用Scala和Java语言编写,与2010年12月份开源,成为Apache的顶级项目.Kafka是一 ...
- 一、kafka 介绍 && kafka-client
一.kafka 介绍 1.1.kafka 介绍 Kafka 是一个分布式消息引擎与流处理平台,经常用做企业的消息总线.实时数据管道,有的还把它当做存储系统来使用. 早期 Kafka 的定位是一个高吞吐 ...
- 3 kafka介绍
本博文的主要内容有 .kafka的官网介绍 http://kafka.apache.org/ 来,用官网上的教程,快速入门. http://kafka.apache.org/documentatio ...
- Kafka介绍
本文介绍LinkedIn开源的Kafka,久仰大名了,依照其官方文档做些翻译和二次创作.相应能够查看整份官方文档. 基本术语 topics,维护的消息源种类(更像是业务上的数据种类/分类) produ ...
- 漫游Kafka介绍章节简介
原文地址:http://blog.csdn.net/honglei915/article/details/37564521 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息 ...
随机推荐
- 半深入理解CSS3 object-position/object-fit属性
半深入理解CSS3 object-position/object-fit属性 转载:https://www.zhangxinxu.com/wordpress/2015/03/css3-object-p ...
- WordCount扩展
码云地址:https://gitee.com/xjtsh/ExpandedWordCount 功能实现: wc.exe -c file.c //返回文件 file.c 的字符数 wc.exe ...
- How to enable Linux-PAM on uClinux
By default the uClinux uses the tools provided by busybox firstly. So the init login and passwd are ...
- mongodb 3.2 分片 + 副本集
从图中可以看到有四个组件:mongos.config server.shard.replica set. mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加 ...
- SpringMVC(四):什么是HandlerAdapter
一.什么是HandlerAdapter Note that a handler can be of type Object. This is to enable handlers from other ...
- 线程 学习教程(一): Java中终止(销毁)线程的方法
结束线程有以下三种方法:(1)设置退出标志,使线程正常退出,也就是当run()方法完成后线程终止 (2)使用interrupt()方法中断线程 (3)使用stop方法强行终止线程(不推荐使用,Thre ...
- Python加密保护解决方案
防止代码反编译,高强度加密保护exe或pyc文件 产品简介 Python语言写的程序无需编译成二进制文件代码,可以直接从源代码运行程序.在计算机内部,Python解释器把源代码转换成字节码的中间形式, ...
- Redis入门到高可用(十六)—— 持久化
一.持久化概念 二.持久化方式 三.redis持久化方式之——RDB 1.什么是RDB 在 Redis 运行时, RDB 程序将当前内存中的数据库快照保存到磁盘文件中, 在 Redis 重启动时, R ...
- ORACLE——NVL()、NVL2() 函数的用法
NVL和NVL2两个函数虽然不经常用,但是偶尔也会用到,所以了解一下. 语法: --如果表达式1为空则显示表达式2的值,如果表达式1不为空,则显示表达式1的值 NVL(表达式1,表达式2); --如果 ...
- 【UML】NO.53.EBook.5.UML.1.013-【UML 大战需求分析】- 组合结构图(Composition Structure Diagram)
1.0.0 Summary Tittle:[UML]NO.52.EBook.1.UML.1.012-[UML 大战需求分析]- 交互概览图(Interaction Overview Diagram) ...