Pandas 基础(12) - Stack 和 Unstack
这节的主题是 stack 和 unstack, 我目前还不知道专业领域是怎么翻译的, 我自己理解的意思就是"组成堆"和"解除堆". 其实, 也是对数据格式的一种转变方式, 单从字面上可能比较难理解, 所以给大家下面两张图来理解一下:

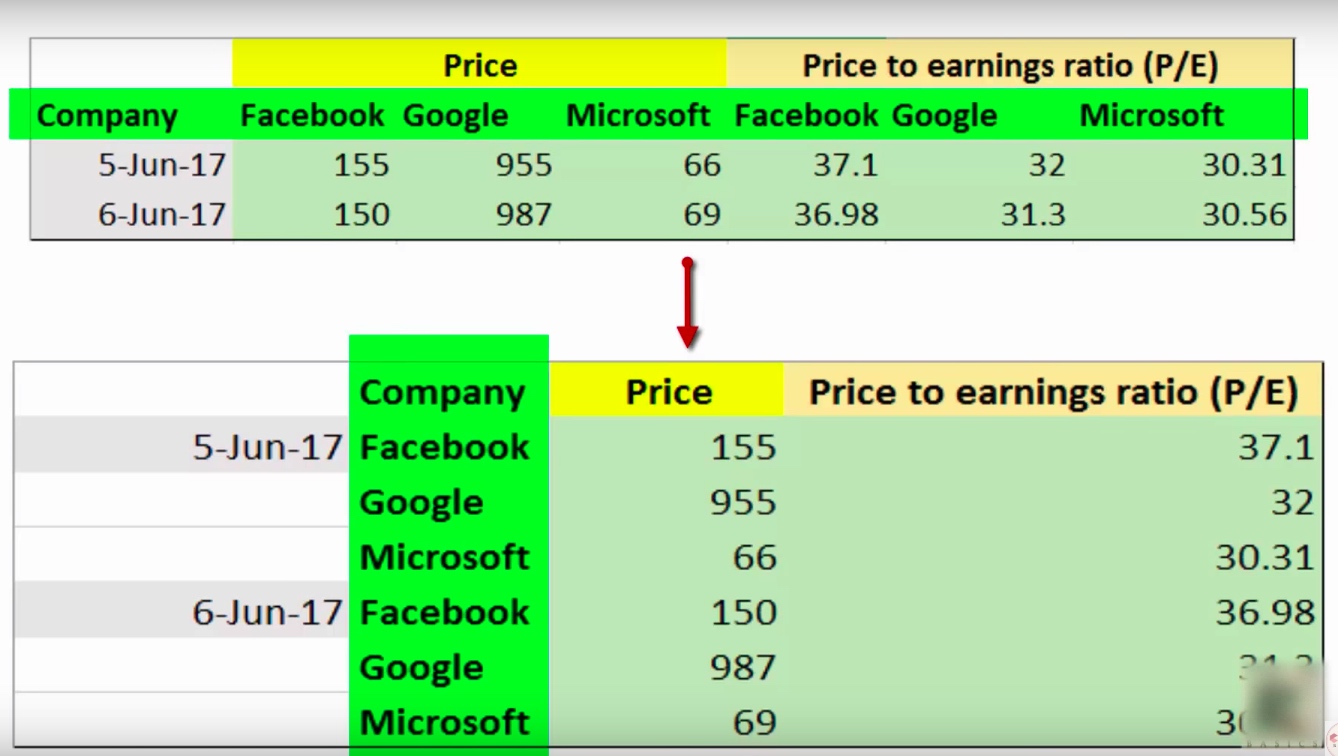
上图中, 标绿色的部分, 代表一个对应关系, 就是列的级别转为行级别.
下面来看下具体实现. 首先引入文件, 通过原表, 我们可以看到有两行表头, 所以这里要多加个参数 header=[0,1]:
df = pd.read_excel('/Users/rachel/Sites/pandas/py/pandas/12_stack/stocks.xlsx', header=[0,1])
输出:
用 stack() 方法改变一下格式, 看会是什么效果:
df_stacked = df.stack()
df_stacked
从输出可以看到, 原来的数据结构是有两行表头, 经过 stack 之后, 就变成一行了, 也就是 Facebook Google Microsoft 这一行, 从原来的列名, 变成了索引: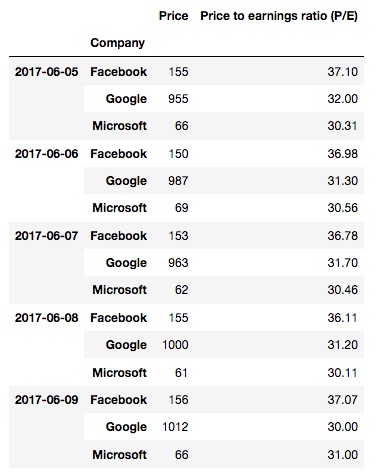
那我们现在再 unstack 看看:
df_stacked.unstack()
输出:
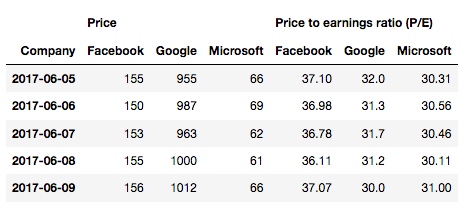
发现, unstack 之后, 整个数据结构又变回去了.
那我们现在再来重新 stack 一下, 并且加个参数 level=0, 也就是将第一行的表头堆叠成索引列:
df.stack(level=0)
输出: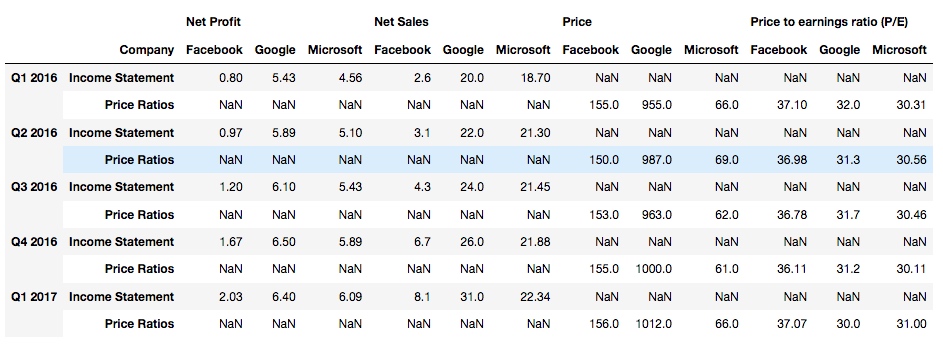
下面再来看一个更复杂点的例子, 这个表格中有三行表头:
df2 = pd.read_excel('/Users/rachel/Sites/pandas/py/pandas/12_stack/stocks_3_levels.xlsx', header=[0,1,2])
输出:
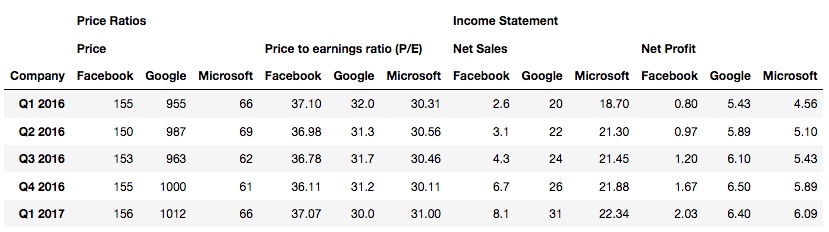
首先 stack 一下:
df2.stack()
输出, 我们看到最下面一行表头被堆叠到索引列了: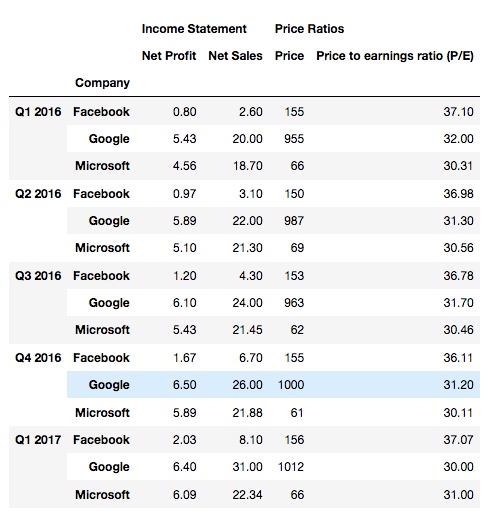
再试一下将 level 参数设为 0:
df2.stack(level=0)
发现, 第一行表头被 stack 了: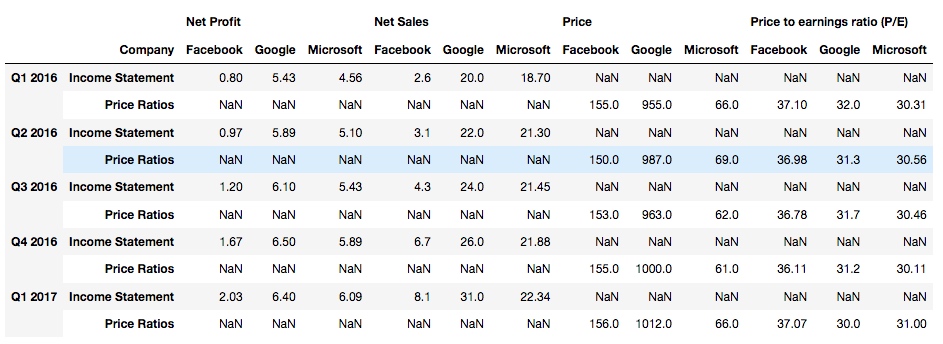
再设置 level=1:
df2.stack(level=1)
输出, 这次是第二行表头被 stack 了: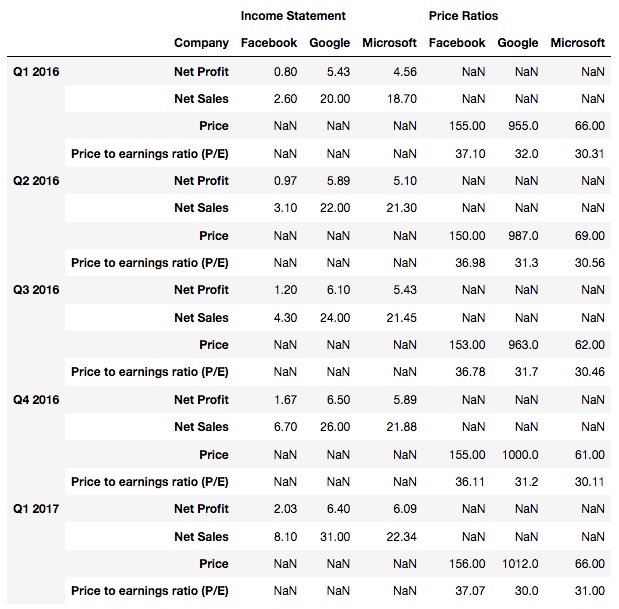
再试下设置 level=2:
df2.stack(level=2)
输出, 发现是第三行表头被 stack 了: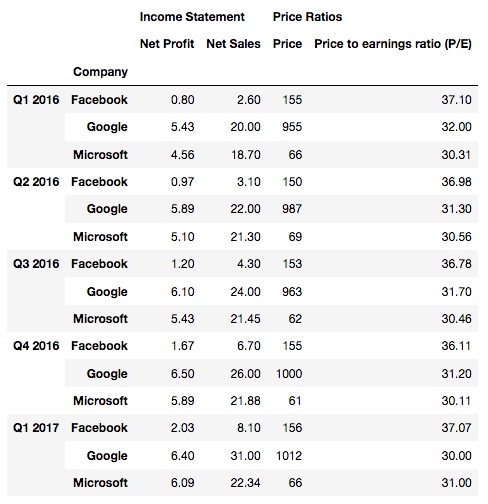
综上, 可以总结, stack 的作用就是可以将横向的表头(列名)转成纵向的索引列展示, 对于多行表头而言, 具体要转换哪一行取决于 level 参数, 如果不指定, 则默认转换最下面一行表头.
以上, 就是关于 stack 和 unstack 的基本操作了, enjoy!~~~
Pandas 基础(12) - Stack 和 Unstack的更多相关文章
- 数据重塑图解—Pivot, Pivot-Table, Stack and Unstack
Pivot pivot函数用于创建一个新的派生表,该函数有三个参数:index, columns和values.你需要在原始表中指定这三个参数所对定的列名,接下来pivot函数会创建一个新的表格,其中 ...
- python pandas stack和unstack函数
在用pandas进行数据重排时,经常用到stack和unstack两个函数.stack的意思是堆叠,堆积,unstack即"不要堆叠",我对两个函数是这样理解和区分的. 常见的数据 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- pandas 基础操作 更新
创建一个Series,同时让pandas自动生成索引列 创建一个DataFrame数据框 查看数据 数据的简单统计 数据的排序 选择数据(类似于数据库中sql语句) 另外可以使用标签来选择 通过位置获 ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- [.net 面向对象编程基础] (12) 面向对象三大特性——继承
[.net 面向对象编程基础] (12) 面向对象三大特性——继承 上节我们说了面向对象的三大特性之一的封装,解决了将对同一对象所能操作的所有信息放在一起,实现统一对外调用,实现了同一对象的复用,降低 ...
随机推荐
- Python学习之旅(二十二)
Python基础知识(21):IO编程 一.文件读写 读写文件就是请求操作系统打开一个文件对象(文件描述符),然后,通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象 ...
- Codeforces 1062 - A/B/C/D/E - (Undone)
链接:http://codeforces.com/contest/1062 A - Prank - [二分] 题意: 给出长度为 $n(1 \le n \le 100)$ 的数组 $a[1 \sim ...
- 深入理解Spring AOP之二代理对象生成
深入理解Spring AOP之二代理对象生成 spring代理对象 上一篇博客中讲到了Spring的一些基本概念和初步讲了实现方法,当中提到了动态代理技术,包含JDK动态代理技术和Cglib动态代理 ...
- C++——创建类的时候用new与不用new 的区别(转)
C++在创建对象的时候可以采用两种方式:(例如类名为Test) Test test 或者 Test* pTest = new Test(). 这两种方法都可以实例化一个对象,但是这两种 ...
- bugfree3.0.1-BUG解决方案修改
该篇内容来自文档“masterBugFree2.pdf”,记录在这里. 1.如何将解决方案改为中文 在\Bugfree\Lang\ZH_CN_UTF-8 \_COMMON.php 文件中做如下修改/* ...
- (Detected problems with API compatibility(visit g.co/dev/appcompat for more info)
在applicaiton里面加载这么一段代码: private void closeAndroidPDialog(){ try { Class aClass = Class.forName(" ...
- 使用AMBER中遇到的一些问题
1.读取蛋白问题 读取无配体pdb文件(loadpdb complex.pdb)时,出现一堆 FATAL: Atom .R<ARG >.A<HD1 > does not hav ...
- unity UGUI UI跟随
实现2dUI跟随游戏中角色的移动(应用于玩家名称,血条,称号) using UnityEngine; public class UI_Follow : MonoBehaviour { public C ...
- protocol buffer 编码
protocol buffer能够跨平台提供轻量的序列化和反序列化,得益于其平台无关的编码格式,本文就介绍下其中的编码格式. Varints 在protocol buffer中大量使用到了Varint ...
- WebForm内置对象:Session、Cookie,登录和状态保持
1.Request -获取请求对象 string s =Request["key"]; 2.Response - 响应请求对象 Response.Redirect(" ...