Weka中数据挖掘与机器学习系列之Weka3.7和3.9不同版本共存(七)
不多说,直接上干货!
为什么,我要写此博客,原因是(以下,我是weka3.7.8)
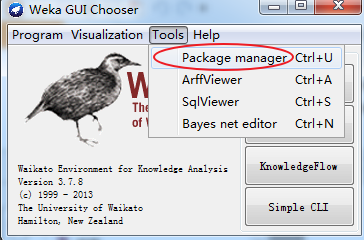
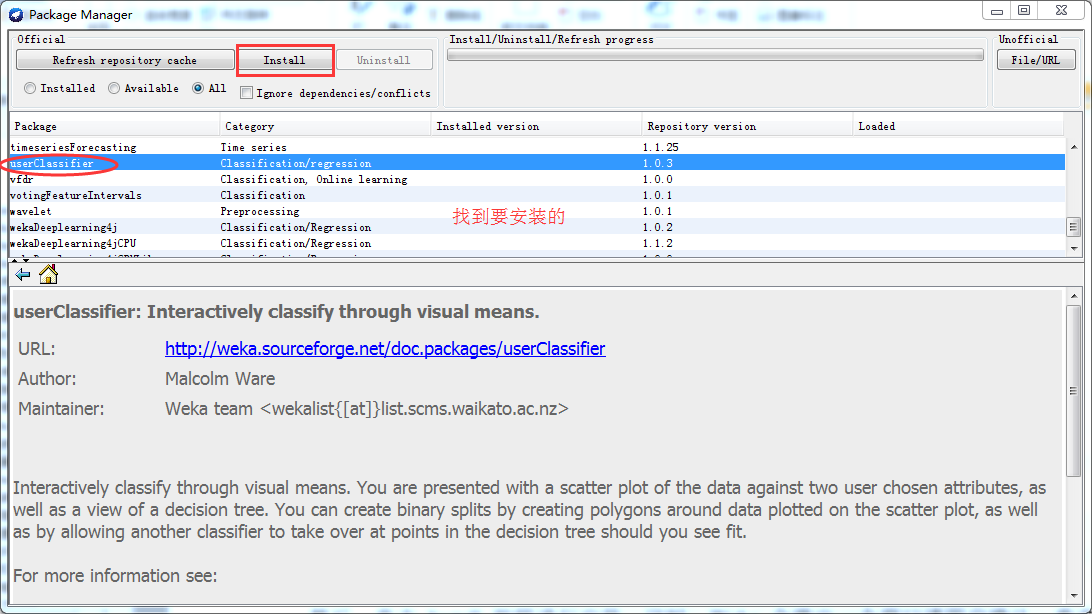
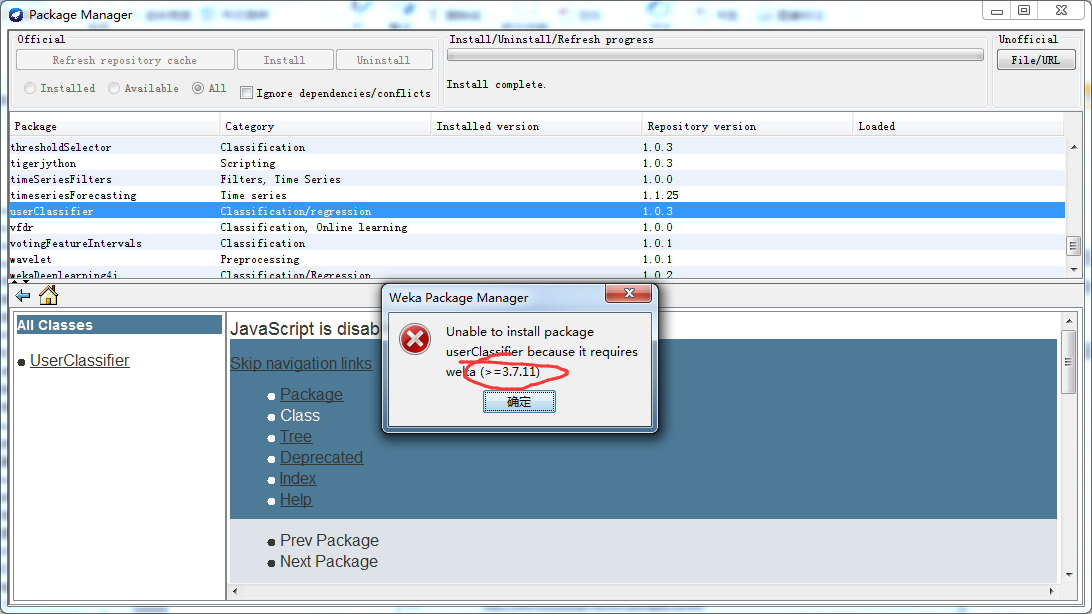
以下是,weka3.7.8的安装版本。
Weka中数据挖掘与机器学习系列之Weka系统安装(四)
基于此,我安装最新的稳定版本,weka3.9.0。下载请见
http://download.csdn.net/detail/u010106732/9842662

最后,安装下来,两个版本界面有些变化差异。
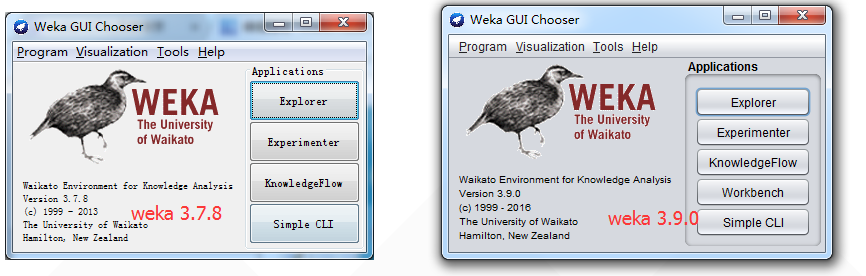
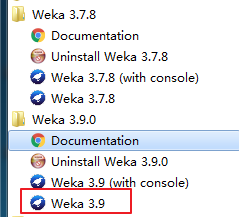

我这里,在我自己电脑里,这两款版本我都保留了。大家也可以这样去做。因为,有些资料网上,还现在很大程度上,停留在3.7,当然慢慢会有3.9的资料增加!
大家也许会有个疑问:那么在环境变量那一步,怎么共存两个不同的weka版本呢?
很简单:WEKA37_HOME=D:\SoftWare\Weka-3-7
WEKA39_HOME=D:\SoftWare\Weka-3-9
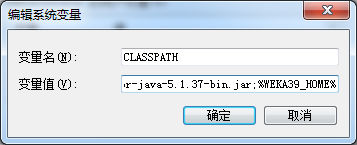
设置CLASSPATH 和 PATH
CLASSPATH环境变景告知Java应该在什么地方去查找Java类。因为Java总是按照—定顺序去查找CLASSPATH环境变景里的类路径,因此,用户应该认真考虑将何种路径放到CLASSPATH的什么位置。
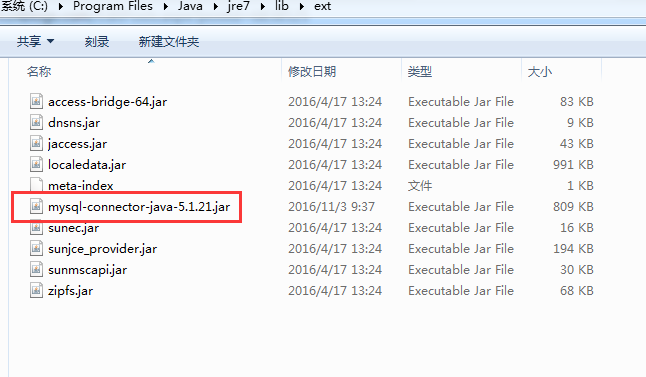
下面以Windows操作系统下添加MySQL驱动程序mysql-connector-java-5.1.21.jar为例进行说明。只有将该jar文件添加到CLASSPATH环境变量中,Weka才能通过JDBC访问MySQL数据库。
比如,我这里,就放到Weka的安装目录下,新建一个lib。

JAVA_HOME%\jre\lib\ext下,也要放置
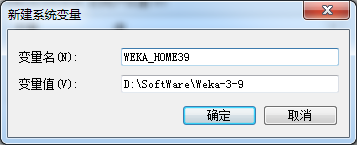
设置Weka所需的环境变量
此处环境变量的配置和JDK一样,首先新建WEKA39_HOME=D:\SoftWare\Weka-3-9
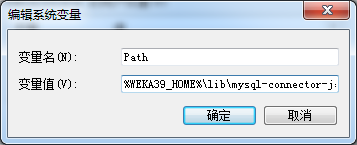
修改Path,在path的最前面加上
%WEKA39_HOME%\lib\mysql-connector-java-5.1.21-bin.jar;%JAVA_HOME%\jre\lib\ext\mysql-connector-java-5.1.21-bin.jar;
CLASSPATH: %WEKA39_HOME%\lib\mysql-connector-java-5.1.37-bin.jar
更多其他,请见
Weka中数据挖掘与机器学习系列之Weka系统安装(四)
Weka中数据挖掘与机器学习系列之Weka3.7和3.9不同版本共存(七)的更多相关文章
- Weka中数据挖掘与机器学习系列之Weka Package Manager安装所需WEKA的附加算法包出错问题解决方案总结(八)
不多说,直接上干货! Weka中数据挖掘与机器学习系列之Weka系统安装(四) Weka中数据挖掘与机器学习系列之Weka3.7和3.9不同版本共存(七) 情况1 对于在Weka里,通过Weka P ...
- Weka中数据挖掘与机器学习系列之Exploer界面(七)
不多说,直接上干货! Weka的Explorer(探索者)界面,是Weka的主要图形化用户界面,其全部功能都可通过菜单选择或表单填写进行访问.本博客将详细介绍Weka探索者界面的图形化用户界面.预处理 ...
- Weka中数据挖掘与机器学习系列之Weka系统安装(四)
能来看我这篇博客的朋友,想必大家都知道,Weka采用Java编写的,因此,具有Java“一次编译,到处运行”的特性.支持的操作系统有Windows x86.Windows x64.Mac OS X.L ...
- Weka中数据挖掘与机器学习系列之Weka简介(二)
不多说,直接上干货! Weka简介 Weka是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis)的英文字首缩写,官方网址为:http://www ...
- Weka中数据挖掘与机器学习系列之基本概念(三)
数据挖掘和机器学习 数据挖掘和机器学习这两项技术的关系非常密切.机器学习方法构成数据挖掘的核心,绝大多数数据挖掘技术都来自机器学习领域,数据挖掘又向机器学习提出新的要求和任务. 数据挖掘就是在数据中寻 ...
- Weka中数据挖掘与机器学习系列之为什么要写Weka这一系列学习笔记?(一)
本人正值科研之年,同时也在使用Weka来做相关数据挖掘和机器学习的论文工作. 为了记录自己的学习历程,也便于分享和带领入门的你们.废话不多说,直接上干货!
- Weka中数据挖掘与机器学习系列之数据格式ARFF和CSV文件格式之间的转换(五)
不多说,直接上干货! Weka介绍: Weka是一个用Java编写的数据挖掘工具,能够运行在各种平台上.它不仅提供了可以直接用于数据挖掘的软件,还提供了src代码,使用者可以修改源代码,进行二次开发. ...
- 在weka中添加libSVM或者HMM等新算法
转:http://kasy-13.blog.163.com/blog/static/8214691420143226365887/ Weka的全名是怀卡托智能分析环境(Waikato Environm ...
- [Machine Learning & Algorithm]CAML机器学习系列1:深入浅出ML之Regression家族
声明:本博客整理自博友@zhouyong计算广告与机器学习-技术共享平台,尊重原创,欢迎感兴趣的博友查看原文. 符号定义 这里定义<深入浅出ML>系列中涉及到的公式符号,如无特殊说明,符号 ...
随机推荐
- javascript位操作符右移>>>的妙用
var len=arr.length>>>0; 在arr.length为null或undefined的时间,强制转换为0;
- Ubuntu ctrl+alt会导致窗口还原的问题
Ubuntu ctrl+alt会导致窗口还原的问题 本来以为是compizConfig的问题,后来在系统config中找到键盘>快捷键:恢复窗口,删除这个快捷键,就好了: 原来这里写的是ctrl ...
- weblogic 生产模式和开发模式的互相转换
weblogic 生产模式和开发模式的互相转换 学习了:http://blog.csdn.net/qew110123/article/details/45845935 weblogic10.3生产模式 ...
- JavaScript检查手机格式是否错误
编写自己定义的JavaScript函数checkPhone(),在函数中应用正則表達式推断手机号码的格式是否正确,不对的给出提示 <script type="text/javascri ...
- nj05---模块
概念:模块(Module)和包(Package)是Node.js最重要的支柱.在浏览器JavaScript中,脚本模块的拆分和组合通常使用HTML的script标签来实现,Node.js提供了requ ...
- 熟悉了下HTTP协议
HTML是一种用来定义网页的文本,会HTML,就可以编写网页: HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信.200表示一个成功的响应,后面的OK是说明.失败的响应有404 Not ...
- 19.允许重复的unordered_map
#include <string> #include <iostream> //查询性能最高 //允许重复的,hash_map #include <unordered_m ...
- 配置ssh免密码登录的原理
- VS10的一个问题
今天遇到一个问题,LINK : fatal error LNK1123: 转换到 COFF 期间失败: 文件无效或损坏.转一下网上的解决办法http://bbs.csdn.net/topics/390 ...
- [ Java ] [ Eclipse ] content Auto activation triggers
重點: That plug-in is not necessary any more. Just go to Preferences > Java > Editor > Conten ...