How to Reuse Old PCs for Solr Search Platform?
家裡或公司的舊電腦不夠力? 效能慢到想砸爛它們? 朋友或同事有電腦要丟嗎? 我有一個廢物利用的方法, 我收集了四台舊電腦, 組了一個Fully Distributed Mode的Hadoop Cluster, 在Hadoop上架了Hbase, 執行Nutch, 儲存Solr的資料在Hbase。
PC Specs
| Name | CPU | RAM |
|---|---|---|
| pigpigpig-client2 | T2400 1.82GHz | 2GB |
| pigpigpig-client4 | E7500 2.93GHz | 4GB |
| pigpigpig-client5 | E2160 1.80GHz | 4GB |
| pigpigpig-client6 | T7300 2.00GHz | 2GB |
Roles
| Name | Roles |
|---|---|
| pigpigpig-client2 | HQuorumPeer, SecondaryNameNode, ResourceManager, Solr |
| pigpigpig-client4 | NodeManager, HRegionServer, DataNode |
| pigpigpig-client5 | NodeManager, HRegionServer, DataNode |
| pigpigpig-client6 | NameNode, HMaster, Nutch |
Version
- Hadoop 2.7.0
- Hbase 0.98.8-hadoop2
- Gora 0.6.1-SNAPSHOT (P.S. 此時此刻官網尚未正式release, 請參考Build Apache Gora With Solr 5.1.0)
- Nutch 2.4-SNAPSHOT (P.S. 此時此刻官網尚未正式release, 請參考Build Apache Nutch with Solr 5.1.0)
Configuration
剛開始執行Nutch時, 並沒有特別修改預設的設定檔, 每次經過大約10小時, RegionServer一定會發生隨機crash, 錯誤訊息大概都是Out Of Memory之類的, 我們的限制是資源有限, 舊電腦已經無法升級, 不像EC2是資源不夠就能升級, 所以performance tuning對我們是很重要的議題。
in hadoop-env.sh
記憶體很珍貴, 因為只有兩個DATANODE, 不需要預設的512MB那麼多, 全部減半
export HADOOP_NAMENODE_OPTS=“-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS -Xmx256m”
export HADOOP_DATANODE_OPTS=“-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS -Xmx256m”
export HADOOP_SECONDARYNAMENODE_OPTS=“-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:-INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_SECONDARYNAMENODE_OPTS -Xmx256m”
export HADOOP_PORTMAP_OPTS=“-Xmx256m $HADOOP_PORTMAP_OPTS”
export HADOOP_CLIENT_OPTS=“-Xmx256m $HADOOP_CLIENT_OPTS”
in hdfs-site.xml
為了避免hdfs timeout errors, 延長timeout的時間
1 |
|
in mapred-env.sh
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=256
in mapred-site.xml
CPU效能不好, node不夠多, mapred.task.timeout調高一點, 免得mapreduce來不及做完, 尤其nutch inject、generate、fetch、parse、updatedb執行幾輪之後, 每次處理的資料都幾百萬筆, timeout太低會做不完。
1 |
|
in yarn-env.sh
JAVA_HEAP_MAX=-Xmx256m
YARN_HEAPSIZE=256
in yarn-site.xml
4GB的RAM要分配給OS、NodeManager、HRegionServer和DataNode, 資源實在很緊。分派一半的記憶體給YARN, 所以yarn.nodemanager.resource.memory-mb設成2048; 每個CPU有2個core, 所以mapreduce.map.memory.mb、mapreduce.reduce.memory.mb和yarn.scheduler.maximum-allocation-mb設成1024。yarn.nodemanager.vmem-pmem-ratio設高一點避免出現類似 “running beyond virtual memory limits. Killing container"之類的錯誤。
1 |
|
in hbase-env.sh
# export HBASE_HEAPSIZE=1000
export HBASE_MASTER_OPTS=“$HBASE_MASTER_OPTS $HBASE_JMX_BASE -Xmx192m -Xms192m -Xmn72m”
export HBASE_REGIONSERVER_OPTS=“$HBASE_REGIONSERVER_OPTS $HBASE_JMX_BASE -Xmx1024m -Xms1024m -verbose:gc -Xloggc:/mnt/hadoop-2.4.1/hbase/logs/hbaseRgc.log -XX:+PrintAdaptiveSizePolicy -XX:+PrintGC -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/mnt/hadoop-2.4.1/hbase/logs/java_pid{$$}.hprof”
export HBASE_ZOOKEEPER_OPTS=“$HBASE_ZOOKEEPER_OPTS $HBASE_JMX_BASE -Xmx192m -Xms72m”
in hbase-site.xml
RegionServer發生out of memory閃退跟hbase.hregion.max.filesize、hbase.hregion.memstore.flush.size和hbase.hregion.memstore.block.multiplier有關。
hbase.hregion.max.filesize太小的缺點
- 每台ResrionServer的Regions會太多 (P.S. 每個region的每個ColumnFamily會占用2MB的MSLAB)
- 造成頻繁的split和compact
- 開啟的storefile數量太多 (P.S. Potential Number of Open Files = (StoreFiles per ColumnFamily) x (regions per RegionServer))
hbase.hregion.max.filesize太大的缺點
- 太少Region, 沒有Distributed Mode的效果了
- split和compact時的pause也會過久
write buffer在server-side memory-used是(hbase.client.write.buffer) * (hbase.regionserver.handler.count), 所以hbase.client.write.buffer和hbase.regionserver.handler.count太高會吃掉太多記憶體, 但是太少會增加RPC的數量。
hbase.zookeeper.property.tickTime和zookeeper.session.timeout太短會造成ZooKeeper SessionExpired。hbase.ipc.warn.response.time設長一點可以suppress responseTooSlow warning。
hbase.hregion.memstore.flush.size和hbase.hregion.memstore.block.multiplier也會影響split和compact的頻率。
1 |
|
Start Servers
- run hdfs namenode -format on pigpigpig-client6
- run start-dfs.sh on pigpigpig-client6
- run start-yarn.sh on pigpigpig-client2
- run start-yarn.sh on pigpigpig-client4
- run start-hbase.sh on pigpigpig-client6
- run java -Xmx1024m -Xms1024m -XX:+UseConcMarkSweepGC -jar start.jar in solr folder on pigpigpig-client2
- run hadoop fs -mkdir /user;hadoop fs -mkdir /user/pigpigpig;hadoop fs -put urls /user/pigpigpig in nutch folder on pigpigpig-client6
- run hadoop jar apache-nutch-2.4-SNAPSHOT.job org.apache.nutch.crawl.InjectorJob urls -crawlId webcrawl in nutch folder on pigpigpig-client6
- run hadoop jar apache-nutch-2.4-SNAPSHOT.job org.apache.nutch.crawl.GeneratorJob -crawlId webcrawl in nutch folder on pigpigpig-client6
- run hadoop jar apache-nutch-2.4-SNAPSHOT.job org.apache.nutch.fetcher.FetcherJob -all -crawlId webcrawl in nutch folder on pigpigpig-client6
- run hadoop jar apache-nutch-2.4-SNAPSHOT.job org.apache.nutch.parse.ParserJob -all -crawlId webcrawl in nutch folder on pigpigpig-client6
- run hadoop jar apache-nutch-2.4-SNAPSHOT.job org.apache.nutch.crawl.DbUpdaterJob -all -crawlId webcrawl in nutch folder on pigpigpig-client6
- run hadoop jar apache-nutch-2.4-SNAPSHOT.job org.apache.nutch.indexer.IndexingJob -D solr.server.url=http://pigpigpig-client2/solr/nutch/ -all -crawlId webcrawl in nutch folder on pigpigpig-client6
Stop Servers
- run stop-hbase.sh on pigpigpig-client6
- run stop-yarn.sh on pigpigpig-client2
- run stop-yarn.sh on pigpigpig-client4
- run stop-dfs.sh on pigpigpig-client6
Screenshots
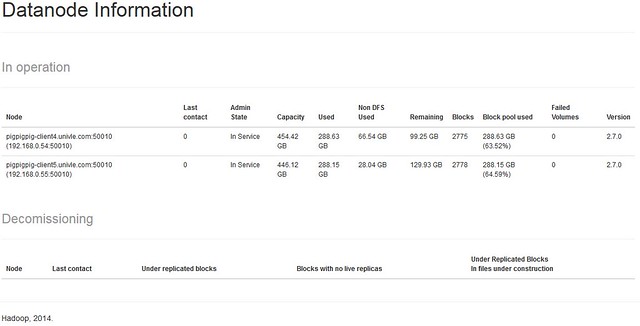

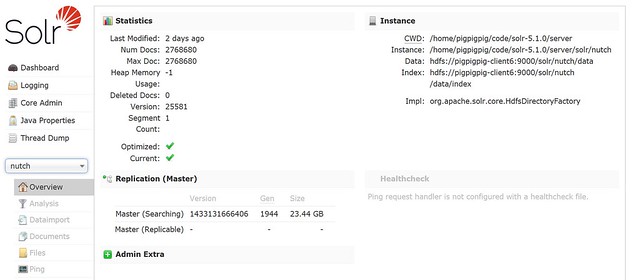
Resources
- 完整Configuration files請到https://github.com/EugenePig/Experiment1下載
- https://github.com/EugenePig/Gora/tree/Gora-0.6.1-SNAPSHOT-Hadoop27-Solr5
- https://github.com/EugenePig/nutch/tree/2.4-SNAPSHOT-Hadoop27-Solr5
- https://github.com/EugenePig/ik-analyzer-solr5
How to Reuse Old PCs for Solr Search Platform?的更多相关文章
- Custom SOLR Search Components - 2 Dev Tricks
I've been building some custom search components for SOLR lately, so wanted to share a couple of thi ...
- solr search基础知识(控制符及其参数)
1.^ 控制符 (1)查询串上用^ 搜索: 天后王菲,如果希望将王菲的相关度加大,用^控制符. 天后 王菲^10.5 结果就会将含有王菲的document权重加大分数提高,排序靠前,10.5为权重 ...
- Spring Boot Reference Guide
Spring Boot Reference Guide Authors Phillip Webb, Dave Syer, Josh Long, Stéphane Nicoll, Rob Winch, ...
- 资源list:Github上关于大数据的开源项目、论文等合集
Awesome Big Data A curated list of awesome big data frameworks, resources and other awesomeness. Ins ...
- Awesome Big Data List
https://github.com/onurakpolat/awesome-bigdata A curated list of awesome big data frameworks, resour ...
- java框架之SpringBoot(1)-入门
简介 Spring Boot 用来简化 Spring 应用开发,约定大于配置,去繁从简,just run 就能创建一个独立的.产品级别的应用. 背景: J2EE 笨重的开发.繁多的配置.低下的开发效率 ...
- spring boot 项目搭建时,各个依赖的作用
项目搭建页面 https://start.spring.io/ 各个依赖的作用 List of dependencies for Spring Boot 2.1.5.RELEASE Core DevT ...
- 什么是Spring Boot简介
1.什么是spring boot 简单的说,spring boot就是整合了很多优秀的框架,不用我们自己手动的去写一堆xml配置然后进行配置. 从本质上来说,Spring Boot就是Spring,它 ...
- 搭建Spring Initializr服务器
前言 按照网上很多教程,出错特别多.首先是GitHub和maven仓库的网络环境比较差,踩了很多坑:其次是SpringInitializr更新迭代几个版本,0.7.0我也没能弄成功.索性就用了旧版本0 ...
随机推荐
- @Value 和 @ConfigurationProperties 获取值的比较
1.不同点 (1)@ConfigurationProperties(prefix = "person") 功能:批量注入配置文件中的属性 SpEL:不支持表达式 JSR303数据校 ...
- 如何在 CentOS 7 中安装、配置和安全加固 FTP 服务
步骤 1:安装 FTP 服务器 1. 安装 vsftpd 服务器很直接,只要在终端运行下面的命令. # yum install vsftpd 2. 安装完成后,服务先是被禁用的,因此我们需要手动启动, ...
- 搭建Weblogic服务器
安妮,我的小熊熊在ne....... 01.安全设置 service iptables stop chkconfig iptables off #关闭防火墙,只是建议,为了简便操作 setenf ...
- 首页设计的可用性和PET
网站的首页是一个让人头疼的东西.有时它看起来很简单:首页就是网站内容的整合,一个产品经理随便从网站里拿点东西出来,就能堆出一个看上去靠谱的首页.也正因此,它往往非常麻烦:很多人都可以发表自己的见解,而 ...
- python标准日志模块logging的使用方法
参考地址 最近写一个爬虫系统,需要用到python的日志记录模块,于是便学习了一下.python的标准库里的日志系统从Python2.3开始支持.只要import logging这个模块即可使用.如果 ...
- awk打印倒数第2列
cat 1-iplist.txt | awk '{ print $(NF-2) }'|wc 实际示例: 打印nginx日志中 变量request_time超过3秒的日志信息 [root@datalin ...
- [转载]在rhel 6 x86_64 上安装oracle 11g xe
原文地址:在rhel 6 x86_64 上安装oracle 11g xe作者:pccom Oracle 11g xe for linux目前只有x86_64 版本,没有i386, i686 版本,如果 ...
- gVim中重新载入当前文件
http://club.topsage.com/thread-2251455-1-1.html有些时候当前打开的文件可能被外部程序不知不觉改变了,这个时候我们就需要重新打开这个文件,或是重读/重载一个 ...
- laravel 5.1 添加第三方扩展库
步骤一:确定你要放第三方库的目录,假设:app/libs,并在该目录下放置类文件common.php.
- 解决spring el表达式不起作用
el表达式不起作用,如下图所示 现象: 在显示页面中加入: <%@ page isELIgnored="false" %>就OK了 参考:http://bbs.csdn ...