(数据科学学习手札54)Python中retry的简单用法
一、简介
retry是一个用于错误处理的模块,功能类似try-except,但更加快捷方便,本文就将简单地介绍一下retry的基本用法。
二、基本用法
retry:
作为装饰器进行使用,不传入参数时功能如下例所示:
from retry import retry @retry()
def demo():
print('错误')
raise demo()
我们编写了每次运行都会通过raise报错的自定义函数demo(),利用默认参数的retry()进行装饰,运行结果如下:

可以看到,retry()在这里的功能,是在其装饰的函数运行报错后重新运行该函数,在上例中的效果就是反复运行demo(),这也是retry()的基本用法,下面介绍其几个主要参数:
exceptions:传入指定的错误类型,默认为Exception,即捕获所有类型的错误,也可传入元组形式的多种指定错误类型
tries:定义捕获错误之后重复运行次数,默认为-1,即为无数次
delay:定义每次重复运行之间的停顿时长,单位秒,默认为0,即无停顿
backoff:呈指数增长的每次重复运行之间的停顿时长,需要配合delay来使用,譬如delay设置为3,backoff设置为2,则第一次间隔为3*2**0=1秒,第二次3*2**1=2秒,第三次3*2**2=4秒,以此类推,默认为1
max_delay:定义backoff和delay配合下出现的等待时间上限,当delay*backoff**n大于max_delay时,等待间隔固定为该值而不再增长
下面我们通过几个直观的例子来更加深刻地认识上述参数:
import time
from retry import retry '''记录初始时刻'''
start_time = time.clock() @retry(delay=1,tries=4,backoff=2)
def demo(start_time):
'''将当前时刻与初始时刻的时间差(单位:S)作差并四舍五入'''
print(round(time.clock()-start_time,0))
raise demo(start_time)
在上例中,我们设置delay为1,tries为4,backoff为2,通过我们的自定义函数来记录每次重复运行与初始时刻的时间差,这样第一次与第二次间隔时间为1*2**0=1,第二次与第三次间隔为1*2**1=2,第三次与第四次间隔4,运行结果如下,到达预定的运行状况后程序就会报错从而终止运行:
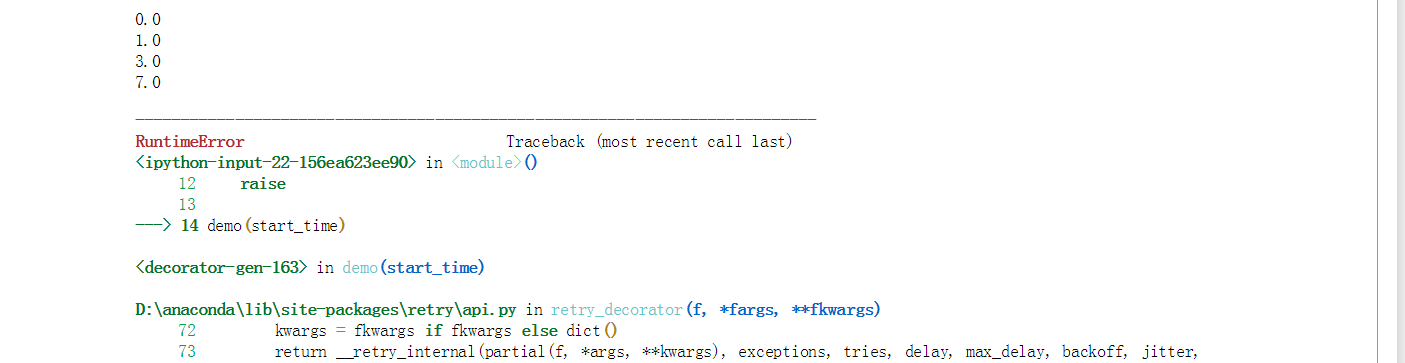
符合我们上面的计算结果,下面我们设置一个较小的max_delay:
import time
from retry import retry '''记录初始时刻'''
start_time = time.clock() @retry(delay=1,tries=10,backoff=2,max_delay=20)
def demo(start_time):
'''将当前时刻与初始时刻的时间差(单位:S)作差并四舍五入'''
print(round(time.clock()-start_time,0))
raise demo(start_time)
运行结果如下:
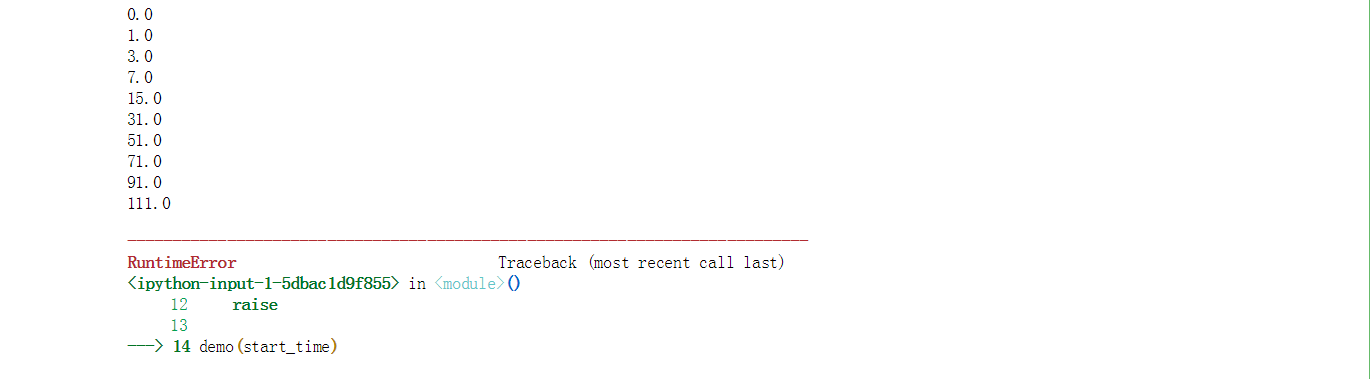
可以看到,在delay和backoff共同控制下的间隔时长超过20秒后,之后的每一次间隔时长都固定为20秒,直到所有的tries运行结束。
利用retry,我们可以在譬如网络爬虫过程中更加简洁灵活地控制错误处理过程,使得代码具有更好的可读性,以上就是本文的基本内容,如有笔误,望指出。
(数据科学学习手札54)Python中retry的简单用法的更多相关文章
- (数据科学学习手札14)Mean-Shift聚类法简单介绍及Python实现
不管之前介绍的K-means还是K-medoids聚类,都得事先确定聚类簇的个数,而且肘部法则也并不是万能的,总会遇到难以抉择的情况,而本篇将要介绍的Mean-Shift聚类法就可以自动确定k的个数, ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
随机推荐
- HTML5 拖放、交换位置
设置元素为可拖放 draggable 属性设置为 true: <img draggable="true" /> 拖动什么 - ondragstart 和 setData ...
- fzu_oop_east 第一次作业
第一题 题目: 代码: #include<iostream> #include<cstdio> using namespace std; class Date { public ...
- 深入了解Node模块原理
深入了解Node模块原理 当我们编写JavaScript代码时,我们可以申明全局变量: var s = 'global'; 在浏览器中,大量使用全局变量可不好.如果你在a.js中使用了全局变量s,那么 ...
- 浅谈 JavaScript 中的继承模式
最近在读一本设计模式的书,书中的开头部分就讲了一下 JavaScript 中的继承,阅读之后写下了这篇博客作为笔记.毕竟好记性不如烂笔头. JavaScript 是一门面向对象的语言,但是 ES6 之 ...
- fastjson反序列化TemplatesImpl
环境参考第一个链接,直接用IDEA打开 编译EvilObject.java成EvilObject.class 先看poc,其中NASTY_CLASS为TemplatesImpl类,evilCode是E ...
- CocoaPods安装指定版本
Cocoapods目前最新的正式版本是0.35.0,如果升级到这个版本,并且在project中使用XMPPFramework,在pod install之后会出现如下循环依赖的问题 There is a ...
- GridView 子项长度和宽度一样
下面是gridview 控件,每行放置四个,因此用宽度除4. 下面展现出来的的界面就显的比较美观. public class HotSearchAdapter extends BaseAdapter ...
- H.264的码率控制:CBR和VBR
CBR: Constants Bits Rate, 静态比特率. 比特率在流的进行过程中基本保持恒定并且接近目标比特率,当对复杂内容编码时质量会下降. 在流式播放方案中使用CBR编码最为有效;优点是带 ...
- DataFrame概念与创建
一 概念 Pandas是一个开源的Python数据分析库.Pandas把结构化数据分为了三类: Series,1维序列,可视作为没有column名的.只有一个column的DataFrame: Dat ...
- EF Core中外键关系的DeleteBehavior介绍(转自MSDN)
Delete behaviors Delete behaviors are defined in the DeleteBehavior enumerator type and can be passe ...