(数据科学学习手札54)Python中retry的简单用法
一、简介
retry是一个用于错误处理的模块,功能类似try-except,但更加快捷方便,本文就将简单地介绍一下retry的基本用法。
二、基本用法
retry:
作为装饰器进行使用,不传入参数时功能如下例所示:
from retry import retry @retry()
def demo():
print('错误')
raise demo()
我们编写了每次运行都会通过raise报错的自定义函数demo(),利用默认参数的retry()进行装饰,运行结果如下:

可以看到,retry()在这里的功能,是在其装饰的函数运行报错后重新运行该函数,在上例中的效果就是反复运行demo(),这也是retry()的基本用法,下面介绍其几个主要参数:
exceptions:传入指定的错误类型,默认为Exception,即捕获所有类型的错误,也可传入元组形式的多种指定错误类型
tries:定义捕获错误之后重复运行次数,默认为-1,即为无数次
delay:定义每次重复运行之间的停顿时长,单位秒,默认为0,即无停顿
backoff:呈指数增长的每次重复运行之间的停顿时长,需要配合delay来使用,譬如delay设置为3,backoff设置为2,则第一次间隔为3*2**0=1秒,第二次3*2**1=2秒,第三次3*2**2=4秒,以此类推,默认为1
max_delay:定义backoff和delay配合下出现的等待时间上限,当delay*backoff**n大于max_delay时,等待间隔固定为该值而不再增长
下面我们通过几个直观的例子来更加深刻地认识上述参数:
import time
from retry import retry '''记录初始时刻'''
start_time = time.clock() @retry(delay=1,tries=4,backoff=2)
def demo(start_time):
'''将当前时刻与初始时刻的时间差(单位:S)作差并四舍五入'''
print(round(time.clock()-start_time,0))
raise demo(start_time)
在上例中,我们设置delay为1,tries为4,backoff为2,通过我们的自定义函数来记录每次重复运行与初始时刻的时间差,这样第一次与第二次间隔时间为1*2**0=1,第二次与第三次间隔为1*2**1=2,第三次与第四次间隔4,运行结果如下,到达预定的运行状况后程序就会报错从而终止运行:
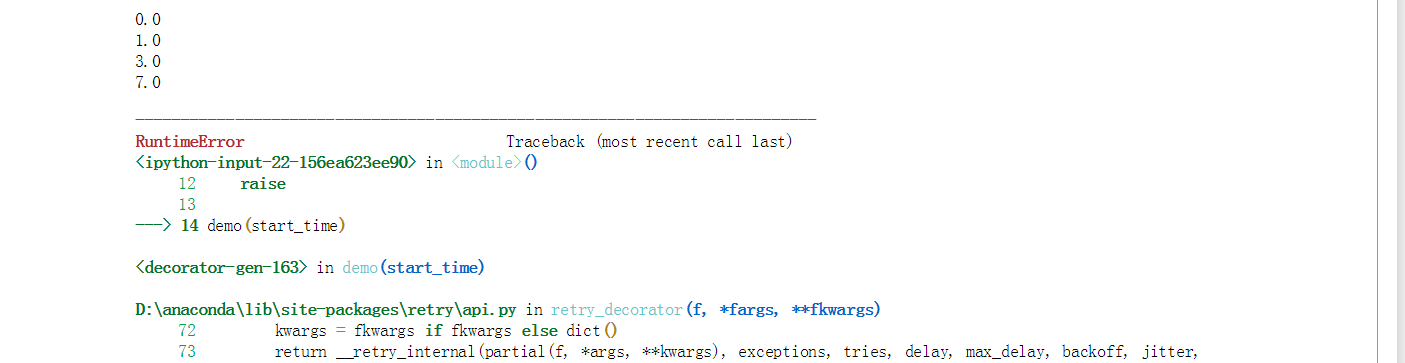
符合我们上面的计算结果,下面我们设置一个较小的max_delay:
import time
from retry import retry '''记录初始时刻'''
start_time = time.clock() @retry(delay=1,tries=10,backoff=2,max_delay=20)
def demo(start_time):
'''将当前时刻与初始时刻的时间差(单位:S)作差并四舍五入'''
print(round(time.clock()-start_time,0))
raise demo(start_time)
运行结果如下:
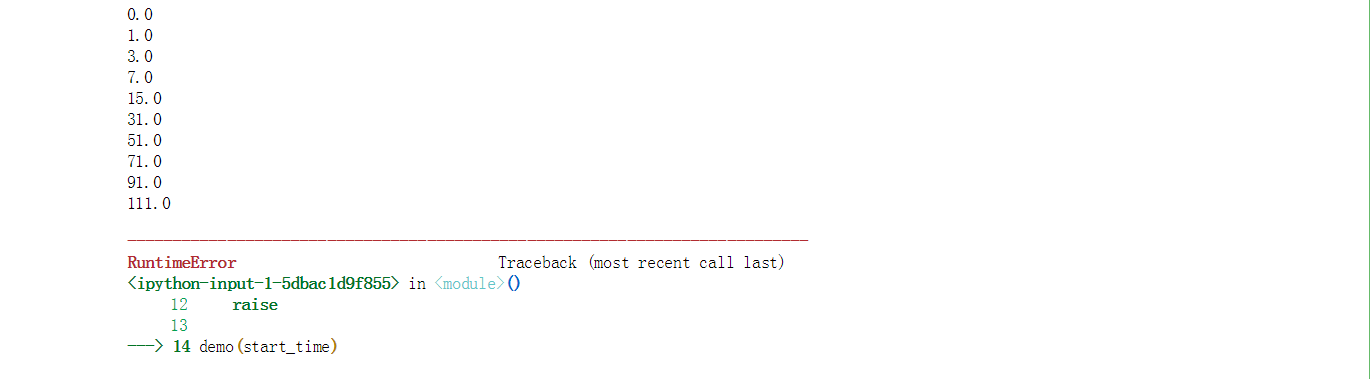
可以看到,在delay和backoff共同控制下的间隔时长超过20秒后,之后的每一次间隔时长都固定为20秒,直到所有的tries运行结束。
利用retry,我们可以在譬如网络爬虫过程中更加简洁灵活地控制错误处理过程,使得代码具有更好的可读性,以上就是本文的基本内容,如有笔误,望指出。
(数据科学学习手札54)Python中retry的简单用法的更多相关文章
- (数据科学学习手札14)Mean-Shift聚类法简单介绍及Python实现
不管之前介绍的K-means还是K-medoids聚类,都得事先确定聚类簇的个数,而且肘部法则也并不是万能的,总会遇到难以抉择的情况,而本篇将要介绍的Mean-Shift聚类法就可以自动确定k的个数, ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
随机推荐
- 《C++ Primer Plus》读书笔记之四—分支语句和逻辑操作符
第六章 分支语句和逻辑操作符 1.&&的优先级低于关系操作符. 2.取值范围:取值范围的每一部分都使用AND操作符将两个完整的关系表达式组合起来: if(age>17&& ...
- MySQL -Naivacat工具与pymysql模块
Navicat 在生产环境中操作MySQL数据库还是推荐使用命令行工具mysql,但在我们自己开发测试时,可以使用可视化工具Navicat,以图形界面的形式操作MySQL数据库. 官网下载:https ...
- OC基础数据类型-NSValue
1.NSValue:将指针等复杂的类型存储为对象 struct sct { int a; int b; }sctt; NSValue * value = [[NSValue alloc] initWi ...
- Safari自动代理
1. 准备一个代理服务器,我使用的是GoAgent. 2. 准备一个PAC文件,我是从chrome导出的. 3. 准备一个本地文件服务器或web服务器,我是因为手头有一个使用NodeJS的小项目,所以 ...
- jquery实现的时间轴
代码 样式文件style.css 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 ...
- visual stdio 安装OpenGL库文件
1.将下载的压缩包解开.将得到5个文件 1. 将glut解压出来,将当中的glut.h拷贝到C:\Program Files (x86)\Microsoft Visual Studio 11.0\VC ...
- 【转+修改】容联云通讯api调用短信发送调用
转自 https://my.oschina.net/u/1995134/blog/814540 需要荣联云通讯 的 相对应SDKjar包. CCP_REST_SMS_SDK_JAVA_v2.6.3 ...
- 【LGP2045】方格取数加强版
题目 还纠结了一下是费用流还是最小割 最终还是决定让最小割去死吧 我们的问题就是让一个点的点权只被计算一次 考虑拆点 将所有点拆成入点和出点,入点向出点连流量为\(1\)的边 每一个出点往下连能到达的 ...
- [HNOI2003]多边形
嘟嘟嘟 也是一道半平面相交板子题. 比较好的处理方法是先把原图形全部加入答案,然后在一条边一条边切. 然而第一个点全网(当然包括我)都没过,我最后也只能固输了-- #include<cstdio ...
- vim在插入模式粘贴代码缩进问题解决方法
转载自:https://blog.csdn.net/commshare/article/details/6215088 在vim粘贴代码会出现缩进问题,原因在于vim在代码粘贴时会自动缩进 解决方法: ...