Python爬虫与反爬虫(7)
【Python基础知识】Python爬虫与反爬虫(7)
很久没有补爬虫了,相信在白蚁二周年庆的活动大厅比赛中遇到了关于反爬虫的问题吧
这节我会做个基本分享。
从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分。
一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式。前两种比较容易遇到,大多数网站都从这些角度来反爬虫。第三种一些应用ajax的网站会采用,这样增大了爬取的难度。
user-agent
最简单的反爬虫机制,应该算是U-A校验了。浏览器在发送请求的时候,会附带一部分浏览器及当前系统环境的参数给服务器,这部分数据放在HTTP请求的header部分(如下图是一个请求头示意)。
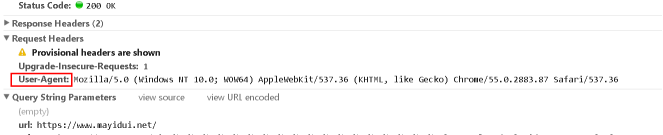
header的表现形式为key-value对,其中User-Agent标示了一个浏览器的型号,如上图即为在windows 10系统中Chrome的User-Agent.
这方面的应对措施就是模拟U-A,即手动制定修改。
还有一部分网站会对Referer进行检测(一些资源网站的防盗链就是检测Referer)。如果遇到了这类反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值修改为目标网站域名。对于检测Headers的反爬虫,在爬虫中修改或者添加Headers就能很好的绕过。

像这样通过字典来设定headers。
IP限制
网站是通过检测用户行为,例如同一IP短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。
还有一个方案就是更换ip过,但是很多代理IP的寿命都比较短,所以最好有一套完整的机制来校验已有代理IP的有效性。这里提供思路:可以专门写一个爬虫,爬取网上公开的代理ip,检测后全部保存起来。这样的代理ip爬虫经常会用到,最好自己准备一个。有了大量代理ip后可以每请求几次更换一个ip,这在requests或者urllib2中很容易做到,这样就能很容易的绕过IP限制反爬虫。


另一种种情况,可以在每次请求后随机间隔几秒再进行下一次请求。有些有逻辑漏洞的网站,可以通过请求几次,退出登录,重新登录,继续请求来绕过同一账号短时间内不能多次进行相同请求的限制。
访问频率限制
我们访问一些网站,由于一些网站的访问时间设置,我们是不能快速进入下一页的,这个时候,我们需要修改他的访问时间,在它访问下一页的时候,通过 POST 方式,修改 read_time,正常访问的话,这个值一般会大于10如果我们修改成 60。于是轻轻松松的通过了它的反爬虫策略。
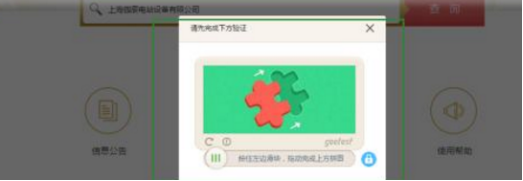
验证码限制
问题类似的,这样的方式与上面的方式相比更加难处理的是,不管你的访问频次怎么样,你都需要输入验证码才行。看图:

解决方案有:学习验证码识别算法。
1)利用开源的Tesseract-OCR系统进行验证码图片 的下载及识别,再将识别的字符传到爬虫系统进行模拟登陆。
2)将验证码图片上传到打码平台上进行识别。如果不成功,可以再次更新验证码识别,直到成功为止。
变换网页结构
像社交网站,他们会经常更换网页的结构,大部分情况下我们都需要通过网页结构来解析需要的数据,如果变换了结构,则在原本的网页位置找不到原本需要的内容。
解决方法:可以考虑解析数据时通过数据的特点来解析而不是通过网页结构,这样只要网页上我们需要的数据不变,基本可以不关心网页结构如何。
通过账号限制
像论坛这类可以利用,匿名模式不可用。
这里讲下cookie,但是cookie不会不断地更新,在采集一些网站时 cookie 是不可或缺的。要在一个网站上持续保持登录状态,需要在多个页面中保存一个 cookie。这或许能提供给我们一个思路,访问网站和离开网站时 cookie 是如何设置的。
JavaScript
首先,爬虫是通过程序替代浏览器的行为,那么只要能监测出请求来自浏览器还是程序,也就是通过浏览器和程序的不同点的来限制爬,浏览器最大的一个特点就是具有javascript的执行环境,那么可以通过这一特性来制定出一种防爬规则,第一次访问网站时返回一个4XX的错误码,同时返回一段加密的js代码,其中加些对dom操作的代码,最要作用的还是向cookie中写入一个值,同时http请求也返回一个cookie值,同时服务端存储一个sessionid,然后重试,第二次请求服务端验证cookie,通过返回200,这样保证浏览器可以正常访问,程序由于无法正确的解析出正确的cookie值,导致无法正常访问
蜜罐技术
网页上会故意留下一些人类看不到或者绝对不会点击的链接。由于爬虫会从源代码中获取内容,所以爬虫可能会访问这样的链接。这个时候,只要网站发现了有IP访问这个链接,立刻永久封禁该IP + User-Agent + Mac地址等等可以用于识别访问者身份的所有信息。这个时候,访问者即便是把IP换了,也没有办法访问这个网站了。给爬虫造成了非常大的访问障碍。
不过幸运的是,定向爬虫的爬行轨迹是由我们来决定的,爬虫会访问哪些网址我们都是知道的。因此即使网站有蜜罐,定向爬虫也不一定会中招。
源代码格式都不一样
有一些网站,他们每个相同类型的页面的源代码格式都不一样,我们必需要针对每一个页面写XPath或者正则表达式,这种情况就比较棘手了。如果我们需要的内容只是文本,那还好说,直接把所有HTML标签去掉就可以了。可是如果我们还需要里面的链接等等内容,那就只有做苦力一页一页的去看了。这种网站很少,因为如果每个页面的源代码格式都不一样,要不就用户体验查,要不就做网页的内容会被累个半死。
动态加载
很多时候ajax请求都会经过后端鉴权,不能直接构造URL获取。这时就可以通PhantomJS+Selenium模拟浏览器行为,抓取经过js渲染后的页面。
爬取的数据是通过ajax请求得到,或者通过Java生成的。首先用Firebug或者HttpFox对网络请求进行分析。如果能够找到ajax请求,也能分析出具体的参数和响应的具体含义,我们就能采用上面的方法,直接利用requests或者urllib2模拟ajax请求,对响应的json进行分析得到需要的数据。
用的是selenium+phantomJS框架,调用浏览器内核,并利用phantomJS执行js来模拟人为操作以及触发页面中的js脚本。从填写表单到点击按钮再到滚动页面,全部都可以模拟,不考虑具体的请求和响应过程,只是完完整整的把人浏览页面获取数据的过程模拟一遍。
用这套框架几乎能绕过大多数的反爬虫,因为它不是在伪装成浏览器来获取数据(上述的通过添加 Headers一定程度上就是为了伪装成浏览器),它本身就是浏览器,phantomJS就是一个没有界面的浏览器,只是操控这个浏览器的不是人。利用 selenium+phantomJS能干很多事情,例如识别点触式(12306)或者滑动式的验证码,对页面表单进行暴力破解等等。
写在后面的话:
这些东西都是百度搜集整合了很多帖子才出来的,有很多不完善的地方还请大家指教,关于爬虫类我想先到此为止,我觉察出,这是一个层次观念,我所了解的基础还没有完全,只能做个小小的适应大概,无法深入了解,像数据处理这块,数据挖掘,数据分析,一点也没到那种程度。还是希望自己能有更踏实的心,和大家一起进步。
Python爬虫与反爬虫(7)的更多相关文章
- python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性)
python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性) 目录 随机User-Agent 获取代理ip 检测代理ip可用性 随机User-Agent fake_usera ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- Python爬虫入门教程 65-100 爬虫与反爬虫的修罗场,点评网站,字体反爬之三
爬虫与反爬虫的修罗场 哪种平台最吸引爬虫爱好者,当然是社区类的,那里容易产生原生态,高质量的数据啊, 你看微博,知乎,豆瓣爬的不亦乐乎. 评论也是产生内容的好地方 生活类点评网站 旅游类点评网站 音乐 ...
- 【Python】爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- Python之爬虫(二十四) 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- C#爬虫与反爬虫--字体加密篇
爬虫和反爬虫是一条很长的路,遇到过js加密,flash加密.重点信息生成图片.css图片定位.请求头.....等手段:今天我们来聊一聊字体: 那是一个偶然我遇到了这个网站,把价格信息全加密了:浏览器展 ...
- Python Scrapy突破反爬虫机制(项目实践)
对于 BOSS 直聘这种网站,当程序请求网页后,服务器响应内容包含了整个页面的 HTML 源代码,这样就可以使用爬虫来爬取数据.但有些网站做了一些“反爬虫”处理,其网页内容不是静态的,而是使用 Jav ...
- 深入细枝末节,Python的字体反爬虫到底怎么一回事
内容选自 即将出版 的<Python3 反爬虫原理与绕过实战>,本次公开书稿范围为第 6 章——文本混淆反爬虫.本篇为第 6 章中的第 4 小节,其余小节将 逐步放送 . 字体反爬虫开篇概 ...
- crawler_爬虫_反爬虫策略
关于反爬虫和恶意攻击的一些策略和思路 有时网站经常受到恶意spider攻击,疯狂抓取网站内容,对网站性能有较大影响. 下面我说说一些反恶意spider和spam的策略和思路. 1. 通过日志分析来 ...
随机推荐
- Java实现发邮件功能
代码如下: package com.weimob.finance.utils;import java.io.UnsupportedEncodingException;import java.util. ...
- flink Window的Timestamps/Watermarks和allowedLateness的区别
Watermartks是通过additional的时间戳来控制窗口激活的时间,allowedLateness来控制窗口的销毁时间. 注: 因为此特性包括官方文档在1.3-1.5版本均未做改变,所以 ...
- Java I/O系列(一)InputStream与OutputStream源码分析及理解
1. InputStream 定义 字节输入流,是一个抽象类,核心是通过read()方法,从数据源中读取一个个字节出来,另有skip,mark功能 核心源码理解 源码: public abstract ...
- 协议类接口 - NAND
一.引脚的含义 先看下nand flash是怎么接的,如下所示便为某一款nand存储芯片的引脚图.发现其连地址信号都没有.那么是如何访问地址数据的呢? 查阅该nand flash的数据手册可得其各个引 ...
- BZOJ 2654: tree(二分 最小生成树)
Time Limit: 30 Sec Memory Limit: 512 MBSubmit: 2901 Solved: 1196[Submit][Status][Discuss] Descript ...
- Linux系统初学-第一课 虚拟机安装CentOS6.5以及Root密码找回
Linux系统初学第一课 虚拟机安装CentOS6.5以及Root密码找回 虚拟机安装CentOS6.5 一.安装虚拟机 1-1.安装虚拟机VMware Station,新建虚拟机,选择典型配置. 1 ...
- hubilder 打包app ios高版本不支持问题
<script type="text/javascript"> document.addEventListener('plusready', function(){ v ...
- 课时6.HTTP协议(理解)
HTTP是Hypertext Transfer Protocol的缩写,译为:超文本传输协议 什么是协议? 在现实生活中有很多的协议,例如租房协议/买卖协议/离婚协议 无论是什么协议它们都有一个共同点 ...
- MongoDB DBA 实践4-----创建复制集
一.复制 复制允许多个数据库服务器共享相同数据的功能,从而确保冗余并促进负载平衡 1.数据冗余及可用性 复制技术提供数据冗余及可用性,在不同的数据库服务器上使用多个数据副本,复制技术防止单个数据库服务 ...
- string 模块
string 说明:string 模块保留了很多有用的常量和类,用来处理 string 和 unicode 对象. 作用:包含处理文本的常量和类. capwords( ) capwords( ) 的作 ...