使用webmagic搭建一个简单的爬虫
刚刚接触爬虫,听说webmagic很不错,于是就了解了一下。
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
这句话说的真的一点都不假,像我这样什么都不懂的人直接下载部署,看了看可以调用的方法,马上就写出了第一个爬虫小程序。
以下是我学习的过程:
首先需要下载jar:http://webmagic.io/download.html
部署好后就建一个class继承PageProcessor接口,重写process()方法,即可完成一个爬虫。
是不是很简单?
先上代码,再讲解吧。
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor; public class MyProcessor implements PageProcessor {
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
private static int count =0; @Override
public Site getSite() {
return site;
} @Override
public void process(Page page) {
//判断链接是否符合http://www.cnblogs.com/任意个数字字母-/p/7个数字.html格式
if(!page.getUrl().regex("http://www.cnblogs.com/[a-z 0-9 -]+/p/[0-9]{7}.html").match()){
//加入满足条件的链接
page.addTargetRequests(
page.getHtml().xpath("//*[@id=\"post_list\"]/div/div[@class='post_item_body']/h3/a/@href").all());
}else{
//获取页面需要的内容
System.out.println("抓取的内容:"+
page.getHtml().xpath("//*[@id=\"Header1_HeaderTitle\"]/text()").get()
);
count ++;
}
} public static void main(String[] args) {
long startTime, endTime;
System.out.println("开始爬取...");
startTime = System.currentTimeMillis();
Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run();
endTime = System.currentTimeMillis();
System.out.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
} }
由于刚开始学,技术有限,所以简单地爬一下这些文章的作者。
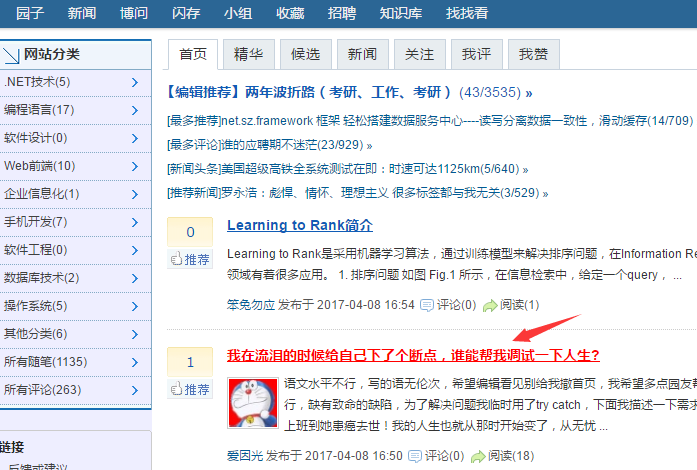
要爬取,首先得知道内容在哪个位置上。在chrome下审查一下元素发现,文章都在这里
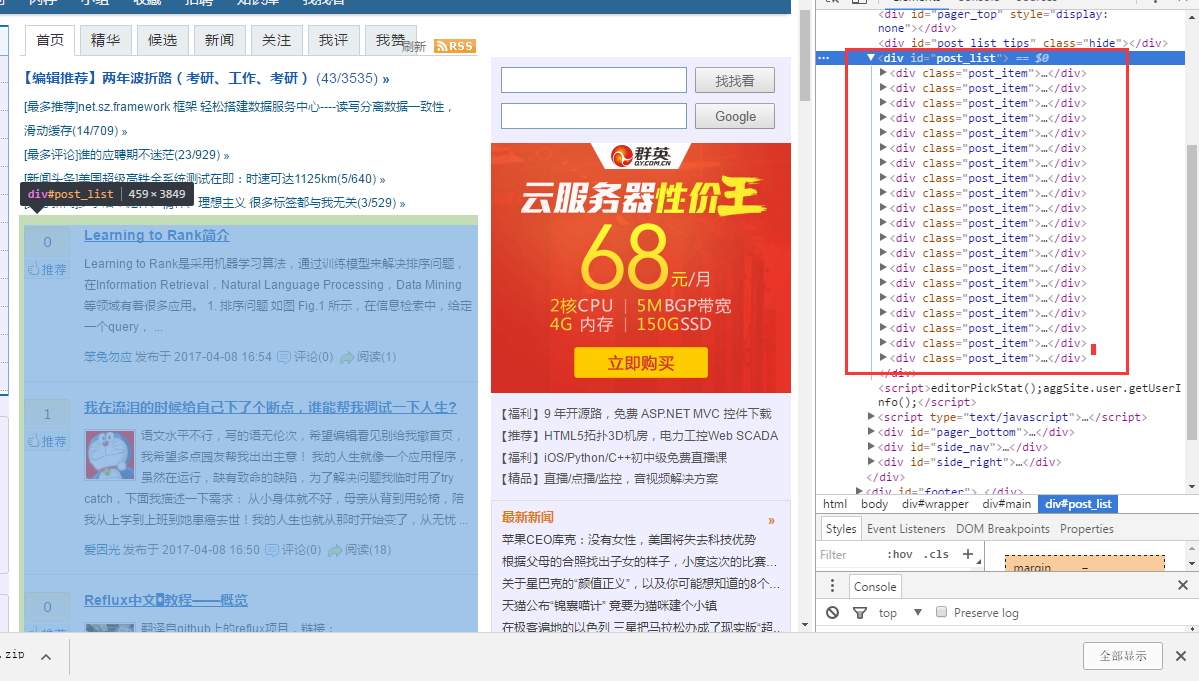
点进文章后审查元素发现作者的名字在这里
知道要爬的内容在哪个位置之后。我们还需要知道怎样才能拿到这些数据。
这里说一下webmagic的内容
启动爬虫就这句:Spider.create(new MyProcessor()).addUrl("https://www.cnblogs.com/").thread(5).run();//addUrl就是种子url
Page对象就是当前获取的页面,
getUrl()可以获得当前url,
addTargetRequests()就是把链接放入等待爬取
getHtml()获得页面的html元素
上面这些很容易就能知道它的意思,不懂得是xpath();
刚开始学,我也不懂,但是chrome懂,所以可以让它帮我们写好xpath。
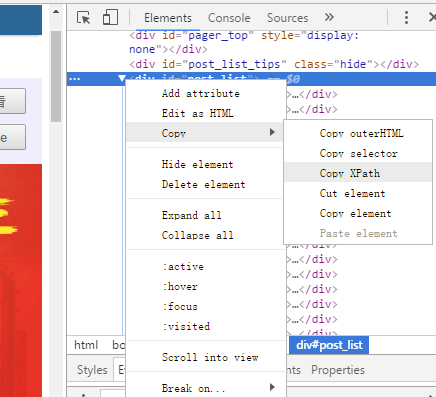
审查元素下,选择要需要的部分右键Copy,选择Copy XPath,然后在console下粘贴
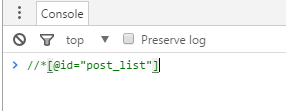
关于xpath的教程可以查看https://www.one-tab.com/page/JFPOsHyvQUOQlzZwahc6-Q
关于webmagic的可以查看http://webmagic.io/docs/zh/posts/ch1-overview/
使用webmagic搭建一个简单的爬虫的更多相关文章
- 【转】使用webmagic搭建一个简单的爬虫
[转]使用webmagic搭建一个简单的爬虫 刚刚接触爬虫,听说webmagic很不错,于是就了解了一下. webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代 ...
- 用nodejs搭建一个简单的服务器
使用nodejs搭建一个简单的服务器 nodejs优点:性能高(读写文件) 数据操作能力强 官网:www.nodejs.org 验证是否安装成功:cmd命令行中输入node -v 如果显示版本号表示安 ...
- 初学Node(六)搭建一个简单的服务器
搭建一个简单的服务器 通过下面的代码可以搭建一个简单的服务器: var http = require("http"); http.createServer(function(req ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
- 【netty】(2)---搭建一个简单服务器
netty(2)---搭建一个简单服务器 说明:本篇博客是基于学习慕课网有关视频教学.效果:当用户访问:localhost:8088 后 服务器返回 "hello netty"; ...
- 使用gitblit搭建一个简单的局域网服务器
使用gitblit搭建一个简单的局域网服务器 1.使用背景 现在很多使用github管理代码,但是github需要互联网的支持,而且私有的git库需要收费.有一些项目的代码不能外泄,所以,搭建一个局域 ...
- Golang学习-第二篇 搭建一个简单的Go Web服务器
序言 由于本人一直从事Web服务器端的程序开发,所以在学习Golang也想从Web这里开始学起,如果对Golang还不太清楚怎么搭建环境的朋友们可以参考我的上一篇文章 Golang的简单介绍及Wind ...
- Python并发编程-一个简单的爬虫
一个简单的爬虫 #网页状态码 #200 正常 #404 网页找不到 #502 504 import requests from multiprocessing import Pool def get( ...
- python爬虫系列(1)——一个简单的爬虫实例
本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片. 1. 概述 本文主要实现一个简单的爬虫,目的是从一个百度贴吧页面下载图片.下载图片的步骤如下: 获取网页html文本内容:分析html中 ...
随机推荐
- peek函数的用法
#include <iostream> /* run this program using the console pauser or add your own getch, system ...
- resize2fs: Bad magic number in super-block while trying to open
I am trying to resize a logical volume on CentOS7 but am running into the following error: resize2fs ...
- 【Java面试题】46 描述一下JVM加载class文件的原理机制?
JVM中类的装载是由类加载器(ClassLoader)和它的子类来实现的,Java中的类加载器是一个重要的Java运行时系统组件,它负责在运行时查找和装入类文件中的类. 由于Java的跨平台性,经过 ...
- 【Java面试题】30 子线程循环10次,接着主线程循环100,接着又回到子线程循环10次,接着再回到主线程又循环100,如此循环50次,请写出程序。
题目如下: 子线程循环10次,接着主线程循环100,接着又回到子线程循环10次, 接着再回到主线程又循环100,如此循环50次 思路如下: 子线程语主线程为互斥,可用SYNCHRONIZED.很容易想 ...
- 系统管理员应该知道的20条Linux命令
如果您的应用程序不工作,或者您希望在寻找更多信息,这 20 个命令将派上用场. 在这个全新的工具和多样化的开发环境井喷的大环境下,任何开发者和工程师都有必要学习一些基本的系统管理命令.特定的命令和工具 ...
- js 停止事件冒泡 阻止浏览器的默认行为
在前端开发工作中,由于浏览器兼容性等问题,我们会经常用到“停止事件冒泡”和“阻止浏览器默认行为”. 浏览器默认行为: 在form中按回车键就会提交表单:单击鼠标右键就会弹出context menu. ...
- jQuery为动态生成的select元素添加事件的方法
项目中需要在点击按钮时动态生成select元素,为防止每次点击按钮时从服务器端获取数据(因为数据都是相同的),可以这样写代码 1.首先定义全局js变量 var strVoucherGroupSelec ...
- Android程序增加代码混淆器
增加代码混淆器.主要是增加proguard-project.txt文件的规则进行混淆,之前新建Android程序是proguard.cfg文件 能够看一下我採用的通用规则(proguard-proje ...
- ios button标记
在写项目的时候,for循环创建多个button,在需要设置背景图片和,需要标记所选中的button的需求, 在这里提供两种方法: 一: 1:把for循环创建的button全部装到一个新建的数组中,把他 ...
- Mac普通用户修改了/etc/sudoers文件的解决办法
1.开启 Root 账户 打开“系统偏好设置”,进入“用户与群组”面板,记得把面板左下角的小锁打开,然后选择面板里的“登录选项”.在面板右边你会看到“网络账户服务 器”,点击它旁边的“加入…”按钮,再 ...