推荐系统学习(2)——基于TF-IDF的改进
使用用户打标签次数*物品打标签次数做乘积的算法尽管简单。可是会造成热门物品推荐的情况。物品标签的权重是物品打过该标签的次数,用户标签的权重是用户使用过该标签的次数。从而导致个性化的推荐减少,而造成热门推荐。
运用TF-IDF的思想能够对算法进行改进。TF-IDF(term frequemcy-inverse documnet frequency)是一种用于资讯检索和文本挖掘的加权技术。用来评估一个词的重要程度。其主要思想是假设某个词或短语在一篇文章中出现的频率TF高,而且在其它文章中非常少出现,则觉得此词或者短语具有非常好的类别区分能力,适合用来分类。IDF是逆向文件频率,即包括某个term的文件越少。则IDF越大。
IDF能够由总文件数目除以包括该词语的文件的数目,然后取对数得到:
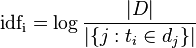
当中D代表文件的总数,分母代表包括该词语的文件的数目。为避免分母为0。通经常使用1+分母作为当前的分母。这样,当包括该词语的文件在总文件数量中所占比重非常小时,可以得到较大的TDF,从而可以得到较大的比重,有利于实现个性化的推荐。(可是引入的TDF却单纯的突出了小频率词汇的权重。从而又可能会给结果带来不好的影响)
则TF-TDF = TF * TDF就反映了一个词对于整个文档集的重要程度。
将TF-IDF应用到基于标签的推荐系统的算法中,则能够进行例如以下改进:

当中n(b)表示标签b被多少不同的用户所使用过。
同理,用n(i)表示物品i被多少个不同的用户打过标签。能够降低热门物品的权重。从而有效的避免热门物品的影响。

推荐系统学习(2)——基于TF-IDF的改进的更多相关文章
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- Spark学习之基于MLlib的机器学习
Spark学习之基于MLlib的机器学习 1. 机器学习算法尝试根据训练数据(training data)使得表示算法行为的数学目标最大化,并以此来进行预测或作出决定. 2. MLlib完成文本分类任 ...
- 期许伟大-基于CMMI的过程改进之道探索
原文作者:上海科维安信息技术顾问有限公司QAI China 何丹博士 CMMI主任评估师 一.引子 近年来,由美国SEI (软件工程研究所)开发的SW-CMM (软件过程能力成熟度模型 ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
随机推荐
- 信息竞赛程序卡时_C++
一.卡时简介 卡时是一个竞赛时常用的技巧 有些题目我们想不到完美算法就只能用暴力解决,但是此类方法一般时间复杂度较高,此时我们需要进行卡时 通俗来讲就是进行一个时间限制,让程序在达到这个时间后立马退出 ...
- Oracle clob 操作
--Oracle clob 操作 -- Created on 2015/4/8 by TianPing declare -- Local variables here v_clob1 Clob; v_ ...
- 5.OpenStack添加镜像服务
添加镜像服务 这里是安装在控制器上 创建数据库 mysql -uroot -ptoyo123 CREATE DATABASE glance; GRANT ALL PRIVILEGES ON glanc ...
- 安卓SDK安装时出现的小问题
在SDK Manager启动安装后出现网页不能访问的错误 错误日志如下 Fetching URL: https://dl-ssl.google.com/android/repository/repos ...
- HDU 2795.Billboard-完全版线段树(区间求最值的位置、区间染色、贴海报)
HDU2795.Billboard 这个题的意思就是在一块h*w的板子上贴公告,公告的规格为1*wi ,张贴的时候尽量往上,同一高度尽量靠左,求第n个公告贴的位置所在的行数,如果没有合适的位置贴则输出 ...
- (4)oracle连接工具和配置监听
一.SQL PLUS sql plus 是oracle最常用的命令行工具,启动sqlplus工具的方法有两种 1. 是在安装好的oracle开始程序的路径下运行程序 点击运行弹出此界面 2 .是在cm ...
- Educational Codeforces Round 32
http://codeforces.com/contest/888 A Local Extrema[水] [题意]:计算极值点个数 [分析]:除了第一个最后一个外,遇到极值点ans++,包括极大和极小 ...
- Southern African 2001 框架折叠 (拓扑序列的应用)
本文链接:http://www.cnblogs.com/Ash-ly/p/5398377.html 题目:考虑五个图片堆叠在一起,比如下面的9 * 8 的矩阵表示的是这些图片的边缘框. 现在上面的图片 ...
- JDBC二部曲之_事物、连接池
事务 事务概述 事务的四大特性(ACID) 事务的四大特性是: l 原子性(Atomicity):事务中所有操作是不可再分割的原子单位.事务中所有操作要么全部执行成功,要么全部执行失败. l 一致 ...
- [Android Traffic] 根据网络类型更改下载模式
转载自: http://blog.csdn.net/kesenhoo/article/details/7396321 Modifying your Download Patterns Based on ...