0428 正则表达式 re模块

复习
异常处理
try except 一定要在except之后写一些提示或者处理的内容 try:
'''可能会出现异常的代码'''
except ValueError:
'''打印一些提示或者处理的内容'''
except NameError:
'''...'''
# except Exception as e:
# '''打印e'''
else:
'''try中的代码正常执行了'''
finally:
'''无论错误是否发生,都会执行这段代码,用来做一些收尾工作'''
二、正则表达式
1,正则表达式用来对字符串进行操作
2,使用一些规则来检测来检测字符串是否符合我的要求————表单验证
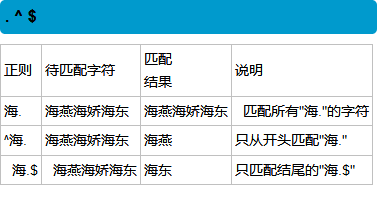
3,从一段字符串中找出符合我要求分内容————爬虫 完全相等的字符串都可以匹配上 字符组:字符组代表一个字符位置上可以出现的所有内容
范围:
根据asc码来的,范围必须是从大到小的指向
一个字符组中可以有多个范围



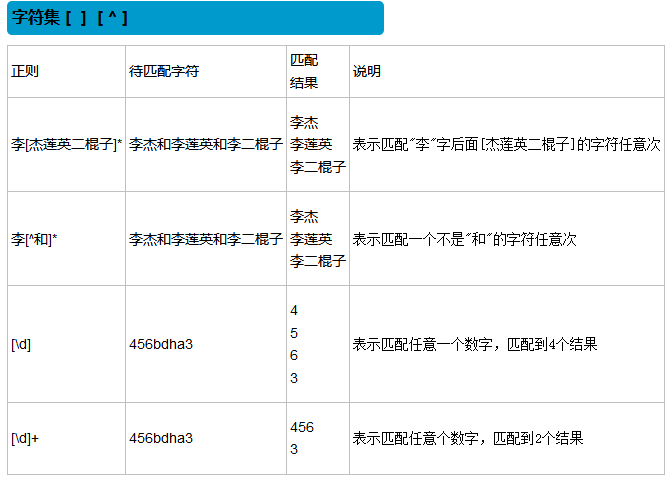
转义符

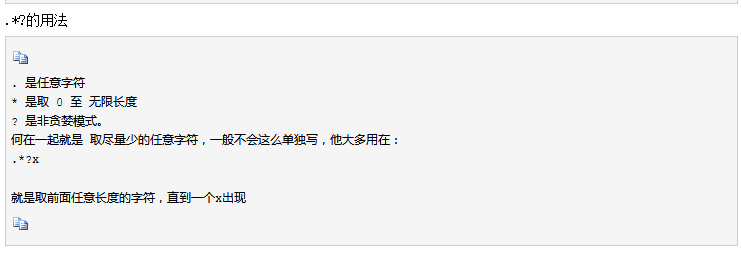
身份证号码第一个长度为15或18个字符的字符串,首位不能为0
如果是15位则全部为数字组成
如果是18位则前十七位全部是数字,末位可能是数字或X
[1-9]\d{16}[\dx]|[1-9]\d{14} 或
如果两个正则表达式之间用‘或’连接,且有一部分正则规则相同,那么一定把规则长的放在前面
[1-9]\d{14}(\d{2}[\dx])?
如果对一组正则表达式整体有一个量词约束,就将这组表达式分成一个组在组外进行量词约束
三、re模块
import re
ret = re.findall('a','eav,and,apple')
print(ret) #['a', 'a', 'a']
findall接收两个参数 : 正则表达式 要匹配的字符串
一个列表数据类型的返回值:所有和这条正则匹配的结果
如果没有,返回[]
import re
ret = re.search('a', 'eva egon yuan')
print(ret.group()) #a
search和findall的区别:
1.search找到一个就返回,findall是找所有
2.findall是直接返回一个结果的列表,search返回一个对象
import re
ret = re.match('a', 'eva egon yuan')
if ret:
print(ret.group()) #None
match
·1 意味着在正则表达式中添加了一个^
·2 和search一样 匹配返回结果对象 没匹配到返回None
·3 和search一样 从结果中获取值 仍然用group
import re
ret = re.sub('\d', 'H', 'eva3egon4yuan4',2)
print(ret) #evaHegonHyuan4 将数字替换成'H',参数2表示只替换2个
import re
ret = re.subn('\d', 'H', 'eva3egon4yuan4')
print(ret) #('evaHegonHyuanH',3)#将数字替换成'H',返回元组(替换的结果,替换了多少次)
import re
obj = re.compile('\d{3}') # 编译 在多次执行同一条正则规则的时候才适用
ret1 = obj.search('abc123eeee')
ret2 = obj.findall('abc123eeee')
print(ret1.group())
print(ret2) 正则表达式 -->根据规则匹配字符串
从一个字符串中找到符合规则的字符串 --> python
正则规则 -编译-> python能理解的语言
多次执行,就需要多次编译 浪费时间 re.findall('1[3-9]\d{9}',line)
编译 re.compile('\d{3}') import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer适用于结果比较多的情况下,能够有效的节省内存
print(ret) # <callable_iterator object at 0x10195f940> finditer返回一个存放匹配结果的迭代器
print(ret.__next__().group()) 查看第一个结果
print(next(ret).group()) 查看第二个结果
for i in ret:
print(i.group())
当分组遇到re模块
import re
ret1 = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com')
ret2 = re.findall('www.(?:baidu|oldboy).com', 'www.baidu.com')
print(ret1) ['oldboy']
print(ret2) ['www.baidu.com']
findall会优先显示组内匹配到的内容,如果想取消分组优先效果,在组内开始的时候加上?:
ret=re.split("\d+","eva3egon4yuan")
print(ret) #结果 : ['eva', 'egon', 'yuan']
ret=re.split("(\d+)","eva3egon4yuan")
print(ret) #结果 : ['eva', '3', 'egon', '4', 'yuan']
split分割一个字符串,默认被匹配到的分隔符不会出现在结果列表中,
如果将匹配的正则放到组内,就会将分隔符放到结果列表里
#在匹配部分加上()之后所切出的结果是不同的,
#没有()的没有保留所匹配的项,但是有()的却能够保留了匹配的项,
#这个在某些需要保留匹配部分的使用过程是非常重要的。
分组命名 和 search遇到分组
标签 .html 网页文件 标签文件
import re
分组的意义
1.对一组正则规则进行量词约束
2.从一整条正则规则匹配的结果中优先显示组内的内容
"<h1>hello</h1>"
ret = re.findall('<\w+>(\w+)</\w+>',"<h1>hello</h1>")
print(ret) 分组命名
ret = re.search("<(?P<tag>\w+)>(?P<content>\w+)</(?P=tag)>","<h1>hello</h1>")
print(ret)
print(ret.group()) # search中没有分组优先的概念
print(ret.group('tag'))
print(ret.group('content')) ret = re.search(r"<(\w+)>(\w+)</\1>","<h1>hello</h1>")
#如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
#获取的匹配结果可以直接用group(序号)拿到对应的值
print(ret.group())
print(ret.group(0)) #结果 :<h1>hello</h1>
print(ret.group(1)) #结果 :h1
print(ret.group(2)) #结果 :hello
0428 正则表达式 re模块的更多相关文章
- python正则表达式Re模块备忘录
title: python正则表达式Re模块备忘录 date: 2019/1/31 18:17:08 toc: true --- python正则表达式Re模块备忘录 备忘录 python中的数量词为 ...
- python 正则表达式re模块
#####################总结############## 优点: 灵活, 功能性强, 逻辑性强. 缺点: 上手难,旦上手, 会爱上这个东西 ...
- python基础之正则表达式 re模块
内容梗概: 1. 正则表达式 2. re模块的使⽤ 3. 一堆练习正则表达式是对字符串串操作的一种逻辑公式. 我们一般使用正则表达式对字符串进行匹配和过滤.使用正则的优缺点: 优点: 灵活,功能性强, ...
- python记录_day23 正则表达式 re模块
一. 正则表达式 使用python的re模块之前应该对正则表达式有一定的了解 正则表达式是对字符串操作的一种逻辑公式.我们一般使用正则表达式对字符串进行匹配和过滤. 正则的优缺点: 优点:灵活, 功能 ...
- Python面试题之Python正则表达式re模块
一.Python正则表达式re模块简介 正则表达式,是一门相对通用的语言.简单说就是:用一系列的规则语法,去匹配,查找,替换等操作字符串,以达到对应的目的:此套规则,就是所谓的正则表达式.各个语言都有 ...
- Python 正则表达式——re模块介绍
Python 正则表达式 re 模块使 Python 语言拥有全部的正则表达式功能,re模块常用方法: re.match函数 re.match从字符串的起始位置匹配,如果起始位置匹配不成功,则matc ...
- 学习django之正则表达式re模块
re(regular expression)模块 正则表达式(regular expression)主要功能是从字符串(string)中通过特定的模式(pattern),搜索想要找到的内容. 一.re ...
- 正则表达式re模块
正则表达式模块re 1. 正则简介 就其本质而言,正则表达式(或 RE)是一种小型的.高度专业化的编程语言, (在Python中)它内嵌在Python中,并通过 re 模块实现.正则表达式模式被 编译 ...
- python正则表达式——re模块
http://blog.csdn.net/zm2714/article/details/8016323 re模块 开始使用re Python通过re模块提供对正则表达式的支持.使用re的一般步骤是先将 ...
随机推荐
- Mysql的建表规范与注意事项
一. 表设计规范 库名.表名.字段名必须使用小写字母,“_”分割. 库名.表名.字段名必须不超过12个字符. 库名.表名.字段名见名知意,建议使用名词而不是动词. 建议使用InnoDB存储引擎. 存储 ...
- 会话管理之Cookie技术
会话管理是web开发中比较重要的环节,这一节主要总结下会话管理中的cookie技术. 1. 何为会话 会话可简单理解为:用户开一个浏览器,点击多个超链接,访问服务器多个web资源,然后关闭浏览器,整个 ...
- RAD Studio XE8 技术研讨会讲义与范例程序下载
感谢各位程序猿亲临现场參加我们的公布会,现奉上会议当天的讲义与范例程序供大家參考: 2015/5/25~27北京.深圳 『RAD Studio XE8技术研讨会』 下载讲义:http://pan ...
- WAS集群系列(3):集群搭建:步骤1:准备文件
说明:"指示轨迹"为"点选顺序",截图为点击后效果截图 环境 项目点 指标 WAS版本号 7.0 操作系统 Windows 2008 系统位数 64bit 内存 ...
- Arcgis:坐标系统极其转换
1. ArcGIS中的坐标系统 ArcGIS中预定义了两套坐标系统,地理坐标系(Geographic coordinate system)和投影坐标系(Projectedcoordinate syst ...
- Git--代码托管/协同开发
Git--代码托管 我爱写代码,公司写,家里写,如果每天来回带一个U盘拷贝着实麻烦,Git有没有类似于云盘似得东西可以进行数据同步呢?答案肯定是有. GitHub,一个基于Git实现的代码托管的平台, ...
- PHP高级工程师的要求
PHP 高级工程师1名,(3年以上工作经验 ) 1.熟悉unix环境编程,如多线程/多进程,IO复用.锁.定时器.新号.信号量.共享内存.消息队列.文件系统2.熟悉php的stream.sock ...
- JSON解析工具-org.json使用教程
转自:http://www.open-open.com/lib/view/open1381566882614.html 一.简介 org.json是Java常用的Json解析工具,主要提供JSONO ...
- listView的异步加载数据
1 public class MainActivity extends Activity { 2 3 private ListView listView; 4 private ArrayList< ...
- 【数据挖掘】聚类之k-means(转载)
[数据挖掘]聚类之k-means 1.算法简述 分类是指分类器(classifier)根据已标注类别的训练集,通过训练可以对未知类别的样本进行分类.分类被称为监督学习(supervised learn ...