solr replication原理探究
无论是垂直搜索,还是通用搜索引擎,对外提供搜索服务其压力都比较大,经常有垂直电商在做活动的时候服务器宕机。对面访问压力比较大的情况,一般的应对方法就是【集群】+【负载均衡】。Solr提供了两种解决方案来对应访问压力。其一是Replication,其一是SolrCloud。
Replication采用了master/slave 模式,用读写分离的思想来提高对外服务能力。但本质上还是单兵作战。Master/slave模式在数据库领域应用广泛,像MySQL,Redis等主流的数据库都实现这一功能。Replication的另一个功能就是数据备份。
SolrCloud采用Zookeeper作为配置中心,对索引数据进行分片(shard),实现了真正的分布式搜索。像Hadoop,HBase,Storm等分布式系统都是建立在Zookeeper基础之上的。
个人认为二者没有谁优谁劣,应用场景不同而已。
本文主要探究Replication的实现原理。
1. Replication的配置
Replication在solrconfig.xml中默认是关闭的,要打开很简单。对于Replication,首先需要确定Solr服务的角色。Solr服务的角色有三种[master],[slave],[repeater]。这三种角色的配置如下:
Master配置:
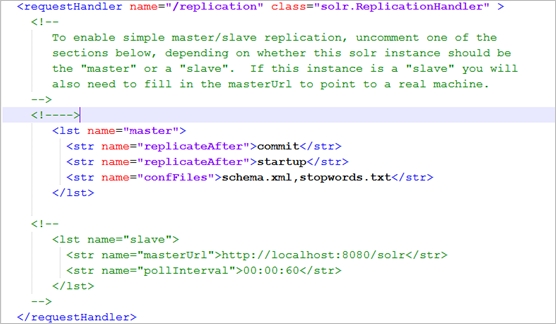
Slave配置:
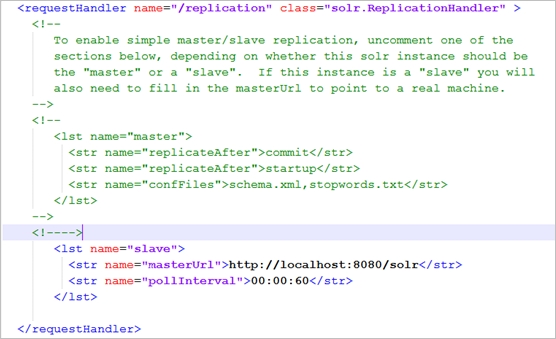
Repeater配置:
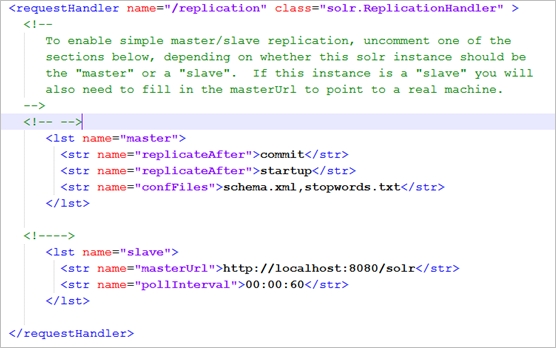
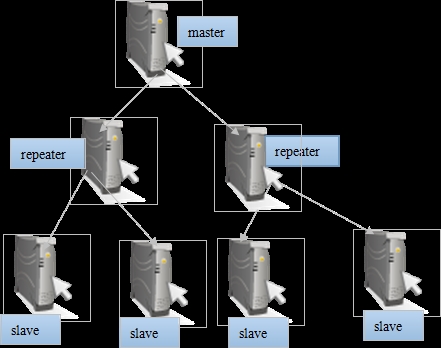
Repeater就是一个solr服务器既是master,又是slave。为什么需要Repeater角色呢?我们试想,如果一个master服务器同时带上10个slave甚至100个slave,会出现什么情况?Master很容易就被累死了。就算不累死,网络带宽也会很容易被占用干净。假如我们需要4台的集群,但是每个master又只能带2台slave,通过repeater就很容易实现。
2. replication的工作原理
通过配置我们知道replication的功能是通过ReplicationHandler来实现的。通过以ReplicationHandler为切入口,应该能很容易地追溯到replication的运行过程。
2.1 slave端的运行过程
Solr在启动的过程中会通过ReplicationHandler.inform()方法,按照slave的配置启动一个定时任务,定时向master端发起同步请求。任务的代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
private void startExecutorService() { Runnable task = new Runnable() { @Override public void run() { if (pollDisabled.get()) { LOG.info("Poll disabled"); return; } try { executorStartTime = System.currentTimeMillis(); replicationHandler.doFetch(null, false); } catch (Exception e) { LOG.error("Exception in fetching index", e); } } }; executorService = Executors.newSingleThreadScheduledExecutor( new DefaultSolrThreadFactory("snapPuller")); long initialDelay = pollInterval - (System.currentTimeMillis() % pollInterval); executorService.scheduleAtFixedRate(task, initialDelay, pollInterval, TimeUnit.MILLISECONDS); LOG.info("Poll Scheduled at an interval of " + pollInterval + "ms"); } |
定时任务的时间间隔是

slave端对master而言是透明的。换句话说,master与slave之间的通信是无状态的http连接。Slave端通过发送不同的command从Server端取得数据,即在数据同步的过程中,slave端是占主导作用的。这也是为什么最好先从slave端入手。
一次replicate操作关键步骤如下:

当然还会有细节的处理,比如系统缓存同步、数据校验,日志记录等等……处理全过程都是以SnapPuller.fetchLatestIndex()方法为主线进行的,如果跟踪源码,则重点关注该方法。
2.2 master端的运行过程
由于master端是被动的(即master接收slave端传递过来的命令,然后依照命令执行),所以master端的工作过程相对比较简单。值得注意的是,通过master端可以更好的理解solr索引更新的过程。
1.CMD_INDEX_VERSION 命令
通过该命令可以得到索引的latestVersion和latestGeneration。其中lastestVersion其实就是索引的更新时间点,而latestGeneration就是存储在SegmentInfos中的generation信息。通过这两个信息的对比,就可以判断出slave端的索引是否需要更新。
2. CMD_GET_FILE_LIST命令
通过该命令可以得到需要同步的索引文件信息。
3. CMD_GET_FILE 命令
通过该命令可以下载文件。该命令执行次数由文件大小和CMD_GET_FILE_LIST得到的文件数量决定。下载文件每次最多下载1M,如果文件大于1M,则分多次下载。数据正确性的校验由Adler32 算法来完成。关于Adler32算法,这里不细说。关于详细代码,可以参看DirectoryFileStream.write()方法。
综上,一次replication操作在master端的运行过程就是执行这三种命令的过程。
solr replication原理探究的更多相关文章
- [原] KVM 虚拟化原理探究(1)— overview
KVM 虚拟化原理探究- overview 标签(空格分隔): KVM 写在前面的话 本文不介绍kvm和qemu的基本安装操作,希望读者具有一定的KVM实践经验.同时希望借此系列博客,能够对KVM底层 ...
- [原] KVM 虚拟化原理探究 —— 目录
KVM 虚拟化原理探究 -- 目录 标签(空格分隔): KVM KVM 虚拟化原理探究(1)- overview KVM 虚拟化原理探究(2)- QEMU启动过程 KVM 虚拟化原理探究(3)- CP ...
- [原] KVM 虚拟化原理探究(6)— 块设备IO虚拟化
KVM 虚拟化原理探究(6)- 块设备IO虚拟化 标签(空格分隔): KVM [toc] 块设备IO虚拟化简介 上一篇文章讲到了网络IO虚拟化,作为另外一个重要的虚拟化资源,块设备IO的虚拟化也是同样 ...
- [原] KVM 虚拟化原理探究(5)— 网络IO虚拟化
KVM 虚拟化原理探究(5)- 网络IO虚拟化 标签(空格分隔): KVM IO 虚拟化简介 前面的文章介绍了KVM的启动过程,CPU虚拟化,内存虚拟化原理.作为一个完整的风诺依曼计算机系统,必然有输 ...
- [原] KVM 虚拟化原理探究(4)— 内存虚拟化
KVM 虚拟化原理探究(4)- 内存虚拟化 标签(空格分隔): KVM 内存虚拟化简介 前一章介绍了CPU虚拟化的内容,这一章介绍一下KVM的内存虚拟化原理.可以说内存是除了CPU外最重要的组件,Gu ...
- [原] KVM 虚拟化原理探究(3)— CPU 虚拟化
KVM 虚拟化原理探究(3)- CPU 虚拟化 标签(空格分隔): KVM [TOC] CPU 虚拟化简介 上一篇文章笼统的介绍了一个虚拟机的诞生过程,从demo中也可以看到,运行一个虚拟机再也不需要 ...
- [原] KVM 虚拟化原理探究(2)— QEMU启动过程
KVM 虚拟化原理探究- QEMU启动过程 标签(空格分隔): KVM [TOC] 虚拟机启动过程 第一步,获取到kvm句柄 kvmfd = open("/dev/kvm", O_ ...
- 弱类型变量原理探究(转载 http://www.csdn.net/article/2014-09-15/2821685-exploring-of-the-php)
N首页> 云计算 [问底]王帅:深入PHP内核(一)——弱类型变量原理探究 发表于2014-09-19 09:00| 13055次阅读| 来源CSDN| 36 条评论| 作者王帅 问底PHP王帅 ...
- js事件底层原理探究
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
随机推荐
- deep learning (六)logistic(逻辑斯蒂)回归中L2范数的应用
zaish上一节讲了线性回归中L2范数的应用,这里继续logistic回归L2范数的应用. 先说一下问题:有一堆二维数据点,这些点的标记有的是1,有的是0.我们的任务就是制作一个分界面区分出来这些点. ...
- Python - Package os
for (path,dirs,files) in os.walk(path): for filename in files: #do something here os. walk(top, topd ...
- hdu--1878--欧拉回路(并查集判断连通,欧拉回路模板题)
题目链接 /* 模板题-------判断欧拉回路 欧拉路径,无向图 1判断是否为连通图, 2判断奇点的个数为0 */ #include <iostream> #include <c ...
- L107
It is advisable to take an open- minded approach to new idea. 对新思想采取不存先入之见的态度是明智的.That said, the com ...
- 高可用-软件heartbeat的入门介绍
注:参考互联网整理. 一.简介Linux-HA的全称是High-Availability Linux,它是一个开源项目,这个开源项目的目标是:通过社区开发者的共同努力,提供一个增强linux可靠性(r ...
- WordPress 中文图片 上传 自动重命名
由于国人很少有在上传图片前将图片名重命名为英语的,所以自动重命名对于WP来说尤为重要,特别是LINUX的不支持中文名的. WordPress上传多媒体的代码都存放于\wp-admin\includes ...
- Linux 下如何调试 Python?
一般开发者都是在 IDE 中进行程序的调试,当然,有 IDE 的话,当然首选 IDE 进行调试. 但是,有时我们的业务场景,限制只能在 Linux 命令行模式进行调试. 这时该怎么办呢? 今天,就给大 ...
- ProjectEuler654
我,ycl:BM是什么早就忘了! 毕老爷:那你们可以做一做这道题练练BM板子啊. 传送门 //Achen #include<bits/stdc++.h> #define For(i,a,b ...
- MSSQL日誌傳輸熱備份注意事項
主次數據庫需要新增一個用戶,並設定agent服務用此用戶執行 主次數據庫需要設定共享目錄並擁有讀/寫權限,用anent執行用戶即可 如果新增日誌傳輸時順便初始化數據庫記得次數據庫主機目錄給寫權限,否則 ...
- 尚硅谷Java视频教程导航(学习路线图)
最近很火,上去看了看,对于入门的人还是有点作用的,做个记号,留着以后学习. Java视频教程下载导航(学习路线图) 网站地址:http://www.atguigu.com/download.shtml