SQL开发中容易忽视的一些小地方(六)
本文主旨:条件列上的索引对数据库delete操作的影响。
事由:今天在博客园北京俱乐部MSN群中和网友讨论了关于索引对delete的影响问题,事后感觉非常汗颜,因为我的随口导致错误连篇。大致话题是这样的,并非原话:
[讨论:] delete course where classID=500001 classID上没有创建任何索引,为了提高删除效率,如果在classID上创建一个非聚集索引会不会提高删除的效率呢?
我当时的观点:不能。
我当时的理由:数据库在执行删除时,如果在classID上创建了非聚集索引,首先按这个非聚集索引查找数据,找到索引行后,根据索引行后面带的聚集索引地址最后找到真正的物理数据行,并且执行删除,这个过程看起来没有作用,只能创建聚集索引来提高删除效率,因为如果classID是聚集索引,那么直接聚集索引删除,此时的效率最高。
下班后对这个话题再次想了下,觉的自己的观点都自相矛盾,既然知道删除时,会在条件列上试图应用已经存在的索引,那么为什么创建非聚集索引会无效呢?如果表的数据相当大,classID上如果没有任何索引,查找数据时就要执行表扫描,而表扫描的速度是相当慢的,为此为了证明下这个问题,我特意做了一个示意性的实验。
创建两个表course 和course2,创建语句如下,它们唯一的区别就在于索引,course表中classID上创建了非聚集索引,而course2上没有创建任何索引。
CREATE TABLE [dbo].[course](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[classID] [int] NULL,
CONSTRAINT [PK_CKH] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
--创建索引
create index IX_classID
on course(classID) CREATE TABLE [dbo].[course2](
[ID] [int] IDENTITY(1,1) NOT NULL,
[sCourseName] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[classID] [int] NULL,
CONSTRAINT [PK_CKH2] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY]
实验过程:
第一步:分别给两个表插入相当的数据1000行,然后删除第500条记录。
delete course
where classID=500
delete course2
where classID=500
执行计划图如下:我们可以看到在执行删除时,数据库分为三部分:
1:查找到要删除的数据行;
2:包含一个top操作。
3:执行聚集索引删除。
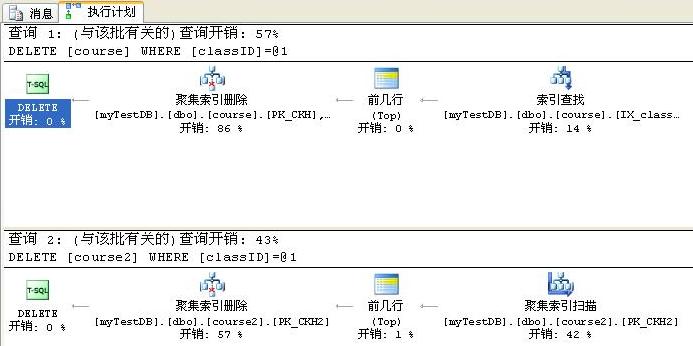
区别一:由于course表的classID上创建了索引,所以查找时按PK_classID来查找,course2表的classID由于没有任何的索引,为了查找到要删除的数据行,就只能按聚集索引查找,此时实际上是全表扫描。
区别二:系统开销不同,让人意外的是,结果表明好像白天的观点是正确的,创建了索引的coure表在开销上比没有创建索引的course2还大一点。
分析区别二的原因:我们来看下聚集索引删除的具体内容,下面是在条件列classID上创建了非聚集索引的表course表在发生删除时的执行计划图,它在删除后需要维护索引PK_classID,占用部分的系统开销。而没有创建索引的表course2由于没有索引维护的额外开销,所以反而占优势。
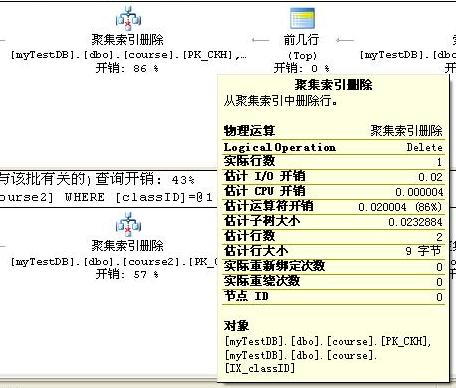
第二步:分别给两个表插入相当的数据10000行,然后删除第5000条记录。
区别同第一步。难道我的观点真的正确?
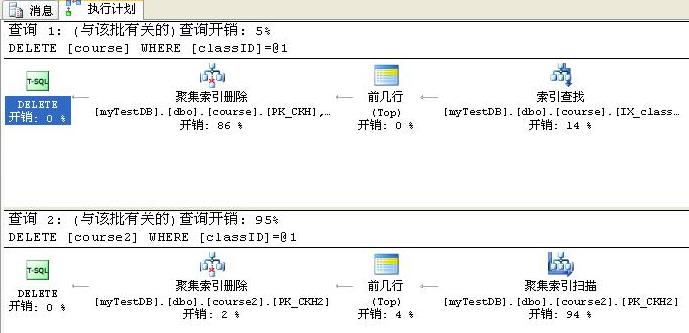
第三步:分别给两个表插入相当的数据100000行,然后删除第50000条记录。执行计划图如下:
区别一:同前两步的区别一。
区别二:系统开销不同,此时会发现创建了索引的course表在开销上占5%,而没有创建索引的course2表占了95%,这可是10倍的区别啊。
第四步:分别给两个表插入相当的数据1000000行,然后删除第500000条记录。
区别同第三步。
总结:当删除语句的条件列没有创建索引时分两种情况:
第一:数据量较小,我测试时在10000以下,此时两者的差别不大,反而会因为创建了索引而引起磁盘开销。开销差距不大是因为数据量小时,即使全表扫描速度也不慢,此时索引的优势并不明显。
第二:数据量较大,我测试时在100000以上,此时两者的差别较大。条件列创建了索引的表明显效率高。
第三:归根结底,系统的主要开销还是在删除的第一步,查找数据行上。能更快查找到删除行的方案效率最高。
SQL开发中容易忽视的一些小地方(六)的更多相关文章
- SQL开发中容易忽视的一些小地方(五)
原文:SQL开发中容易忽视的一些小地方(五) 背景: 索引分类:众所周知,索引分为聚集索引和非聚集索引. 索引优点:加速数据查询. 问题:然而我们真的清楚索引的应用吗?你写的查询语句是否能充分应用上索 ...
- SQL开发中容易忽视的一些小地方(一)
原文:SQL开发中容易忽视的一些小地方(一) 写此系列文章缘由: 做开发三年来(B/S),发现基于web 架构的项目技术主要分两大方面: 第一:C#,它是程序的基础,也可是其它开发语言,没有开发语言也 ...
- SQL开发中容易忽视的一些小地方(二)
原文:SQL开发中容易忽视的一些小地方(二) 目的:继上一篇:SQL开发中容易忽视的一些小地方(一) 总结SQL中的null用法后,本文我将说说表联接查询. 为了说明问题,我创建了两个表,分别是学生信 ...
- SQL开发中容易忽视的一些小地方( 三)
原文:SQL开发中容易忽视的一些小地方( 三) 目的:这篇文章我想说说我在工作中关于in和union all 的用法. 索引定义 : 微软的SQL SERVER提供了两种索引:聚集索引(cluster ...
- SQL开发中容易忽视的一些小地方(四)
原文:SQL开发中容易忽视的一些小地方(四) 本篇我想针对网上一些对于非聚集索引使用场合的某些说法进行一些更正. 下面引用下MSDN对于非聚集索引结构的描述. 非聚集索引结构: 1:非聚集索引与聚集索 ...
- PL/SQL开发中动态SQL的使用方法
一般的PL/SQL程序设计中,在DML和事务控制的语句中可以直接使用SQL,但是DDL语句及系统控制语句却不能在PL/SQL中直接使用,要想实现在PL/SQL中使用DDL语句及系统控制语句,可以通过使 ...
- SQL Server 中关于 @@error 的一个小误区
在SQL Server中,我常常会看到有些前辈这样写: ) ROLLBACK TRANSACTION T else COMMIT TRANSACTION T 一开始,我看见别人这么写,我就想当然的以为 ...
- ASP.NET MVC 开发中遇到的两个小问题
最近在做一个网站,用asp.net MVC4.0来开发,今天遇到了两个小问题,通过查找相关渠道解决了,在这里把这两个问题写出来,问题非常简单,不喜勿喷,mark之希望可以给遇到相同问题的初学者一点帮助 ...
- 微信小程序开发中遇到的几个小问题
本地图片不显示,开发工具运行是没问题的,但真机调试却显示不了 item.img = '/goods/img/图片.png' <image src="{{item.img}}" ...
随机推荐
- Unable to start MySQL service. Another MySQL daemon is already running with the same UNIX socket
Unable to start MySQL service. Another MySQL daemon is already running with the same UNIX socket 特征 ...
- Linux命令之文本处理(二)
cut命令 cut命令用来操作文件的列,能够视为列编辑器:与之相应是大多数的行"编辑器".如sed.grep.sort等,它们操作文本时,以行为单位. cut的主要功能就是输出文本 ...
- 和学生探讨吉林大学python问题
学生们真的很强大,我知道玩微信,nodejs.... 我们去学校了解.当时互联网开始64K....
- OpenMp高速分拣
#include <stdio.h> #include<stdafx.h> #include<iostream> #include <stdlib.h> ...
- Cocos2d-x 3.2 Lua演示样例 XMLHttpRequestTest(Http网络请求)
Cocos2d-x 3.2 Lua演示样例 XMLHttpRequestTest(Http网络请求) 本篇博客介绍Cocos2d-x 3.2Lua演示样例中的XMLHttpRequestTes ...
- ios ios7 取消控制拉升
//推断是否ios7 取消控制拉升 if ([[UIDevice currentDevice].systemVersion doubleValue] >= 7.0) { self.edgesFo ...
- LinearLayout具体解释一:LinearLayout的简单介绍
LinearLayout,中文意思是线性布局.假设你是初学android的,肯定会非常困惑"啥叫布局",啥又叫"线性布局"呢. 有的时候,我尝试用官方的语言去解 ...
- Directx11学习笔记【二十】 使用DirectX Tool Kit加载mesh
本文由zhangbaochong原创,转载请注明出处:http://www.cnblogs.com/zhangbaochong/p/5788482.html 现在directx已经不再支持.x文件了, ...
- 【Linux探索之旅】第二部分第二课:命令行,世界尽在掌握
内容简介 1.第二部分第二课:命令行,世界尽在掌握 2.第二部分第三课预告:文件和目录,组织不会亏待你 命令行,世界尽在掌握 今天的标题是不是有点霸气侧漏呢? 读者:“小编,你为什么每次都要起这么非主 ...
- How to install PL/SQL developer on linux (转)
PL/SQL developer 在linux上的安装方法工欲善其事必先利其器,PL/SQL和toad对于ORACLE从业人员来说都是很重要的工具,但这些工具都没有linux的发行版,如果要在linu ...