SQL Server-聚焦计算列或计算列持久化查询性能(二十二)
前言
上一节我们详细讲解了计算列以及计算列持久化的问题,本节我们依然如前面讲解来看看二者查询性能问题,简短的内容,深入的理解,Always to review the basics。
持久化计算列比非持久化计算列性能要好
我们开始创建两个一样的表并都插入条数据来进行比较,对于计算列我们重新进行创建计算列和非计算列持久化。
CREATE TABLE [dbo].[ComputeColumnCompare] (ID INT,
FirstName VARCHAR(),
LastName CHAR())
GO
INSERT INTO [dbo].[ComputeColumnCompare] (ID,FirstName,LastName)
SELECT TOP ROW_NUMBER() OVER (ORDER BY a.name) RowID,
'Bob',
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)% = THEN 'Smith'
ELSE 'Brown' END
FROM sys.all_objects a
CROSS JOIN sys.all_objects b
GO
在ComputeColumn表上创建计算列
USE TSQL2012
GO ALTER TABLE dbo.ComputeColumn ADD
FullName AS POWER(LEN(LEFT((FirstName+CAST(ID AS VARCHAR())),)), )
GO
在ComputeColumnCompare表上创建计算持久化列
USE TSQL2012
GO ALTER TABLE dbo.ComputeColumnCompare ADD
FullName_P AS POWER(LEN(LEFT((FirstName+CAST(ID AS VARCHAR())),)), ) PERSISTED
GO
此时我们来运行两个表对计算列和计算列持久化列的查询
USE TSQL2012
GO SELECT FullName
FROM dbo.ComputeColumn
WHERE FullName =
GO
SELECT FullName_P
FROM dbo.ComputeColumnCompare
WHERE FullName_P =
GO
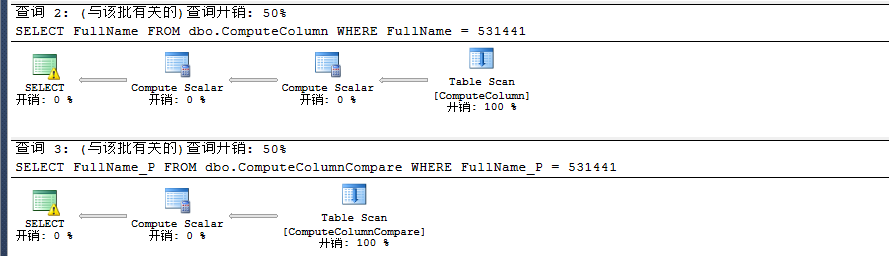
此时二者的开销是一样的,只是非持久化列多了一个Compute Scalar操作,主要是因为它计算值是在运行时,此时我们来看看操作成本。
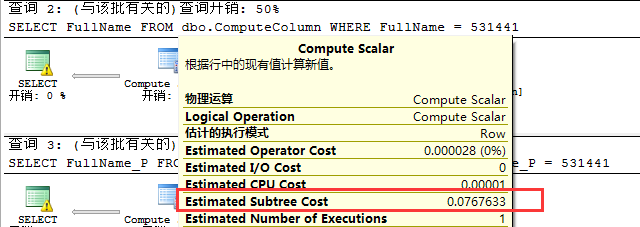

我们看到二者性能还是有一点差异,所以我们能够知道如果计算操作比较复杂时利用持久化来提前进行计算性能会比非持久化列更好。是不是所有情况下持久化列性能都比持久化列性能要好呢?继续往下看。
非持久化计算列比持久化计算列性能要好
我们再来创建测试表并插入1万条数据来进行比较。
USE TSQL2012
GO CREATE TABLE [dbo].[ComputeColumn] (ID INT,
FirstName VARCHAR(),
LastName CHAR())
GO
CREATE TABLE [dbo].[ComputeColumnCompare](ID INT,
FirstName VARCHAR(),
LastName CHAR())
GO
USE TSQL2012
GO INSERT INTO [dbo].[ComputeColumn](ID,FirstName,LastName)
SELECT TOP ROW_NUMBER() OVER (ORDER BY a.name) RowID,
'Bob',
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)% = THEN 'Smith'
ELSE 'Brown' END
FROM sys.all_objects a
CROSS JOIN sys.all_objects b
GO
INSERT INTO [dbo].[ComputeColumnCompare](ID,FirstName,LastName)
SELECT TOP ROW_NUMBER() OVER (ORDER BY a.name) RowID,
'Bob',
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)% = THEN 'Smith'
ELSE 'Brown' END
FROM sys.all_objects a
CROSS JOIN sys.all_objects b
GO
接下来在两表上创建持久化计算列和非持久化计算列
USE TSQL2012
GO ALTER TABLE dbo.ComputeColumn ADD
FullName AS (FirstName+' '+LastName)
GO ALTER TABLE dbo.ComputeColumnCompare ADD
FullName_P AS (FirstName+' '+LastName) PERSISTED
GO
最后我们进行查询看看查询计划结果
USE TSQL2012
GO SELECT FullName
FROM dbo.ComputeColumn
WHERE FullName = 'Bob Smith'
GO
SELECT FullName_P
FROM dbo.ComputeColumnCompare
WHERE FullName_P = 'Bob Smith'
GO

到这里我们发现非持久化计算列性能要比持久化计算列性能要好,和上面对照的话我已经明确进行了标记定义列的大小以及插入行的多少是不同的,所以对于持久化列和非持久化列二者并没有绝对性能的谁好谁好,当我们想要看二者谁性能更佳时,我们可能需要考虑定义列的大小、数据行的多少等等。下面我们还看最后一种情况,就是在计算列上来创建索引。
非持久化计算列提高查询性能
我们继续创建测试表
USE TSQL2012
GO CREATE TABLE [dbo].[ComputeColumn] (ID INT,
FirstName VARCHAR(),
LastName VARCHAR())
GO
CREATE TABLE [ComputeColumnCompare] (ID INT,
FirstName VARCHAR(),
LastName VARCHAR())
GO
USE TSQL2012
GO INSERT INTO [dbo].[ComputeColumn] (ID,FirstName,LastName)
SELECT TOP ROW_NUMBER() OVER (ORDER BY a.name) RowID,
'Bob',
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)% = THEN 'Smith'
ELSE 'Brown' END
FROM sys.all_objects a
CROSS JOIN sys.all_objects b
GO
INSERT INTO [dbo].[ComputeColumnCompare](ID,FirstName,LastName)
SELECT TOP ROW_NUMBER() OVER (ORDER BY a.name) RowID,
'Bob',
CASE WHEN ROW_NUMBER() OVER (ORDER BY a.name)% = THEN 'Smith'
ELSE 'Brown' END
FROM sys.all_objects a
CROSS JOIN sys.all_objects b
GO
在ComputeColumn表上创建计算列并创建一个非聚集索引
ALTER TABLE dbo.ComputeColumn ADD
FullName AS (FirstName+' '+LastName)
GO CREATE NONCLUSTERED INDEX IX_CompCol_CityTrim
ON dbo.ComputeColumn (FullName)
GO
在ComputeColumnCompare表上创建计算列
ALTER TABLE dbo.ComputeColumnCompare ADD
FullName_P AS (FirstName+' '+LastName)
GO
最后查询两个表看看查询计划结果
USE TSQL2012
GO SELECT FullName
FROM dbo.ComputeColumn
WHERE FullName = 'Bob Smith'
GO
SELECT FullName_P
FROM dbo.ComputeColumnCompare
WHERE FullName_P = 'Bob Smith'
GO

从上述我们知道对计算列创建一个索引能很好的提高查询性能,当然了上述仅仅只是返回计算列,若返回其他列的话可能会导致Key Lookup,但是从另外一个角度来讲还是能提高查询性能,为了解决Key Lookup问题建立太多索引也是有问题的,具体情况具体分析吧。这里并没有比较持久化计算列和非持久化计算列的性能,二者其实是一样的,就没有比较了,只是在利用持久化在数据存储上不同而已。参考资料:【http://blog.sqlauthority.com/2010/08/03/sql-server-computed-column-persisted-and-performance/】
总结
到此我们算是结束了对于计算列以及关于计算列持久的概念和性能的分析,下节我们再看看其他查询的知识,接着就进入表表达式的学习,简短的内容,深入的理解,我们下节再会。
SQL Server-聚焦计算列或计算列持久化查询性能(二十二)的更多相关文章
- 在SQL Server 2014里可更新的列存储索引 (Updateable Column Store Indexes)
传统的关系数据库服务引擎往往并不是对超大量数据进行分析计算的最佳平台,为此,SQL Server中开发了分析服务引擎去对大笔数据进行分析计算.当然,对于数据的存放平台SQL Server数据库引擎而言 ...
- 第16/24周 SQL Server 2014中的基数计算
大家好,欢迎回到性能调优培训.上个星期我们讨论在SQL Server里基数计算过程里的一些问题.今天我们继续详细谈下,SQL Server 2014里引入的新基数计算. 新基数计算 SQL Serve ...
- Expression构建DataTable to Entity 映射委托 sqlserver 数据库里面金额类型为什么不建议用float,实例告诉你为什么不能。 sql server 多行数据合并成一列 C# 字符串大写转小写,小写转大写,数字保留,其他除外 从0开始用U盘制作启动盘装Windows10系统(联想R720笔记本)并永久激活方法 纯CSS打造淘宝导航菜单栏 C# Winform
Expression构建DataTable to Entity 映射委托 1 namespace Echofool.Utility.Common { 2 using System; 3 using ...
- 向SQL Server 现有表中添加新列并添加描述.
注: sql server 2005 及以上支持. 版本估计是不支持(工作环境2005,2008). 工作需要, 需要向SQL Server 现有表中添加新列并添加描述. 从而有个如下存储过程. (先 ...
- SQL Server调优系列基础篇(子查询运算总结)
前言 前面我们的几篇文章介绍了一系列关于运算符的介绍,以及各个运算符的优化方式和技巧.其中涵盖:查看执行计划的方式.几种数据集常用的连接方式.联合运算符方式.并行运算符等一系列的我们常见的运算符.有兴 ...
- sql server 使用链接服务器连接Oracle,openquery查询数据
对接问题描述:不知道正式库oracle数据库账户密码,对方愿意在对方的客户端上输入账号和密码,但不告诉我们 解决方案:使用一台sql server作为中间服务器,可以通过转存数据到sql serv ...
- sql:sql server,MySQL,PostgreSQL的表,视图,存储过程结构查询
sql server 2005: --SQL SERVER 2005 生成代码需要知道的SQL语句 use LibrarySystem --查询当前数据库所有表和其的主键字段,字段类型,长度,是否为空 ...
- SQL Server 执行计划利用统计信息对数据行的预估原理二(为什么复合索引列顺序会影响到执行计划对数据行的预估)
本文出处:http://www.cnblogs.com/wy123/p/6008477.html 关于统计信息对数据行数做预估,之前写过对非相关列(单独或者单独的索引列)进行预估时候的算法,参考这里. ...
- 在一个SQL Server表中的多个列找出最大值
在一个SQL Server表中一行的多个列找出最大值 有时候我们需要从多个相同的列里(这些列的数据类型相同)找出最大的那个值,并显示 这里给出一个例子 IF (OBJECT_ID('tempdb..# ...
随机推荐
- [翻译]开发文档:android Bitmap的高效使用
内容概述 本文内容来自开发文档"Traning > Displaying Bitmaps Efficiently",包括大尺寸Bitmap的高效加载,图片的异步加载和数据缓存 ...
- C# 多种方式发送邮件(附帮助类)
因项目业务需要,需要做一个发送邮件功能,查了下资料,整了整,汇总如下,亲测可用- QQ邮箱发送邮件 #region 发送邮箱 try { MailMessage mail = new MailMess ...
- 阿里云服务器上配置并使用: PHP + Redis + Mysql 从配置到使用
(原创出处为本博客,http://www.cnblogs.com/linguanh/) 目录: 一,下载 二,解压 三,配置与启动 四,测试 Redis 五,配置 phpRedis 扩展 六,综合测试 ...
- 《你不知道的JavaScript》整理(四)——原型
一.[[Prototype]] JavaScript中的对象有一个特殊的[[Prototype]]内置属性,其实就是对于其他对象的引用. var myObject = { a: 2 }; myObje ...
- Java列表
Java列表踩过的坑 其中subList是RandomAccessSubList,不是序列化的列表,不可以加入tair. 加入tair测试代码 @Autowired private CacheMana ...
- 【干货分享】流程DEMO-人员调动流程
流程名: 调动 流程相关文件: 流程包.xml 流程说明: 直接导入流程包文件,即可使用本流程 表单: 流程: 图片:3.png DEMO包下载: http://files.cnblogs.com ...
- 【干货分享】流程DEMO-固定资产转移流程
流程名: 固定资产转移 业务描述: 固定资产从某员工转移至另一员工,转出人与转入人必须不同 流程相关文件: 流程包.xml 流程说明: 直接导入流程包文件,即可使用本流程 表单: 流程: ...
- Configure a VLAN (on top of a bond) with NetworkManager (nmcli) in RHEL7
not on top of a bond Environment Red Hat Enterprise Linux 7 NetworkManager Issue Need an 802.1q VLAN ...
- Linux 安装Mono环境 运行ASP.NET(一)
1.先看一下Linux环境下面请求的过程,(画的不是很好,简单的了解一下原理.) .NET跨平台其实需要这三个关键:编译器.CLR和基础类库.在.NET下我们编写一个最简单的"Hello W ...
- 一步步开发自己的博客 .NET版(3、注册登录功能)
前言 这次开发的博客主要功能或特点: 第一:可以兼容各终端,特别是手机端. 第二:到时会用到大量html5,炫啊. 第三:导入博客园的精华文章,并做分类.(不要封我) 第四:做 ...