SQLAlchemy 学习笔记(一):Engine 与 SQL 表达式语言
个人笔记,如有错误烦请指正。
SQLAlchemy 是一个用 Python 实现的 ORM (Object Relational Mapping)框架,它由多个组件构成,这些组件可以单独使用,也能独立使用。它的组件层次结构如下:
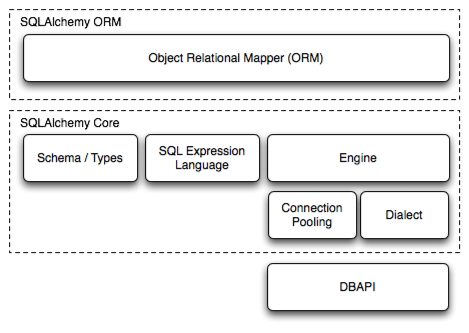
其中最常用的组件,应该是 ORM 和 SQL 表达式语言,这两者既可以独立使用,也能结合使用。
ORM 的好处在于它
- 自动处理了数据库和 Python 对象之间的映射关系,屏蔽了两套系统之间的差异。程序员不需要再编写复杂的 SQL 语句,直接操作 Python 对象就行。
- 屏蔽了各数据库之间的差异,更换底层数据库不需要修改 SQL 语句,改下配置就行。
- 使数据库结构文档化,models 定义很清晰地描述了数据库的结构。
- 避免了不规范、冗余、风格不统一的 SQL 语句,可以避免很多人为 Bug,也方便维护。
但是 ORM 需要消耗额外的性能来处理对象关系映射,此外用 ORM 做多表关联查询或复杂 SQL 查询时,效率低下。因此它适用于场景不太复杂,性能要求不太苛刻的场景。
都说 ORM 学习成本高,我自己也更倾向于直接使用 SQL 语句(毕竟更熟悉),因此这一篇笔记不涉及 ORM 部分,只记录 SQLAlchemy 的 Engine 与 SQL 表达式语言。
一、直接使用 Engine 和 Connections
第一步是创建数据库引擎实例:
from sqlalchemy import create_engine
engine = create_engine('sqlite:///:memory:',
echo=True, # echo=True 表示打印出自动生成的 SQL 语句(通过 logging)
pool_size=5, # 连接池容量,默认为 5,生产环境下太小,需要修改。
# 下面是 connection 回收的时间限制,默认 -1 不回收
pool_recycle=7200) # 超过 2 小时就重新连接(MySQL 默认的连接最大闲置时间为 8 小时)
create_engine 接受的第一个参数是数据库 URI,格式为 dialect+driver://username:password@host:port/database,dialect 是具体的数据库名称,driver 是驱动名称。key-value 是可选的参数。举例:
# PostgreSQL
postgresql+psycopg2://scott:tiger@localhost/dbtest
# MySQL + PyMySQL(或者用更快的 mysqlclient)
mysql+pymysql://scott:tiger@localhost/dbtest
# sqlite 内存数据库
# 注意 sqlite 要用三个斜杠,表示不存在 hostname,sqlite://<nohostname>/<path>
sqlite:///:memory:
# sqlite 文件数据库
# 四个斜杠是因为文件的绝对路径以 / 开头:/home/ryan/Codes/Python/dbtest.db
sqlite:////home/ryan/Codes/Python/dbtest.db
# SQL Server + pyodbc
# 首选基于 dsn 的连接,dsn 的配置请搜索hhh
mssql+pyodbc://scott:tiger@some_dsn
如果你的密码中含有 '@' 等特殊字符,就不能直接放入 URI 中,必须使用 urllib.parse.quote_plus 编码,然后再插入 URI.
引擎创建后,我们就可以直接获取 connection,然后执行 SQL 语句了。这种用法相当于把 SQLAlchemy 当成带 log 的数据库连接池使用:
with engine.connect() as conn:
res = conn.execute("select username from users") # 无参直接使用
# 使用问号作占位符,前提是下层的 DBAPI 支持。更好的方式是使用 text(),这个后面说
conn.execute("INSERT INTO table (id, value) VALUES (?, ?)", 1, "v1") # 参数不需要包装成元组
# 查询返回的是 ResultProxy 对象,有和 dbapi 相同的 fetchone()、fetchall()、first() 等方法,还有一些拓展方法
for row in result:
print("username:", row['username'])
但是要注意的是,connection 的 execute 是自动提交的(autocommit),这就像在 shell 里打开一个数据库客户端一样,分号结尾的 SQL 会被自动提交。
只有在 BEGIN TRANSACTION 内部,AUTOCOMMIT 会被临时设置为 FALSE,可以通过如下方法开始一个内部事务:
def transaction_a(connection):
trans = connection.begin() # 开启一个 transaction
try:
# do sthings
trans.commit() # 这里需要手动提交
except:
trans.rollback() # 出现异常则 rollback
raise
# do other things
with engine.connect() as conn:
transaction_a(conn)
1. 使用 text() 构建 SQL
相比直接使用 string,text() 的优势在于它:
- 提供了统一的参数绑定语法,与具体的 DBAPI 无关。
# 1. 参数绑定语法
from sqlalchemy import text
result = connection.execute(
# 使用 :key 做占位符
text('select * from table where id < :id and typeName=:type'),
{'id': 2,'type':'USER_TABLE'}) # 用 dict 传参数,更易读
# 2. 参数类型指定
from sqlalchemy import DateTime
date_param=datetime.today()+timedelta(days=-1*10)
sql="delete from caw_job_alarm_log where alarm_time<:alarm_time_param"
# bindparams 是 bindparam 的列表,bindparam 则提供参数的一些额外信息(类型、值、限制等)
t=text(sql, bindparams=[bindparam('alarm_time_param', type_=DateTime, required=True)])
connection.execute(t, {"alarm_time_param": date_param})
- 可以很方便地转换 Result 中列的类型
stmt = text("SELECT * FROM table",
# 使用 typemap 指定将 id 列映射为 Integer 类型,name 映射为 String 类型
typemap={'id': Integer, 'name': String},
)
result = connection.execute(stmt)
# 对多个查询结果,可以用 for obj in result 遍历
# 也可用 fetchone() 只获取一个
二、SQL 表达式语言
复杂的 SQL 查询可以直接用 raw sql 写,而增删改一般都是单表操作,用 SQL 表达式语言最方便。
SQLAlchemy 表达式语言是一个使用 Python 结构表示关系数据库结构和表达式的系统。
1. 定义并创建表
SQL 表达式语言使用 Table 来定义表,而表的列则用 Column 定义。Column 总是关联到一个 Table 对象上。
一组 Table 对象以及它们的子对象的集合就被称作「数据库元数据(database metadata)」。metadata 就像你的网页分类收藏夹,相关的 Table 放在一个 metadata 中。
下面是创建元数据(一组相关联的表)的例子,:
from sqlalchemy import Table, Column, Integer, String, MetaData, ForeignKey
metadata = MetaData() # 先创建元数据(收藏夹)
users = Table('user', metadata, # 创建 user 表,并放到 metadata 中
Column('id', Integer, primary_key=True),
Column('name', String),
Column('fullname', String)
)
addresses = Table('address', metadata,
Column('id', Integer, primary_key=True),
Column('user_id', None, ForeignKey('user.id')), # 外键约束,引用 user 表的 id 列
Column('email_address', String, nullable=False)
)
metadata.create_all(engine) # 使用 engine 创建 metadata 内的所有 Tables(会检测表是否已经存在,所以可以重复调用)
表定义中的约束
应该给所有的约束命名,即为
name参数指定一个不冲突的列名。详见 The Importance of Naming Constraints
表还有一个属性:约束条件。下面一一进行说明。
- 外键约束:用于在删除或更新某个值或行时,对主键/外键关系中一组数据列强制进行的操作限制。
- 用法一:
Column('user_id', None, ForeignKey('user.id')),直接在Column中指定。这也是最常用的方法 - 用法二:通过
ForeignKeyConstraint(columns, refcolumns)构建约束,作为参数传给Table.
- 用法一:
item = Table('item', metadata, # 商品 table
Column('id', Integer, primary_key=True),
Column('name', String(60), nullable=False),
Column('invoice_id', Integer, nullable=False), # 发票 id,是外键
Column('ref_num', Integer, nullable=False),
ForeignKeyConstraint(['invoice_id', 'ref_num'], # 当前表中的外键名称
['invoice.id', 'invoice.ref_num']) # 被引用的外键名称的序列(被引用的表)
)
on delete与on update:外键约束的两个约束条件,通过ForeignKey()或ForeignKeyConstraint()的关键字参数ondelete/onupdate传入。
可选值有:- 默认行为
NO ACTION:什么都不做,直接报错。 CASCADE:删除/更新 父表数据时,从表数据会同时被 删除/更新。(无报错)RESTRICT:不允许直接 删除/更新 父表数据,直接报错。(和默认行为基本一致)SET NULLorSET DEFAULT:删除/更新 父表数据时,将对应的从表数据重置为NULL或者默认值。
- 默认行为
- 唯一性约束:
UniqueConstraint('col2', 'col3', name='uix_1'),作为参数传给Table. - CHECK 约束:
CheckConstraint('col2 > col3 + 5', name='check1'), 作为参数传给Table. - 主键约束:不解释
- 方法一:通过
Column('id', Integer, primary_key=True)指定主键。(参数primary_key可在多个Column上使用) - 方法二:使用
PrimaryKeyConstraint
- 方法一:通过
from sqlalchemy import PrimaryKeyConstraint
my_table = Table('mytable', metadata,
Column('id', Integer),
Column('version_id', Integer),
Column('data', String(50)),
PrimaryKeyConstraint('id', 'version_id', name='mytable_pk')
)
2. 增删改查语句
- 增:
# 方法一,使用 values 传参
ins = users.insert().values(name="Jack", fullname="Jack Jones") # 可以通过 str(ins) 查看自动生成的 sql
connection.execute(ins)
# 方法二,参数传递给 execute()
conn.execute(users.insert(), id=2, name='wendy', fullname='Wendy Williams')
# 方法三,批量 INSERT,相当于 executemany
conn.execute(addresses.insert(), [ # 插入到 addresses 表
{'user_id': 1, 'email_address': 'jack@yahoo.com'}, # 传入 dict 列表
{'user_id': 1, 'email_address': 'jack@msn.com'},
{'user_id': 2, 'email_address': 'www@www.org'},
{'user_id': 2, 'email_address': 'wendy@aol.com'}
])
# 此外,通过使用 bindparam,INSERT 还可以执行更复杂的操作
stmt = users.insert() \
.values(name=bindparam('_name') + " .. name") # string 拼接
conn.execute(stmt, [
{'id':4, '_name':'name1'},
{'id':5, '_name':'name2'},
{'id':6, '_name':'name3'},
])
- 删:
_table.delete() \
.where(_table.c.f1==value1) \
.where(_table.c.f2==value2) # where 指定条件
- 改:
# 举例
stmt = users.update() \
.where(users.c.name == 'jack') \
.values(name='tom')
conn.execute(stmt)
# 批量更新
stmt = users.update() \
.where(users.c.name == bindparam('oldname')) \
.values(name=bindparam('newname'))
conn.execute(stmt, [
{'oldname':'jack', 'newname':'ed'},
{'oldname':'wendy', 'newname':'mary'},
{'oldname':'jim', 'newname':'jake'},
])
可以看到,所有的条件都是通过 where 指定的,它和后面 ORM 的 filter 接受的参数是一样的。(详细的会在第二篇文章里讲)
- 查
from sqlalchemy.sql import select
# 1. 字段选择
s1 = select([users]) # 相当于 select * from users
s2 = select([users.c.name, users.c.fullname]) # 这个就是只 select 一部分
# 2. 添加过滤条件
s3 = select([users]) \
.where(users.c.id == addresses.c.user_id)
res = conn.execute(s1)
# 可用 for row in res 遍历结果集,也可用 fetchone() 只获取一行
查询返回的是 ResultProxy 对象,这是 SQLAlchemy 对 Python DB-API 的 cursor 的一个封装类,要从中获取结果行,主要有下列几个方法:
row1 = result.fetchone() # 对应 cursor.fetchone()
row2 = result.fetchall() # 对应 cursor.fetchall()
row3 = result.fetchmany(size=3) # 对应 cursor.fetchmany(size=3)
row4 = result.first() # 获取一行,然后立即调用 result 的 close() 方法
col = row[mytable.c.mycol] # 获取 mycol 这一列
result.rowcount # 结果集的行数
同时,result 也实现了 next protocol,因此可以直接用 for 循环遍历
where 进阶
通过使用 or_、and_、in_ model.join 等方法,where 可以构建更复杂的 SQL 语句。
from sqlalchemy.sql import and_, or_, not_
s = select([(users.c.fullname +
", " + addresses.c.email_address).
label('title')]).\
where(users.c.id == addresses.c.user_id).\
where(users.c.name.between('m', 'z')).\
where(
or_(
addresses.c.email_address.like('%@aol.com'),
addresses.c.email_address.like('%@msn.com')
)
)
链接
SQLAlchemy 学习笔记(一):Engine 与 SQL 表达式语言的更多相关文章
- SQLAlchemy 学习笔记(二):ORM
照例先看层次图 一.声明映射关系 使用 ORM 时,我们首先需要定义要操作的表(通过 Table),然后再定义该表对应的 Python class,并声明两者之间的映射关系(通过 Mapper). 方 ...
- SQLAlchemy 学习笔记(三):ORM 中的关系构建
个人笔记,不保证正确. 关系构建:ForeignKey 与 relationship 关系构建的重点,在于搞清楚这两个函数的用法.ForeignKey 的用法已经在 SQL表达式语言 - 表定义中的约 ...
- golang学习笔记13 Golang 类型转换整理 go语言string、int、int64、float64、complex 互相转换
golang学习笔记13 Golang 类型转换整理 go语言string.int.int64.float64.complex 互相转换 #string到intint,err:=strconv.Ato ...
- Docker学习笔记之--安装mssql(Sql Server)并使用Navicat连接测试(环境:centos7)
前一节演示如何使用Nginx反向代理 .net Core项目容器,地址:Docker学习笔记之-部署.Net Core 3.1项目到Docker容器,并使用Nginx反向代理(CentOS7)(二) ...
- sql注入学习笔记,什么是sql注入,如何预防sql注入,如何寻找sql注入漏洞,如何注入sql攻击 (原)
(整篇文章废话很多,但其实是为了新手能更好的了解这个sql注入是什么,需要学习的是文章最后关于如何预防sql注入) (整篇文章废话很多,但其实是为了新手能更好的了解这个sql注入是什么,需要学习的是文 ...
- Oracle学习笔记十 使用PL/SQL
PL/SQL 简介 PL/SQL 是过程语言(Procedural Language)与结构化查询语言(SQL)结合而成的编程语言,是对 SQL 的扩展,它支持多种数据类型,如大对象和集合类型,可使用 ...
- [读书笔记]C#学习笔记六: C#3.0Lambda表达式及Linq解析
前言 最早使用到Lambda表达式是因为一个需求:如果一个数组是:int[] s = new int[]{1,3,5,9,14,16,22};例如只想要这个数组中小于15的元素然后重新组装成一个数组或 ...
- JAVA jdbc(数据库连接池)学习笔记(二) SQL注入
PS:今天偶然间发现了SQL的注入...所以就简单的脑补了一下,都是一些简单的例子...这篇写的不怎么样...由于自己没有进行很深的研究... 学习内容: 1.SQL注入的概念... 所谓SQL注 ...
- C#学习笔记五: C#3.0Lambda表达式及Linq解析
最早使用到Lambda表达式是因为一个需求:如果一个数组是:int[] s = new int[]{1,3,5,9,14,16,22};例如只想要这个数组中小于15的元素然后重新组装成一个数组或者直接 ...
随机推荐
- Restframework的版本及分页
1.版本 1.1基于url的get传参方式 1.创建django项目(起名我的是version),再创建一个app01应用 创建完成,通过python3 manage.py startapp api ...
- ATK-DataPortal 设计框架(三)
边界清晰.服务自治.契约共享.基于策略的兼容性,是面向对向设计时四个基本原则,我们的应用可能分布在不同的环境之中,应用可能在同一服务器中,也可能在不同的网络环境中,保证框架的基类能在不同环境中仍然可用 ...
- sql*plus
[sql*plus创建txt文档编辑sql语句] (1)创建一个txt,命名doc SQL> ed doc; /*ed 文件名*/ (2)在doc.txt文件编辑sql语 ...
- 解决model属性与系统重名
.h .m + (NSDictionary *)replacedKeyFromPropertyName { return @{ @"detailId" : @"id&qu ...
- c#常用数据库封装再次升级
c#封装的几类数据库操作: 1.sqilte 2.berkeleydb 3.一般数据库 4.redis 包含其他项目: 1.序列化 2.通信 3.自定义数据库连接池 再次升级内容: 1.新增redis ...
- ABAP术语-Interface Parameter
Interface Parameter 原文:http://www.cnblogs.com/qiangsheng/archive/2008/02/26/1081800.html Parameter t ...
- dedecms添加/编辑文章如何把附加选项去掉默认勾选状态
1.去掉添加时默认勾选状态. 在 系统->系统基本参数->其它选项 中,如图中的三个选项选择否即可. 设置完后可以看到添加时已经默认不勾选,但是编辑文章时还是默认勾选状态. 2.去掉编辑时 ...
- flask之route中的参数
flask的路由中有一些参数 使用案例 from flask import Flask, render_template, url_for, session, request, redirect ap ...
- MIP组件开发 自定义js组件开发步骤
什么是百度MIP? MIP(Mobile Instant Pages - 移动网页加速器)主要用于移动端页面加速 官网参考:https://www.mipengine.org/doc/00-mip-1 ...
- C# 隐藏窗口标题栏、隐藏任务栏图标
//没有标题 this.FormBorderStyle = FormBorderStyle.None; //任务栏不显示 this.ShowInTaskbar = false;