决策树--Python
决策树
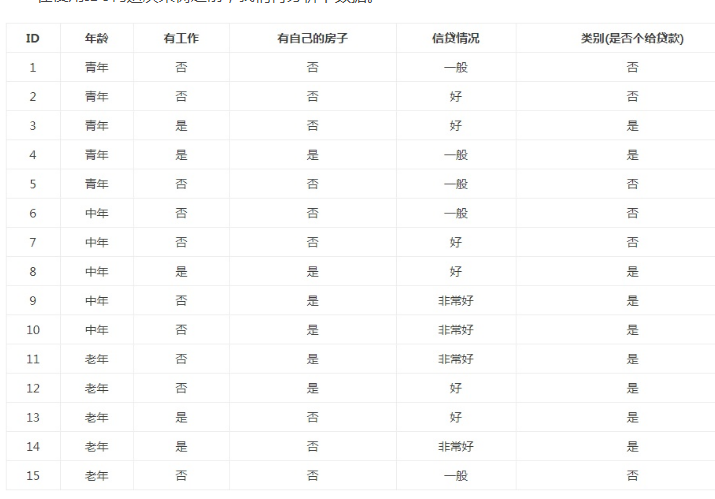
实验集数据:
#coding:utf8 #关键词:决策树(desision tree)、特征选择、信息增益(information gain)、香农熵、熵(entropy)、经验熵(H(D))、节点(node)、有向边(directed edge)、根节点(root node)、叶节点(leaf node)、判断模块(decision block)、终止模块(terminating block)、分支(branch)、最优特征、 import requests
import requests, json, time, re, os, sys, time
import codecs
import shutil
from sgmllib import SGMLParser
from pyquery import PyQuery as pq
from lxml import etree
import urllib2
import json
import random
#from math import log
import math
sys.path.append('/home/shutong/crawl/script/media')
from tools import * from numpy import *
import operator reload(sys)
sys.setdefaultencoding("utf-8") #年龄:0代表青年,1代表中年,2代表老年;
#有工作:0代表否,1代表是;
#有自己的房子:0代表否,1代表是;
#信贷情况:0代表一般,1代表好,2代表非常好;
#类别(是否给贷款):no代表否,yes代表是 def createDataSet():
dataSet = [[0,0,0,0,'no'],[0,0,0,1,'no'],[0,1,0,1,'yes'],[0,1,1,0,'yes'],[0,0,0,0,'no'],[1,0,0,0,'no'],[1,0,0,1,'no'],[1,1,1,1,'yes'],[1,0,1,2,'yes'],[1,0,1,2,'yes'],[2,0,1,2,'yes'],[2,0,1,1,'yes'],[2,1,0,1,'yes'],[2,1,0,2,'yes'],[2,0,0,0,'no']]
#labels = ['不放贷','放贷']
labels = ['年龄', '有工作', '有自己的房子', '信贷情况']
return dataSet,labels #计算经验熵
#输入:dataSet
#输出:经验熵(香农熵)
def calcShannonEnt(dataSet):
#print dataSet
#返回数据集的行数
numEntires = len(dataSet)
#保存每个标签(Label)出现次数的字典
labelCounts = {}
#对每组特征向量进行统计
for featVec in dataSet:
#提取标签(Label)信息
currentLabel = featVec[-1]
#如果标签(Label)没有放入统计次数的字典,添加进去
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
#Label计数
labelCounts[currentLabel] += 1
#经验熵(香农熵)
shannonEnt = 0.0
#计算香农熵
for key in labelCounts:
#选择该标签(Label)的概率
prob = float(labelCounts[key]) / numEntires
#print prob,math.log(prob,2)
shannonEnt -= prob * math.log(prob, 2)
#返回经验熵(香农熵)
return shannonEnt #函数说明:按照给定特征划分数据集
#splitDataSet函数是用来选择各个特征的子集的
def splitDataSet(dataSet, axis, value):
#创建返回的数据集列表
retDataSet = []
#遍历数据集
for featVec in dataSet:
if featVec[axis] == value:
#去掉axis特征
reducedFeatVec = featVec[:axis]
#将符合条件的添加到返回的数据集
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet #计算信息增益
def chooseBestFeatureToSplit(dataSet):
#特征数量,去除最后一列,其余字段最为特征变量
numFeatures = len(dataSet[0]) - 1
#计算数据集的香农熵
baseEntropy = calcShannonEnt(dataSet)
#信息增益
bestInfoGain = 0.0
#最优特征的索引值,最初默认取-1
bestFeature = -1
#遍历所有特征
for i in range(numFeatures):
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
#创建set集合{},元素不可重复
uniqueVals = set(featList)
#经验条件熵
newEntropy = 0.0
#计算信息增益
for value in uniqueVals:
#subDataSet划分后的子集
subDataSet = splitDataSet(dataSet, i, value)
#计算子集的概率
prob = len(subDataSet) / float(len(dataSet))
#根据公式计算经验条件熵
newEntropy += prob * calcShannonEnt(subDataSet)
#信息增益
infoGain = baseEntropy - newEntropy
#打印每个特征的信息增益
print("第%d个特征的增益为%.3f" % (i, infoGain))
#计算信息增益
#更新信息增益,找到最大的信息增益
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
#记录信息增益最大的特征的索引值
bestFeature = i
return bestFeature #统计classList中出现此处最多的元素(类标签)
def majorityCnt(classList):
classCount = {}
for vote in classList: #统计classList中每个元素出现的次数
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
#根据字典的值降序排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
#返回classList中出现次数最多的元素
return sortedClassCount[0][0] #创建决策树[递归]
def createTree(dataSet, labels, featLabels):
#取分类标签(是否放贷:yes or no)
classList = [example[-1] for example in dataSet]
#如果类别完全相同则停止继续划分[第一个标签数等于所有的标签数,说明所有的结果都是同一个标签]
if classList.count(classList[0]) == len(classList):
return classList[0]
#len(dataSet[0])为特征变量数
if len(dataSet[0]) == 1: #遍历完所有特征时返回出现次数最多的类标签
return majorityCnt(classList)
#选择最优特征
bestFeat = chooseBestFeatureToSplit(dataSet)
##最优特征的标签
bestFeatLabel = labels[bestFeat]
featLabels.append(bestFeatLabel)
#print bestFeat,bestFeatLabel,featLabels
##根据最优特征的标签生成树
myTree = {bestFeatLabel:{}}
print myTree
##删除已经使用特征标签
del(labels[bestFeat])
##得到训练集中所有最优特征的属性值
featValues = [example[bestFeat] for example in dataSet]
##去掉重复的属性值
uniqueVals = set(featValues)
#print uniqueVals
for value in uniqueVals: #遍历特征,创建决策树。
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), labels, featLabels)
return myTree
#dataSet,labels = createDataSet()
#print calcShannonEnt(dataSet)
#print("最优特征索引值:" + str(chooseBestFeatureToSplit(dataSet))) #获取决策树叶子结点的数目
def getNumLeafs(myTree):
#初始化叶子
numLeafs = 0
firstStr = next(iter(myTree))#python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0]
#获取下一组字典
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs def getTreeDepth(myTree):
#初始化决策树深度
maxDepth = 0
firstStr = next(iter(myTree)) #python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0]
#获取下一个字典
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
#更新层数
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth #使用决策树分类
#inputTree - 已经生成的决策树
#featLabels - 存储选择的最优特征标签
#testVec - 测试数据列表,顺序对应最优特征标签
def classify(inputTree, featLabels, testVec):
firstStr = next(iter(inputTree)) #获取决策树结点
secondDict = inputTree[firstStr] #下一个字典
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:
if type(secondDict[key]).__name__ == 'dict':
classLabel = classify(secondDict[key], featLabels, testVec)
else: classLabel = secondDict[key]
return classLabel #测试数据集
dataSet, labels = createDataSet()
featLabels = []
#创建决策树
myTree = createTree(dataSet, labels, featLabels) #测试数据
testVec = [0,0]
#测试结果
result = classify(myTree, featLabels, testVec)
if result == 'yes':
print('放贷')
if result == 'no':
print('不放贷') #print myTree
#print getNumLeafs(myTree)
#print getTreeDepth(myTree)
决策树--Python的更多相关文章
- 决策树python建模中的坑 :ValueError: Expected 2D array, got 1D array instead:
决策树python建模中的坑 代码 #coding=utf-8 from sklearn.feature_extraction import DictVectorizerimport csvfrom ...
- 决策树python实现小样例
我们经常使用决策树处理分类问题,近年来的调查表明决策树也是经常使用的数据挖掘算法K-NN可以完成多分类任务,但是它最大的缺点是无法给出数据的内在含义,决策树的主要优势在于数据形式非常容易理解决策树的优 ...
- 机器学习:决策树--python
今天,我们介绍机器学习里比较常用的一种分类算法,决策树.决策树是对人类认知识别的一种模拟,给你一堆看似杂乱无章的数据,如何用尽可能少的特征,对这些数据进行有效的分类. 决策树借助了一种层级分类的概念, ...
- 机器学习_决策树Python代码详解
决策树优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据: 决策树缺点:可能会产生过度匹配问题. 决策树的一般步骤: (1)代码中def 1,计算给定数据集的香农熵: ...
- 决策树Decision Tree 及实现
Decision Tree 及实现 标签: 决策树熵信息增益分类有监督 2014-03-17 12:12 15010人阅读 评论(41) 收藏 举报 分类: Data Mining(25) Pyt ...
- Python机器学习基础教程
介绍 本系列教程基本就是搬运<Python机器学习基础教程>里面的实例. Github仓库 使用 jupyternote book 是一个很好的快速构建代码的选择,本系列教程都能在我的Gi ...
- ML二:NNSearch数据结构--二叉树
wiki百科:http://zh.wikipedia.org/wiki/%E5%86%B3%E7%AD%96%E6%A0%91%E5%AD%A6%E4%B9%A0 opencv学习笔记--二杈决策树: ...
- 【Machine Learning】决策树案例:基于python的商品购买能力预测系统
决策树在商品购买能力预测案例中的算法实现 作者:白宁超 2016年12月24日22:05:42 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本 ...
- python画决策树
1.安装graphviz.下载地址在:http://www.graphviz.org/.如果你是linux,可以用apt-get或者yum的方法安装.如果是windows,就在官网下载msi文件安装. ...
随机推荐
- javascript中的装箱和拆箱操作
1,装箱: 把基本数据类型转换为对应的引用类型的操作称为装箱,把引用类型转换为基本的数据类型称为拆箱. 在<javascript高级程序设计>中有这样一句话: 每当读取一个基本类型的时候, ...
- [原创]Spring boot 框架构建jsp web应用
说明 Spring boot支持将web项目打包成一个可执行的jar包,内嵌tomcat服务器,独立部署 为支持jsp,则必须将项目打包为war包 pom.xml中设置打包方式 <packagi ...
- Just a Hook(树状数组)
In the game of DotA, Pudge’s meat hook is actually the most horrible thing for most of the heroes. T ...
- 对象序列化中transient关键字的用途
- 算法优化》关于1D*1D的DP的优化
关于这一主题的DP问题的优化方法,我以前写过一篇博客与其有关,是关于对递推形DP的前缀和优化,那么这种优化方法就不再赘述了. 什么叫1D*1D的DP捏,就是一共有N种状态,而每种状态都要N种决策,这就 ...
- Codeforces 1120D (树形DP 或 最小生成树)
题意看这篇博客:https://blog.csdn.net/dreaming__ldx/article/details/88418543 思路看这篇:https://blog.csdn.net/cor ...
- C++中内存区域的划分
栈存储区 那些由编译器在需要的时候分配,在不需要的时候自动清楚的变量的存储区.里面的变量通常是局部变量.函数参数等. 堆存储区(自由存储区) 那些由new或者malloc分配的内存块,他们的释放编译器 ...
- HttpRuntime.Cache
a.在Web开发中,我们经常能够使用到缓存对象(Cache),在ASP.NET中提供了两种缓存对象,HttpContext.Current.Cache和HttpRuntime.Cache,那么他们有什 ...
- LoadRunner 学习(基础一)
最近开始正式系统地学习LoadRunner11.本想在自己觉得确实学到了比较有成就感的时候再mark一下,写个博客分享.阶段性地或者在自己有所小收获的时候,做做笔记分享下也好.这次作为开篇,我想记录下 ...
- LightOJ 1284 Lights inside 3D Grid (数学期望)
题意:在一个三维的空间,每个点都有一盏灯,开始全是关的.现在每次随机选两个点,把两个点之间的全部点,开关都按一遍,问k次过后开着的灯的期望数量: 析:很容易知道,如果一盏灯被按了奇数次,那么它肯定是开 ...