T-SQL 理解SQL SERVER中的分区表(转)
转载来源一定要明显: http://www.cnblogs.com/CareySon/archive/2011/12/30/2307766.html
而且这个大神对于数据库方面的文章非常棒 强烈推荐
简介
分区表是在SQL SERVER2005之后的版本引入的特性。这个特性允许把逻辑上的一个表在物理上分为很多部分。而对于SQL SERVER2005之前版本,所谓的分区表仅仅是分布式视图,也就是多个表做union操作.
分区表在逻辑上是一个表,而物理上是多个表.这意味着从用户的角度来看,分区表和普通表是一样的。这个概念可以简单如下图所示:
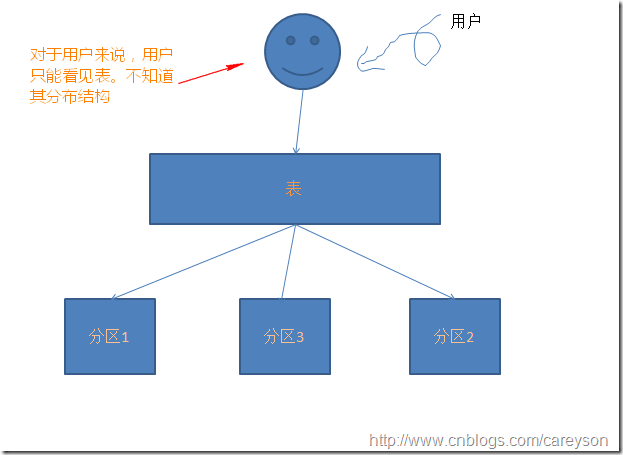
而对于SQL SERVER2005之前的版本,是没有分区这个概念的,所谓的分区仅仅是分布式视图:
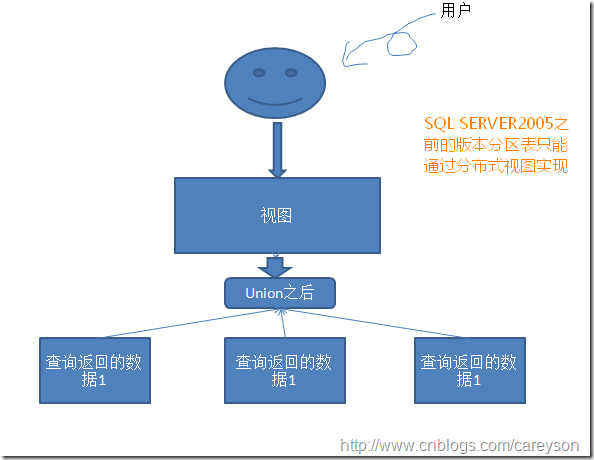
本篇文章所讲述的分区表指的是SQL SERVER2005之后引入的分区表特性.
为什么要对表进行分区
在回答标题的问题之前,需要说明的是,表分区这个特性只有在企业版或者开发版中才有,还有理解表分区的概念还需要理解SQL SERVER中文件和文件组的概念.
对表进行分区在多种场景下都需要被用到.通常来说,使用表分区最主要是用于:
- 存档,比如将销售记录中1年前的数据分到一个专门存档的服务器中
- 便于管理,比如把一个大表分成若干个小表,则备份和恢复的时候不再需要备份整个表,可以单独备份分区
- 提高可用性,当一个分区跪了以后,只有一个分区不可用,其它分区不受影响
- 提高性能,这个往往是大多数人分区的目的,把一个表分布到不同的硬盘或其他存储介质中,会大大提升查询的速度.
分区表的步骤
分区表的定义大体上分为三个步骤:
- 定义分区函数
- 定义分区构架
- 定义分区表
分区函数,分区构架和分区表的关系如下:
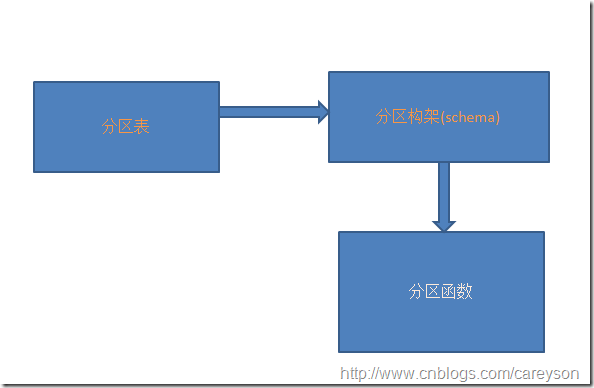
分区表依赖分区构架,而分区构架又依赖分区函数.值得注意的是,分区函数并不属于具体的分区构架和分区表,他们之间的关系仅仅是使用关系.
下面我们通过一个例子来看如何定义一个分区表:
假设我们需要定义的分区表结构如下:
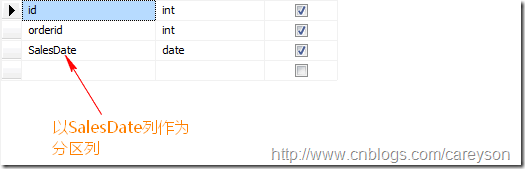
第一列为自增列,orderid为订单id列,SalesDate为订单日期列,也就是我们需要分区的依据.
下面我们按照上面所说的三个步骤来实现分区表.
定义分区函数
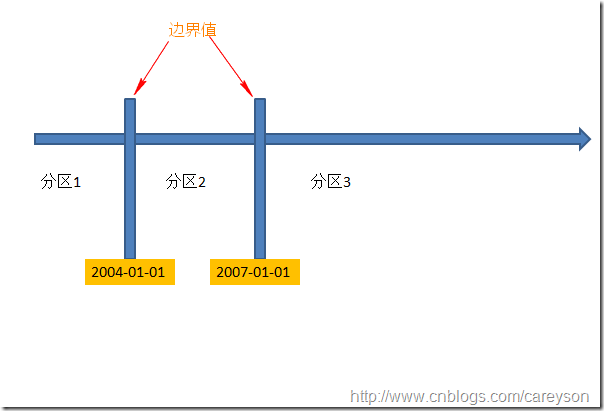
分区函数是用于判定数据行该属于哪个分区,通过分区函数中设置边界值来使得根据行中特定列的值来确定其分区,上面例子中,我们可以通过SalesDate的值来判定其不同的分区.假设我们想定义两个边界值(boundaryValue)进行分区,则会生成三个分区,这里我设置边界值分别为2004-01-01和2007-01-01,则前面例子中的表会根据这两个边界值分成三个区:
在MSDN中,定义分区函数的原型如下:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type )
AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ ,...n ] ] )
[ ; ]
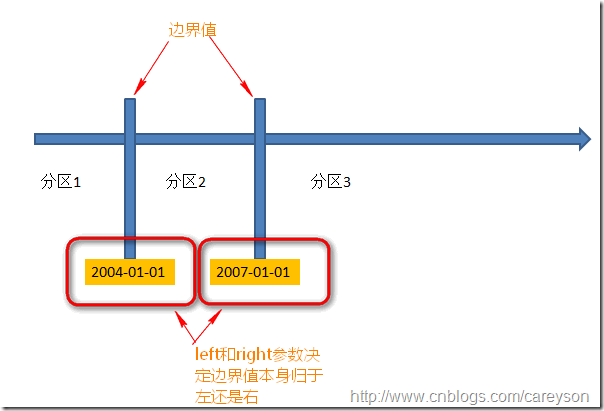
通过定义分区函数的原型,我们看出其中并没有具体涉及具体的表.因为分区函数并不和具体的表相绑定.上面原型中还可以看到Range left和right.这个参数是决定临界值本身应该归于“left”还是“right”:
下面我们根据上面的参数定义分区函数:
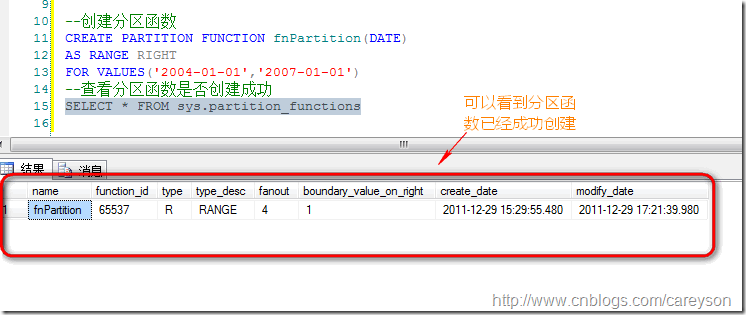
通过系统视图,可以看见这个分区函数已经创建成功
定义分区构架
定义完分区函数仅仅是知道了如何将列的值区分到了不同的分区。而每个分区的存储方式,则需要分区构架来定义.使用分区构架需要你对文件和文件组有点了解.
我们先来看MSDN的分区构架的原型:
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
[ ; ]
从原型来看,分区构架仅仅是依赖分区函数.分区构架中负责分配每个区属于哪个文件组,而分区函数是决定如何在逻辑上分区:
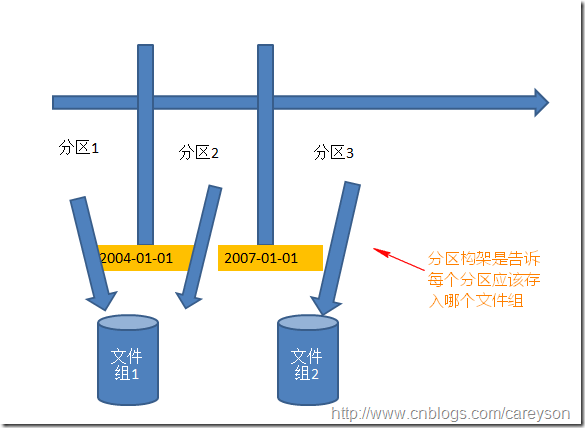
基于之前创建的分区函数,创建分区构架:
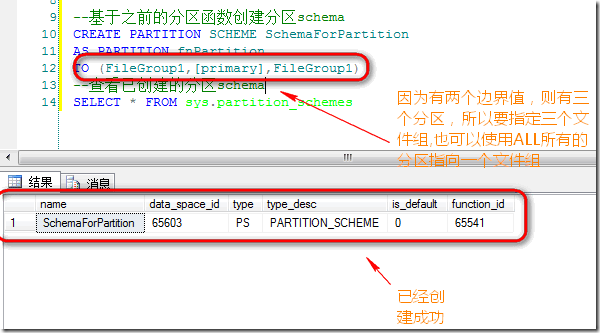
定义分区表
接下来就该创建分区表了.表在创建的时候就已经决定是否是分区表了。虽然在很多情况下都是你在发现已经表已经足够大的时候才想到要把表分区,但是分区表只能够在创建的时候指定为分区表。
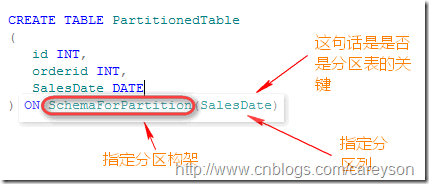
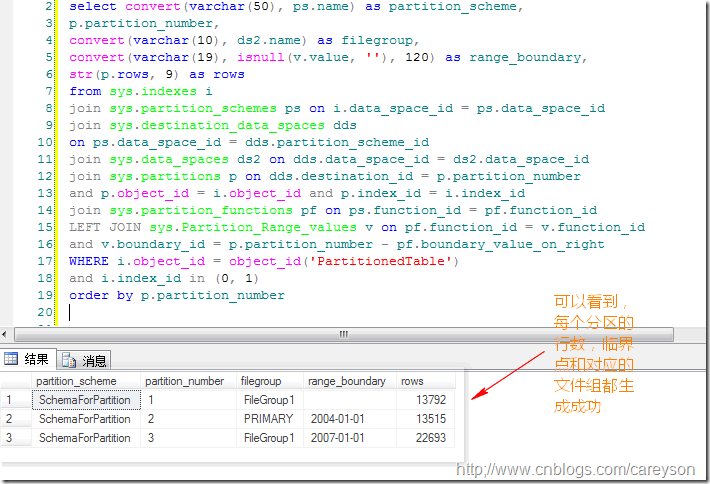
为刚建立的分区表PartitionedTable加入5万条测试数据,其中SalesDate随机生成,从2001年到2010年随机分布.加入数据后,我们通过如下语句来看结果:
select convert(varchar(50), ps.name) as partition_scheme,
p.partition_number,
convert(varchar(10), ds2.name) as filegroup,
convert(varchar(19), isnull(v.value, ''), 120) as range_boundary,
str(p.rows, 9) as rows
from sys.indexes i
join sys.partition_schemes ps on i.data_space_id = ps.data_space_id
join sys.destination_data_spaces dds
on ps.data_space_id = dds.partition_scheme_id
join sys.data_spaces ds2 on dds.data_space_id = ds2.data_space_id
join sys.partitions p on dds.destination_id = p.partition_number
and p.object_id = i.object_id and p.index_id = i.index_id
join sys.partition_functions pf on ps.function_id = pf.function_id
LEFT JOIN sys.Partition_Range_values v on pf.function_id = v.function_id
and v.boundary_id = p.partition_number - pf.boundary_value_on_right
WHERE i.object_id = object_id('PartitionedTable')
and i.index_id in (0, 1)
order by p.partition_number
可以看到我们分区的数据分布:
分区表的分割
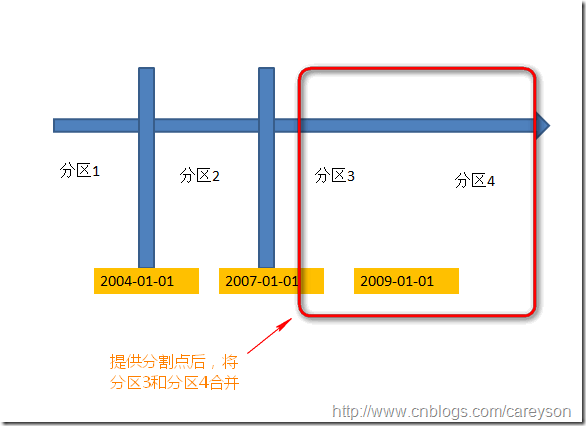
分区表的分割。相当于新建一个分区,将原有的分区需要分割的内容插入新的分区,然后删除老的分区的内容,概念如下图:
假设我新加入一个分割点:2009-01-01,则概念如下:
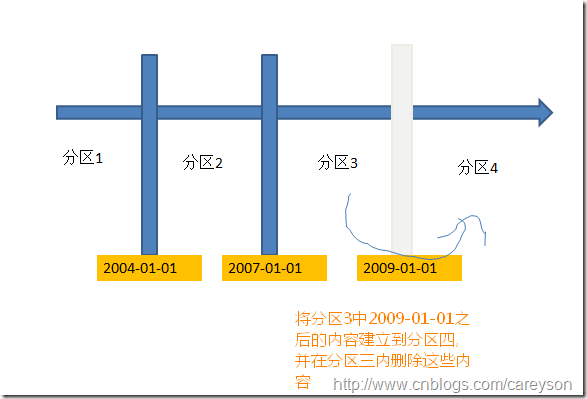
通过上图我们可以看出,如果分割时,被分割的分区3内有内容需要分割到分区4,则这些数据需要被复制到分区4,并删除分区3上对应数据。
这种操作非常非常消耗IO,并且在分割的过程中锁定分区三内的内容,造成分区三的内容不可用。不仅仅如此,这个操作生成的日志内容会是被转移数据的4倍!
所以我们如果不想因为这种操作给客户带来麻烦而被老板爆菊的话…最好还是把分割点建立在未来(也就是预先建立分割点),比如2012-01-01。则分区3内的内容不受任何影响。在以后2012的数据加入时,自动插入到分区4.
分割现有的分区需要两个步骤:
1.首先告诉SQL SERVER新建立的分区放到哪个文件组
2.建立新的分割点
可以通过如下语句来完成:
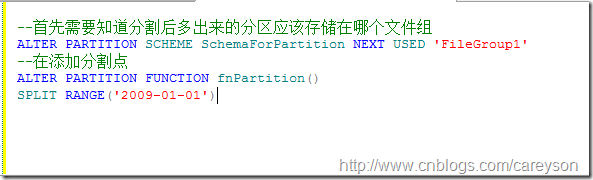
如果我们的分割构架在定义的时候已经指定了NEXT USED,则直接添加分割点即可。
通过文中前面查看分区的长语句..再来看:
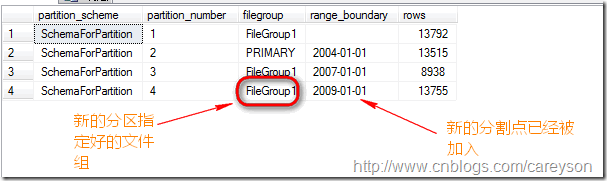
新的分区已经加入!
分区的合并
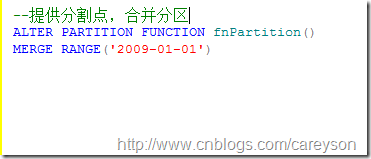
分区的合并可以看作分区分割的逆操作。分区的合并需要提供分割点,这个分割点必须在现有的分割表中已经存在,否则进行合并就会报错
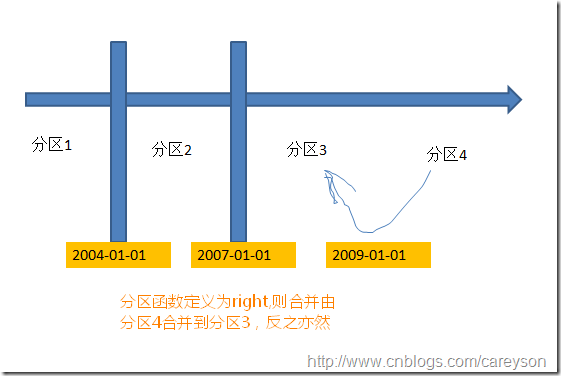
假设我们需要根据2009-01-01来合并分区,概念如下:
只需要使用merge参数:
再来看分区信息:
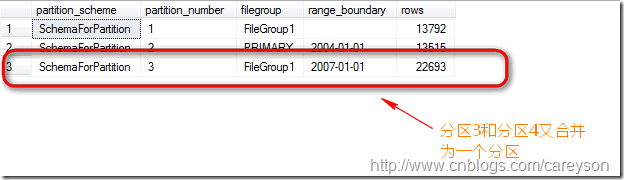
这里值得注意的是,假设分区3和分区4不再一个文件组,则合并后应该存在哪个文件组呢?换句话说,是由分区3合并到分区4还是由分区4合并到分区3?这个需要看我们的分区函数定义的是left还是right.如果定义的是left.则由左边的分区3合并到右边的分区4.反之,则由分区4合并到分区3:
总结
本文从讲解了SQL SERVER中分区表的使用方式。分区表是一个非常强大的功能。使用分区表相对传统的分区视图来说,对于减少DBA的管理工作来说,会更胜一筹!
T-SQL 理解SQL SERVER中的分区表(转)的更多相关文章
- (转)理解SQL SERVER中的分区表
简介 分区表是在SQL SERVER2005之后的版本引入的特性.这个特性允许把逻辑上的一个表在物理上分为很多部分.而对于SQL SERVER2005之前版本,所谓的分区表仅仅是分布式视图,也就是多个 ...
- 理解SQL SERVER中的分区表(转)
简介 分区表是在SQL SERVER2005之后的版本引入的特性.这个特性允许把逻辑上的一个表在物理上分为很多部分.而对于SQL SERVER2005之前版本,所谓的分区表仅仅是分布式视图,也就是多个 ...
- 理解SQL SERVER中的分区表
转自:http://www.cnblogs.com/sienpower/archive/2011/12/31/2308741.html 简介 分区表是在SQL SERVER2005之后的版本引入的特性 ...
- [SQL] 理解SQL SERVER中的逻辑读,预读和物理读
SQL SERVER数据存储的形式 在谈到几种不同的读取方式之前,首先要理解SQL SERVER数据存储的方式.SQL SERVER存储的最小单位为页(Page).每一页大小为8k,SQL SERVE ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 关于SQL Server中分区表的文件与文件组的删除(转)
在SQL Server中对表进行分区管理时,必定涉及到文件与文件组,关于文件与文件组如何创建在网上资料很多,我博客里也有两篇相关转载文件,可以看看,我这就不再细述,这里主要讲几个一般网上很少讲到的东西 ...
- SQL Server 2005 中的分区表和索引
SQL Server 2005 中的分区表和索引 SQL Server 2005 69(共 83)对本文的评价是有帮助 - 评价此主题 发布日期 : 3/24/2005 | 更新 ...
- SQL Server 中的事务与事务隔离级别以及如何理解脏读, 未提交读,不可重复读和幻读产生的过程和原因
原本打算写有关 SSIS Package 中的事务控制过程的,但是发现很多基本的概念还是需要有 SQL Server 事务和事务的隔离级别做基础铺垫.所以花了点时间,把 SQL Server 数据库中 ...
- 【转】T-SQL查询进阶—理解SQL Server中的锁
简介 在SQL Server中,每一个查询都会找到最短路径实现自己的目标.如果数据库只接受一个连接一次只执行一个查询.那么查询当然是要多快好省的完成工作.但对于大多数数据库来说是需要同时处理多个查 ...
随机推荐
- get传输时,会将加号+ 转换为空格
解决办法: 前端: 替换加号为 ‘%2B’, 后端: 直接接收即可.
- VS2017 Product Key
Enterprise: NJVYC-BMHX2-G77MM-4XJMR-6Q8QF Professional: KBJFW-NXHK6-W4WJM-CRMQB-G3CDH
- LINUX命令—让人喜爱的find
FIND命令的让人喜爱的地方在于其后面跟着的 –exec 可以执行其他linux命令 这点太让人高兴了,不过他的结尾要带一个特殊的结构 {} \: 说说实例:
- 在spring配置文件中的 <context:property-placeholder/>用途
location属性为 具体配置文件的classpath:地址 (可以取配置文件中的值利用${key}的形式,而不用多次写值) 1.这样一来就可以为spring配置的bean的属性设置值了,比如spr ...
- 1132. Cut Integer (20)
Cutting an integer means to cut a K digits long integer Z into two integers of (K/2) digits long int ...
- 剑指offer-第六章面试中的各项能力(数字在排序数组中出现的次数)
题目:统计一个数字在排序数组中出现的次数. 思路:采用二分查找,找到该数字在数组中第一次出现的位置,然后再找到组后一个出现的位置.两者做减法运算再加1.时间复杂度为O(logn) Java代码: // ...
- LA3263 That Nice Euler Circuits
题意 PDF 分析 欧拉定理:设平面内顶点数.边数.面数分别为\(V,E,F\),则\(V+F-E=2\). 枚举每对线段求交点,注意去重. 另外注意第n个端点和第一个端点重合. 时间复杂度\(o(T ...
- gulp 合格插件评判标准
官方插件列表: https://gulpjs.com/plugins/ 合格插件的判断标准 1. 不修改内容 如果一个插件一个文件都修改(无论是文案内容,文件路径),那么它就不是一个gulp ...
- Google搜索被屏蔽,如何使用Google搜索
我们在国内使用搜索引擎最多的是Google和Baidu啦,在引擎上找一些我们需要的知识,最近好像www.google.cn已经无法访问了,并且香港的链接www.google.com.hk也无法访问了, ...
- 学习动态性能表(2)--v$sesstat
学习动态性能表 第二篇--v$sesstat 2007.5.25 按照OracleOnlineBook中的描述,v$sesstat存储session从login到logout的详细资源使用统计. 类 ...