(数据科学学习手札32)Python中re模块的详细介绍
一、简介
关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结;
re作为Python中专为正则表达式相关功能做出支持的模块,提供了一系列方法来完成几乎全部类型的文本信息的处理工作,下面一一介绍:
二、re.compile()
在前一篇文章中我们使用过这个方法,它通过编译正则表达式参数,来返回一个目标对象的匹配模式,进而提高了正则表达式的效率,主要参数如下:
pattern:输入的欲编译正则表达式,需将正则表达式包裹在''内传入,如‘aa*’
flags:编译标志位,用于从某个角度修改正则表达式的匹配方式,常用的有:
re.S:使.匹配包括换行在内的所有字符
re.I:使匹配对大小写不敏感
re.U:根据Unicode规则解析字符,主要用于对中文的匹配中
下面是几个简单的例子:
import re text = '即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。' '''编译我们的正则表达式,规则为找到所有在双引号内的内容(不包括双引号)'''
regex = re.compile('“(.*?)”') '''打印匹配结果'''
print(regex.findall(text))
运行结果:

可以看出,匹配到的所有内容会以列表的形式返回;
import re text = '即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。' '''编译我们的正则表达式,规则为大小写英文字母至少出现一次的内容'''
regex = re.compile('[A-Za-z]+') '''打印匹配结果'''
print(regex.findall(text))
运行结果:

接下来我们对flags参数进行赋值,看看会实现怎样的功能:
import re text = '即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。' '''编译我们的正则表达式,规则为小写英文字母至少出现一次的内容'''
regex = re.compile('[a-z]+')#未使用flags无视大小写 '''打印匹配结果'''
print(regex.findall(text))
运行结果:

因为我们使用的正则表达式为[a-z]+,所以大写字母部分未能匹配到,下面我们不改变我们的正则表达式部分,而是对flags进行赋参:
import re text = '即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。' '''编译我们的正则表达式,规则为小写英文字母至少出现一次的内容'''
regex = re.compile('[a-z]+',flags=re.I)#使用re.I无视大小写 '''打印匹配结果'''
print(regex.findall(text))
运行结果:

在使用flags=re.I来无视大小写的情况下,在原有的正则表达式的基础上,实现了对大写字母的匹配。
三、re.match()
这个方法个人觉得用的是不是很多,它表示以定义的正则表达式作为对目标字符串开头的匹配(对非开头部分不匹配),下面是一个简单的例子:
import re text = 'What are you waiting for?' '''成功匹配到开头,因为字符串开头是W'''
print(re.match('w',text,re.I).group())
运行结果:

当字符串开头不匹配时,即使字符串其他部分有匹配的也不返回值(即所谓的只匹配开头部分):
import re text = 'What are you waiting for? where are you fucking from?' '''未能成功匹配到开头,因为字符串开头是Wha'''
print(re.match('whe',text,re.I))
运行结果:

四、re.search()
re.search()的使用格式类似re.match(),即三个传入参数:pattern,string,flags,但与match匹配开头不同的是,search匹配的是文中出现的第一个满足条件的字符串部分并返回,对后续的不再进行匹配,下面是一个简单的例子:
import re text = 'What are you waiting for? where are you fucking from?' '''成功匹配到第一个出现的目标内容,后续的内容便不再匹配'''
print(re.search('a',text,re.I).group())
运行结果:
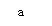
文中有很多a,但search遇到第一个a便停止匹配并返回这第一个值;
这里要注意一下,我在前面几个例子中使用到的group()方法,是针对match或search成功匹配并返回的对象,我们称之为match object,围绕它的常用方法如下:
strat():返回匹配开始的位置
end():返回匹配结束的位置
group():返回被re匹配的字符串
span():返回一个tuple格式的对象,标记了匹配开始,结束的位置,形如(start,end)
事实上,虽然说search只返回一个对象,但我们可以通过将正则表达式改造成若干子表达式拼接的形式,来返回多个分块的对象
import re text = '1213sdsdjAKNNK' '''匹配复合表达式对应的内容(返回对象会根据子表达式进行分块),并分别打印第1、2、3块子内容'''
print(re.search('([1-9]+)*([a-z]+)*([A-Z]+)',text).group(1))
print(re.search('([1-9]+)*([a-z]+)*([A-Z]+)',text).group(2))
print(re.search('([1-9]+)*([a-z]+)*([A-Z]+)',text).group(3))
运行结果:

五、findall()
注意,这和我们在解析BeautifulSoup对象时使用到的findAll()拼写不同(虽然功能相似),它与match和search不同的是,它会根据传入的正则表达式部分来提取目标字符串中所有符合规则的部分,并传出为列表的形式,下面是一个简单的例子:
import re text = '即使你没听说过“维基百科六度分隔理论”,也很可能听过“凯文 · 贝肯(Kevin Bacon)的六度分隔值游戏”。在这两个游戏中,都是把两个不相干的主题(维基百科里是用词条之间的连接,凯文 · 贝肯的六度分隔值游戏是用出现在同一部电影中的演员来连接)用一个总数不超过六条的主题连接起来(包括原来的两个主题)。' '''匹配text中所有以 听 开头的长度为2的字符串'''
print(re.findall('听.',text))
运行结果:

与前面在介绍re.compile()时对findall的用法不同,这里是re.findall(正则表达式,目标字符串)的格式,前面的是 编译好的正则模式.findall(目标字符串),这两种格式的功能等价;
六、re.finditer()
我们有时候会遇到这样的情况:目标字符串非常长(可能是一整篇小说),而符合我们正则表达式的目标内容也非常的多,这种时候如果沿用前面的做法使用re.findall()来一口气将所有结果提取出来保存在一个硕大的列表中,是件非常占用内存的事情,而Python中用来节省内存的生成器(generator)就派上了用场;
re.finditer(pattern,string,flags=0)就利用了这种机制,它构造出一个基于正则表达式pattern和目标字符串string的生成器,使得我们可以在对该生成器的循环中边循环边计算对应位置的值,即从始至终每一轮只保存了当前的位置和当前匹配到的内容,达到节省内存的作用,下面是一个简单的例子:
import re text = 'abjijdianbdadjijijiha8hihanihhhiihiaaihidaihihaidhihaidahi' '''构造我们的迭代器'''
obj = re.finditer('a.',text) '''对obj进行迭代,每次返回当前位置匹配到的内容及对应的起始与结束位置'''
for i in obj:
print(i.group())
print(i.span())
运行结果:

七、re.sub()
类似字符串操作中的replace(),只不过replace()中只能死板地设置固定的内容作为替换项,利用re.sub(pattern,repl,string,count)则可以基于正则表达式达到灵活匹配替换内容,pattern指定了正则表达式部分,repl指定了进行替换的新内容,string指定目标字符串,count指定了替换的次数,默认全部替换,其实前一篇文章结尾处我们得到一篇干净的新闻报道就用到了这种方法,下面再举一个简单的例子:
import re text = 'abjijdianbdadjijijiha8hihanihhhiihiaaihidaihihaidhihaidahi' '''构造我们的替代规则'''
obj = re.sub('a.','嘻嘻',text) '''打印替换后内容'''
print(obj)
运行结果:

八、re.split()
类似于字符串处理中的split(),re.split()在原有基础上扩充了正则表达式的功能,re.split(pattern,string,maxsplit),其中pattern指定分隔符的正则表达式,string指定目标字符串,maxsplit指定最大分割个数,下面是一个简单的例子:
import re text = 'abjijdianbdadjijijiha8hihanihhhiihiaaihidaihihaidhihaidahi' '''构造我们的分割规则'''
obj = re.split('i.',text) '''打印分割后内容'''
print(obj)
运行结果:

以上就是关于re模块的常用功能,接下来会以一篇实战来详细介绍实际业务中的网络数据采集过程。
(数据科学学习手札32)Python中re模块的详细介绍的更多相关文章
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札80)用Python编写小工具下载OSM路网数据
本文对应脚本已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们平时在数据可视化或空间数据分析的过程中经常会 ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
随机推荐
- 深入Python(1): 字典排序 关于sort()、reversed()、sorted()
http://www.cnblogs.com/BeginMan/p/3193081.html 一.Python的排序 1.reversed() 这个很好理解,reversed英文意思就是:adj. 颠 ...
- 插上翅膀,让Excel飞起来——xlwings(三)
xlwings基本对象 xlwings基本对象 App相当于Excel程序,Book相当于工作簿.N个Excel程序则由apps表示,N个工作簿由books表示. 对工作簿的操作 #导入xlwings ...
- Linux使用sz、rz命令下载、上传文件
1.安装服务 yum -y install lrzsz 2.上传命令:rz 使用rz命令,会调用系统的资源管理器,选择文件进行上传即可.上传的文件默认保存linux当前所在目录 3.下载命令:sz 根 ...
- mac 上安装lua
mac 安装lua google了好个看起来都不怎么好操作,这个是在命令行下操作的很简单. http://www.lua.org/download.html curl -R -O http://www ...
- 【luogu P2385 青铜莲花池】 题解
题目链接:https://www.luogu.org/problemnew/show/P2385 莲花池什么的最漂亮啦! 最近刷了两天搜索= =我搜索一直是弱菜 直接套bfs #include < ...
- php常见的几种排序以及二分法查找
<?php 1.插入排序 思想: 每次将一个待排序的数据元素插入到前面已经排好序的数列中,使数列依然有序,知道待排序数据元素全部插入完为止. 示例: [初始关键字] [49] 38 65 97 ...
- Tomcat 服务器体系结构
connector 监听端口,监听到以后,交给 Engine 引擎 处理,引擎会根据请求找到对应的主机,找到主机后再去找对应的应用. 如果我们将 port 改为 80,那访问的时候就不用输入端口号,因 ...
- Python—面向对象04 绑定方法
坚持把梳理的知识都给记下来....... 嗯哼哼 1.绑定方法与非绑定方法 在类内部定义的函数,分为两大类: 绑定到类的方法:用classmethod装饰器装饰的方法. 为类量身定制 类.boud_m ...
- 匿名union
#include <stdio.h> enum node_type{ t_int,t_double}; struct node{ enum node_type type; ...
- android(eclipse)编程中常见的java问题总结(四)
0:java流: 流是具有方向的 在文件操作中java流分为字节流:Filereader和Filewriter字符流:FileOutputStream,FileInputSream 例如在 ...