SolrCloud分布式集群部署步骤
- Solr及SolrCloud简介
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
SolrCloud是Solr4.0版本以后基于Solr和Zookeeper的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。它有以下几个特点:
- 集中式的配置信息管理。
- 自动容错。
- 近实时搜索。
- 查询时自动负载均衡。
- 将索引存储在HDFS上。
- 通过MR批量创建索引。
更多关于SolrCloud的相关介绍可参考以下链接:
- 软件包准备
- jdk-7u79-linux-x64.tar.gz
- apache-tomcat-7.0.62.tar.gz
- solr-5.2.1.tgz
- zookeeper-3.4.6.tar.gz
- 服务器准备
准备三台服务器:
- 192.168.1.131
- 192.168.1.141
- 192.168.1.146
- SolrCloud集群搭建步骤
- 服务器环境配置
- 配置主机名和IP映射,在3台服务器的/etc/hosts文件中添加以下几行:
192.168.1.131 solr-cloud-master
192.168.1.141 solr-cloud-slave1
192.168.1.146 solr-cloud-slave2
将文件同步到其它机器上。
scp /etc/hosts solr-cloud-slave1:/etc/
scp /ect/hosts solr-cloud-slave2:/etc/ - 关闭防火墙,在生产环境中需要开放相应的端口。
service iptables stop
chkconfig iptables off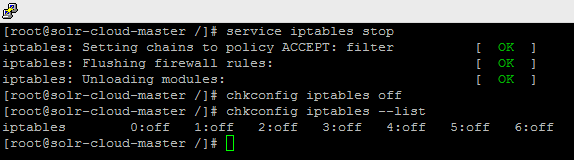
- 配置主机名和IP映射,在3台服务器的/etc/hosts文件中添加以下几行:
- 安装文件目录规划
- JDK安装目录:/usr/local/lib
- Solr安装目录:/opt/SolrCloud/Solr/solr
- Solr配置文件目录:/opt/SolrCloud/Solr/solr-config
- Solr数据文件目录:/apps/data/solr-cores
- Zookeeper安装目录:/opt/SolrCloud/Zookeeper
- Zookeeper数据文件目录:/apps/data/zookeeper/data
- Tomcat安装目录:/opt/SolrCloud/Tomcat
除了安装JDK的目录不需要创建,其它目录都需要进行创建。
- 安装JDK
- 解压 jdk-7u79-linux-x64.tar.gz 到 /usr/local/lib/ 目录下并重命名
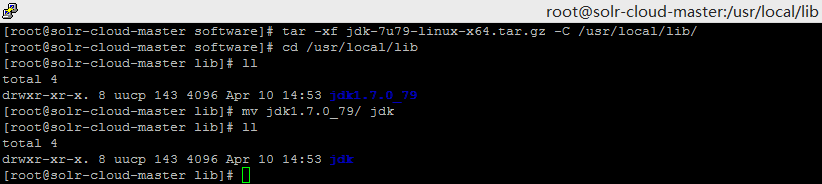
- 在/etc/profile.d/ 目录下创建一个shell脚本文件并添加一下内容:
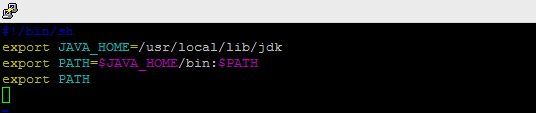
配置立即生效:
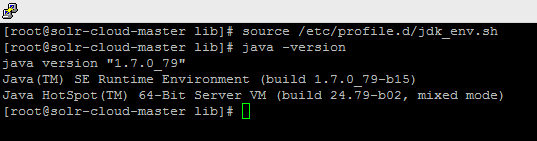
source /etc/profile.d/jdk_env.sh
输入 java -version 检测是否安装成功
也可以直接修改/etc/profile文件,添加的内容都是一样的。同步配置到其它机器:
scp -r /usr/local/lib/jdk solr-cloud-slave1:/usr/local/lib/
scp /etc/profile.d/jdk_env.sh solr-cloud-slave1:/ect/profile.d/
source /etc/profile.d/jdk_env.sh scp -r /usr/local/lib/jdk solr-cloud-slave2:/usr/local/lib/
scp /ect/profile.d/jdk_env.sh solr-cloud-slave2:/etc/profile.d/
source /etc/profile.d/jdk_env.sh
- 解压 jdk-7u79-linux-x64.tar.gz 到 /usr/local/lib/ 目录下并重命名
- 安装配置Zookeeper
- 解压 zookeeper-3.4.6.tar.gz 到 /opt/SolrCloud/Zookeeper/ 目录,并修改目录所有者。
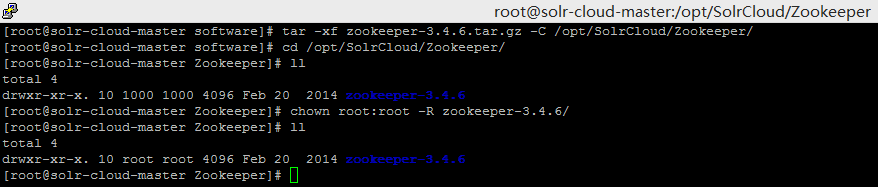
- 配置zookeeper
cd /opt/SolrCloud/Zookeeper/zookeeper-3.4./conf
cp zoo_sample.cfg zoo.cfg - 修改zoo.cfg
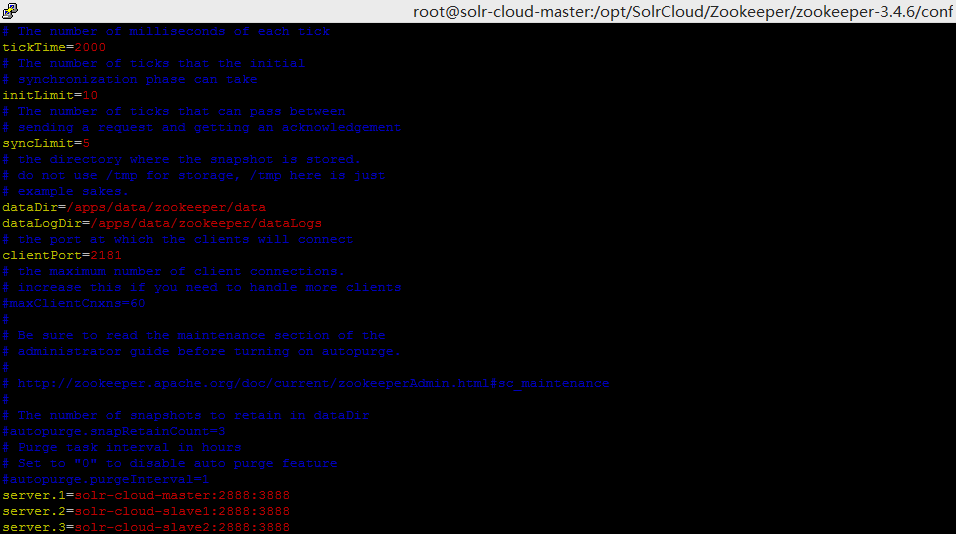
- 参数详解
tickTime:该参数有默认值:3000,单位是毫秒(ms),可以不配置,不支持系统属性方式配置,参数tickTime用于配置Zookeeper中最小时间单元的长度,
很多运行时的时间间隔都是使用tickTime的倍数来表示的。例如,Zookeeper中会话的最小超时时间默认是2*tickTime。initLimit:该参数有默认值:10,即表示是参数tickTime值的10倍,必须配置,且需要配置一个正整数,不支持系统属性方式设置。该参数用于配置Leader服务器等待Follower启动,
并完成数据同步的时间。Follower服务器启动过程中,会与Leader建立连接并完成数据的同步,从而确定自己对外提供服务的起始状态。Leader服务器允许Follower在inittLimit时间内完成这个工作。通常情况下,运维人员不用太在意这个参数的配置,使用其默认值即可。但如果随着Zookeeper集群管理的数据量增大,Follower服务器在启动的时候,从Leader上进行同步数据的时间也会相应变长,于是无法在较短的时间完成数据同步。因此,在这种情况下,有必要适当调大这个参数。syncLimit:该参数有默认值:5,即表示tickTime值得5倍,必须配置,且需要配置一个正整数,不支持系统属性设置。该参数用于配置Leader服务器和Follower之间进行心跳检测的最大延迟时间。在Zookeeper集群运行过程中,Leader服务器会与所有Follower进行心跳检测来确定该服务器是否存活。如果Leader服务器在syncLimit时间内无法获取到Follower的心跳检测响应,那么Leader就会认为该Follower已经脱离了和自己的同步。
dataDir:该参数无默认值,必须配置,不支持系统属性方式设置,参数dataDir用于配置Zookeeper服务器存储快照文件的目录。默认情况下,如果没有配置参数dataLogDir,那么事务日志也会存储在这个目录中。考虑到事务日志的写性能直接影响Zookeeper整体的服务能力,因此建议同时通过参数dataLogDir来配置Zookeeper事务日志的存储目录。
dataLogDir:该参数有默认值,dataDir,可以不配置,不支持系统属性方式设置。参数dataLogDir用于配置Zookeeper服务器存储事务日志文件的目录。默认情况下,Zookeeper会将事务日志文件和快照数据存储在同一个目录中,应尽量将这两者的目录区分开来,另外,如果条件允许,可以将事务日志的存储配置在一个单独的磁盘上。事务日志记录对于磁盘的性能要求非常高,为了保证数据的一致性,Zookeeper在返回客户端事务请求响应之前,必须将本次请求对应的事务日志写入到磁盘中。因此,事务日志写入的性能直接决定了Zookeeper在处理事务请求是的吞吐。
clientPort:参数clientPort用于配置当前服务器对外的服务端口,客户端会通过该端口和Zookeeper服务器建立连接,一般设置为2181。每台Zookeeper服务器都可以配置任意可以的端口,同时,集群中的所以服务器不需要保持clientPort端口一致。
server.id=host:port:port :该参数没有默认值,在单机模式下可以不配置,不支持系统属性方式设置。该参数用于配置组成Zookeeper集群的机器列表,其中id即为Server ID,与每台服务器myid文件中的数字相对应。同时,在该参数中,会配置两个端口:第一个端口用于指定Follower服务器与Leader进行运行时通信和数据同步是所使用的端口,第二个端口则专门用于Leader选举过程中的投票通信。在Zookeeper服务器启动的时候,其会根据myid文件中配置的Server ID来确定自己是哪台服务器,并使用对于配置的端口来进行启动。
- 同步Zookeeper的配置及相关目录到其它两台机器:
scp -r /opt/SolrCloud/Zookeeper/zookeeper-3.4./ solr-cloud-slave1:/opt/SolrCloud/Zookeeper/
scp -r /apps/data/zookeeper/ solr-cloud-slave1:/apps/data/ scp -r /opt/SolrCloud/Zookeeper/zookeeper-3.4./ solr-cloud-slave2:/opt/SolrCloud/Zookeeper/
scp -r /apps/data/zookeeper/ solr-cloud-slave2:/apps/data/ - 创建myid文件,并写入zoo.cfg中对于的Server ID:
solr-cloud-master:

solr-cloud-slave1:

solr-cloud-slave2:

- 分别启动三台Zookeeper服务器:
cd /opt/SolrCloud/Zookeeper/zookeeper-3.4./bin/
./zkServer.sh start
- 查看Zookeeper状态
solr-cloud-master:

solr-cloud-slave1:

solr-cloud-slave2:

- Zookeeper其它参考信息:
Zookeeper官网:
http://zookeeper.apache.org/doc/
Zookeeper维基百科:
https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index;jsessionid=0B5F772DCFF3506613D26E3752F7D415
Zookeeper技术博客:
http://nileader.blog.51cto.com/1381108/d-16
- 解压 zookeeper-3.4.6.tar.gz 到 /opt/SolrCloud/Zookeeper/ 目录,并修改目录所有者。
- SolrCloud分布式集群搭建
- 解压 apache-tomcat-7.0.62.tar.gz ,解压部署后的目录为:/opt/SolrCloud/Tomcat/apache-tomcat-7.0.62
- 解压 solr-5.2.1.tgz ,并把solr.war解压到/opt/SolrCloud/Solr/solr 目录下。
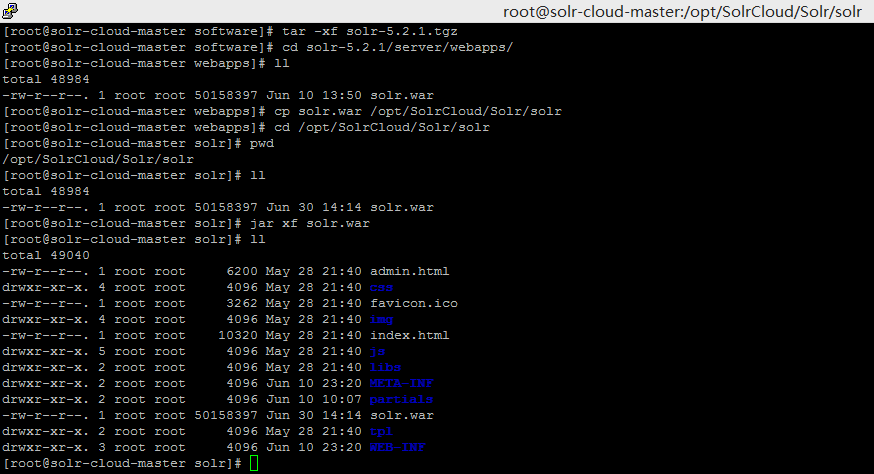
- 将 solr-5.2.1/server/lib/ext/ 目录下的jar包拷贝到 /opt/SolrCloud/Solr/solr/WEB-INF/lib/ 目录下。
cp /home/software/solr-5.2./server/lib/ext/*.jar /opt/SolrCloud/Solr/solr/WEB-INF/lib/
- 将 solr-5.2.1/server/solr/configsets/basic_configs/conf/ 目录下的文件拷贝到 /opt/SolrCloud/Solr/solr-config/
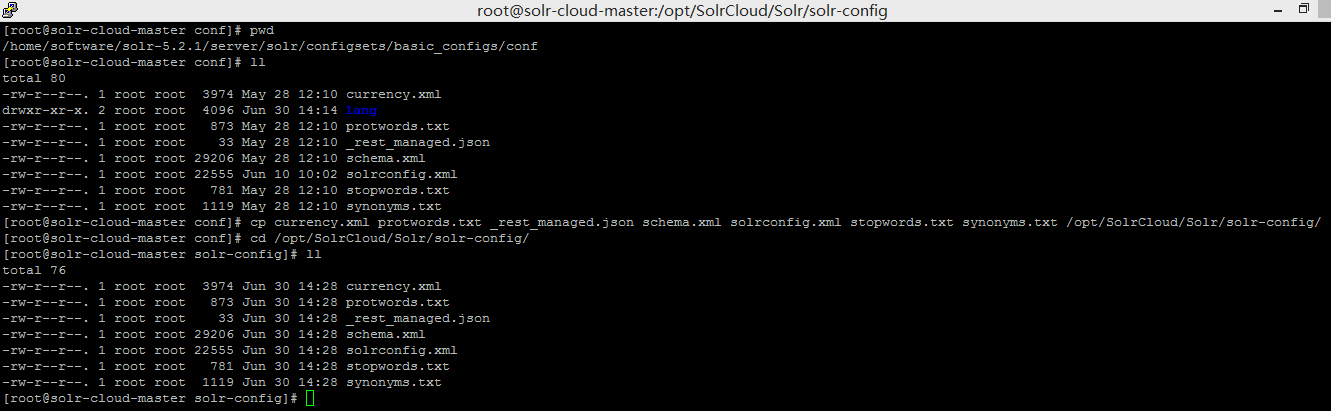
- 将 solr-5.2.1/example/files/conf/ 目录下的文件夹拷贝到 /opt/SolrCloud/Solr/solr-config/
- 将 /opt/SolrCloud/Solr/solr 目录拷贝到 /opt/SolrCloud/Tomcat/apache-tomcat-7.0.62/webapps/ 目录下。
- 将 solr-5.2.1/server/solr/ 目录下的solr.xml文件拷贝到 /apps/data/solr-cores/ 目录下,这是solr的核心配置文件。
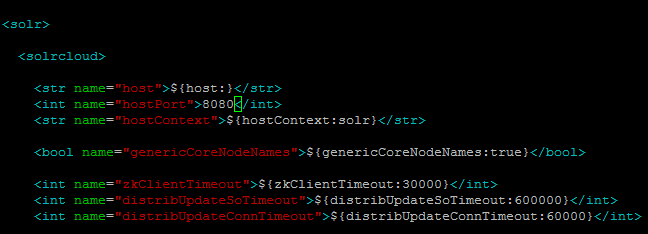
- 修改 /apps/data/solr-cores/ 目录下的solr.xml,修改hostPort和Tomcat端口一致:
同步配置到其它机器:
scp /apps/data/solr-cores/solr.xml solr-cloud-slave1:/apps/data/solr-cores/
scp /apps/data/solr-cores/solr.xml solr-cloud-slave2:/apps/data/solr-cores/ - 在 /opt/SolrCloud/Tomcat/apache-tomcat-7.0.62/conf/ 目录下创建Catalina和localhost目录。
mkdir -p /opt/SolrCloud/Tomcat/apache-tomcat-7.0./conf/Catalina/localhost
- 在 /opt/SolrCloud/Tomcat/apache-tomcat-7.0.62/conf/Catalina/localhost/ 目录下创建solr.xml,此为Solr/home的配置文件。
<?xml version="1.0" encoding="UTF-8"?>
<Context docBase="/opt/SolrCloud/Tomcat/apache-tomcat-7.0.62/webapps/solr" debug="0" crossContext="true">
<Environment name="solr/home" type="java.lang.String" value="/apps/data/solr-cores/" override="true"/>
</Context> 修改 /opt/SolrCloud/Tomcat/apache-tomcat-7.0.62/bin/catalina.sh 加入以下内容:

- 将以上配置同步到其它服务器
scp -r /opt/SolrCloud/Tomcat/apache-tomcat-7.0./ solr-cloud-slave1:/opt/SolrCloud/Tomcat/
scp -r /opt/SolrCloud/Solr/ solr-cloud-slave1:/opt/SolrCloud/
scp -r /apps/data/solr-cores/ solr-cloud-slave1:/apps/data/ scp -r /opt/SolrCloud/Tomcat/apache-tomcat-7.0./ solr-cloud-slave2:/opt/SolrCloud/Tomcat/
scp -r /opt/SolrCloud/Solr/ solr-cloud-slave2:/opt/SolrCloud/
scp -r /apps/data/solr-cores/ solr-cloud-slave2:/apps/data/ - 上传配置到Zookeeper:
SolrCloud是通过Zookeeper集群来保证配置文件的变更及时同步到各个节点上,所以,需要将配置文件上传到Zookeeper集群。
solr配置文件目录:/opt/SolrCloud/Solr/solr-config/
执行以下操作:java -classpath .:/opt/SolrCloud/Tomcat/apache-tomcat-7.0./webapps/solr/WEB-INF/lib/* org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost solr-cloud-master:2181,solr-cloud-slave1:2181,solr-cloud-slave2:2181 -confdir /opt/SolrCloud/Solr/solr-config/ -confname solrconfig
- 校验Zookeeper配置文件
cd /opt/SolrCloud/Zookeeper/zookeeper-3.4./bin/
./zkCli.sh -server solr-cloud-master:
- 启动Tomcat,先启动solr-cloud-master机器上的tomcat:
cd /opt/SolrCloud/Tomcat/apache-tomcat-7.0./bin/
./startup.sh启动solr-cloud-slave1和solr-cloud-slave2机器上的Tomcat。
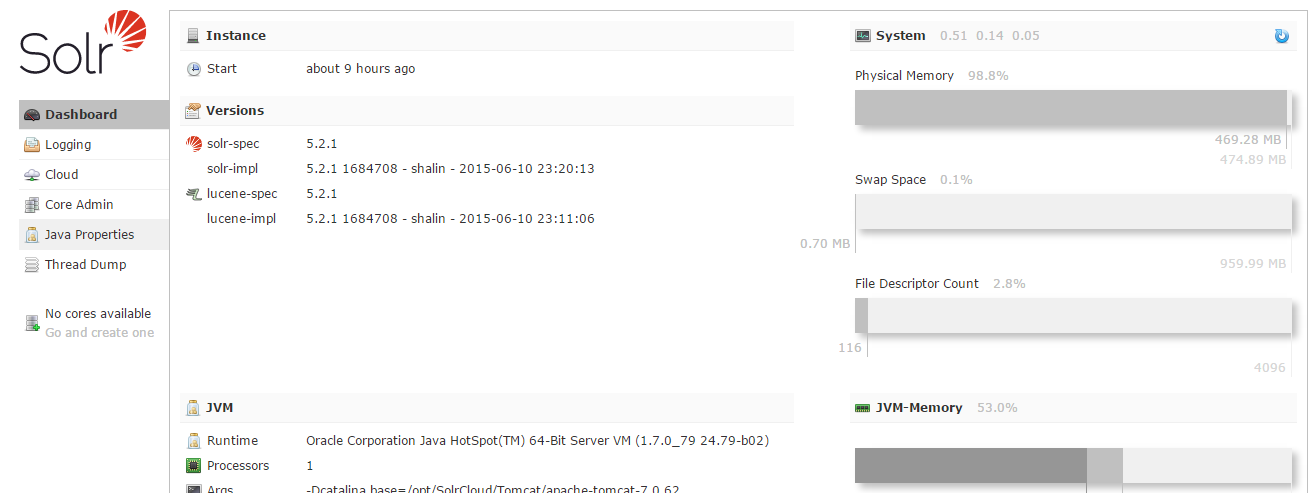
- 访问http://solr-cloud-master:8080/solr/可以看到下图:
- 创建Collection及初始化Shard
curl 'http://solr-cloud-master:8080/solr/admin/collections?action=CREATE&name=collection_1&numShards=3&replicationFactor=1'
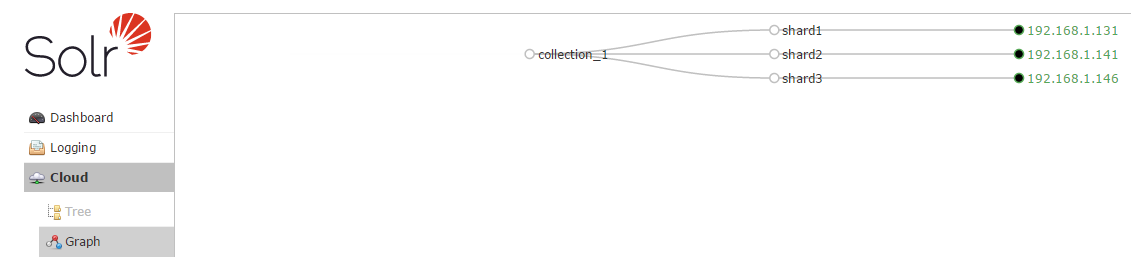
查看 /apps/data/solr-cores/ 目录:
- SolrCloud测试
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collection;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.CloudSolrClient;
import org.apache.solr.client.solrj.impl.LBHttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.client.solrj.response.UpdateResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument; public class SolrCloudTest {
public static final Log LOG = LogFactory.getLog(SolrCloudTest.class);
private static CloudSolrClient cloudSolrClient;
private static LBHttpSolrClient solrClient; private static synchronized CloudSolrClient getCloudSolrServer(final String zkHost) {
LOG.info("connection to : " + zkHost + "\n");
if (cloudSolrClient == null) {
cloudSolrClient = new CloudSolrClient(zkHost);
}
return cloudSolrClient;
} private void addIndex(SolrClient solrClient) {
try {
Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
for (int i = 0; i <= 200; i++) {
SolrInputDocument doc = new SolrInputDocument();
String key = "";
key = String.valueOf(i);
doc.addField("id", key);
doc.addField("test_s", key + "value");
docs.add(doc);
}
LOG.info("docs info:" + docs + "\n");
solrClient.add(docs);
solrClient.commit();
} catch (SolrServerException e) {
System.out.println("Add docs Exception !!!");
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
System.out.println("Unknowned Exception!!!!!");
e.printStackTrace();
}
} public void search(CloudSolrClient cloudSolrClient, String Str) {
SolrQuery query = new SolrQuery();
query.setRows(20);
query.setQuery(Str);
try {
LOG.info("query string: "+ Str);
System.out.println("query string: "+ Str);
QueryResponse response = cloudSolrClient.query(query);
SolrDocumentList docs = response.getResults();
System.out.println(docs);
System.out.println(docs.size());
System.out.println("doc num:" + docs.getNumFound());
System.out.println("elapse time:" + response.getQTime());
for (SolrDocument doc : docs) {
String area = (String) doc.getFieldValue("test_s");
String id = (String) doc.getFieldValue("id");
System.out.println("id: " + id);
System.out.println("tt_s: " + area);
System.out.println();
}
} catch (SolrServerException e) {
e.printStackTrace();
} catch(Exception e) {
e.printStackTrace();
}
} public void deleteSolrData(String solrUrl) {
try {
solrClient = new LBHttpSolrClient(solrUrl);
UpdateResponse res = solrClient.deleteByQuery("*:*");
System.out.println(res.getStatus());
solrClient.commit();
LOG.info("Delete Success!");
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException {
final String solrUrl = "http://solr-cloud-master:8080/solr/collection_1";
final String zkHost = "192.168.1.131:2181";
final String defaultCollection = "collection_1";
final int zkClientTimeout = 10000;
final int zkConnectTimeout = 10000;
CloudSolrClient cloudSolrClient = getCloudSolrServer(zkHost);
cloudSolrClient.setDefaultCollection(defaultCollection);
cloudSolrClient.setZkClientTimeout(zkClientTimeout);
cloudSolrClient.setZkConnectTimeout(zkConnectTimeout);
try{
cloudSolrClient.connect();
System.out.println("connect solr cloud zk sucess");
} catch (Exception e){
LOG.error("connect to collection "+defaultCollection+" error\n");
System.out.println("error message is:"+e);
e.printStackTrace();
System.exit(1);
}
SolrCloudTest solrCloudTest = new SolrCloudTest();
try{
solrCloudTest.addIndex(cloudSolrClient);
} catch(Exception e){
e.printStackTrace();
}
solrCloudTest.search(cloudSolrClient, "id:*");
// solrCloudTest.deleteSolrData(solrUrl);
cloudSolrClient.close();
}
}
- 总结
Solr5.x版本和Solr4.x的版本在安装上发生了比较大的变化,另外API操作上也发生了比较大的变化,安装相对来说比较简单,最大的难点在于对其进行性能方面的优化,在进行压力测试中发现,持续对solr集群进行操作会出现服务不可用的异常,原因目前还没有找到,有时还会出现Zookeeper集群服务异常导致数据插入失败。针对这些问题都需要后续不断地进行深入的研究后,才能得出结论或解决方案。
本文参考了:http://www.tuicool.com/articles/AJR3Mv
SolrCloud分布式集群部署步骤的更多相关文章
- solr 集群(SolrCloud 分布式集群部署步骤)
SolrCloud 分布式集群部署步骤 安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux ...
- SolrCloud 分布式集群部署步骤
https://segmentfault.com/a/1190000000595712 SolrCloud 分布式集群部署步骤 solr solrcloud zookeeper apache-tomc ...
- 170825、SolrCloud 分布式集群部署步骤
安装软件包准备 apache-tomcat-7.0.54 jdk1.7 solr-4.8.1 zookeeper-3.4.5 注:以上软件都是基于 Linux 环境的 64位 软件,以上软件请到各自的 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- 基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势)
基于winserver的Apollo配置中心分布式&集群部署实践(正确部署姿势) 前言 前几天对Apollo配置中心的demo进行一个部署试用,现公司已决定使用,这两天进行分布式部署的时候 ...
- Hadoop(HA)分布式集群部署
Hadoop(HA)分布式集群部署和单节点namenode部署其实一样,只是配置文件的不同罢了. 这篇就讲解hadoop双namenode的部署,实现高可用. 系统环境: OS: CentOS 6.8 ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- hadoop分布式集群部署①
Linux系统的安装和配置.(在VM虚拟机上) 一:安装虚拟机VMware Workstation 14 Pro 以上,虚拟机软件安装完成. 二:创建虚拟机. 三:安装CentOS系统 (1)上面步 ...
- 超详细从零记录Hadoop2.7.3完全分布式集群部署过程
超详细从零记录Ubuntu16.04.1 3台服务器上Hadoop2.7.3完全分布式集群部署过程.包含,Ubuntu服务器创建.远程工具连接配置.Ubuntu服务器配置.Hadoop文件配置.Had ...
随机推荐
- 破解Outlook数据文件密码/PST访问密码
不少人会经常用outlook,邮件多的时候可能不定期导出一个PST文件,为安全起见,给PST文件设置访问密码,可是时间长了,难免忘记,怎么办呢?不用担心,你自己就可以解决,无论是Outlook97.O ...
- the king of fighter
wim 学习部分摘自coolshell http://coolshell.cn/articles/5426.html 基本式 i → Insert 模式,按 ESC 回到 Normal 模式. x → ...
- GeoHash原理解析
GeoHash 核心原理解析 引子 一提到索引,大家脑子里马上浮现出B树索引,因为大量的数据库(如MySQL.oracle.PostgreSQL等)都在使用B树.B树索引本质上是对索引字段 ...
- Uncaught ReferenceError: XXX is not defined
Uncaught ReferenceError: XXX is not defined 这个问题困扰我很久,虽然找到了解决方法,但是还不是很明白. 如下所示:是报错的代码. 如果把它改成下面的形式就可 ...
- 【C编译器】MinGw安装与使用(调试问题待续)
不想装vs2005之类的,想要一个轻量级的C语言编译器,希望将焦点放在如何写好代码上: 本人信奉:代码质量是靠设计和检视保证的,不是靠调试: 1.安装MinGW http://www.mingw.or ...
- Cannot forward after response has been committed
项目:蒙文词语检索 日期:2016-05-01 提示:Cannot forward after response has been committed 出处:request.getRequestDis ...
- mysql 添加用户并授权
mysql> create database dogDB; mysql> CREATE USER 'dog'@'%' IDENTIFIED BY '123456'; mysql> g ...
- css总结(更新中...)
下面总结的都是我实际使用后有效的. 1.select的默认样式不好看,怎么去掉默认样式呢,如下: .select{text-indent: inherit !important; background ...
- api将一统江湖,再无app
api的出现,使人们可以通过各种软硬件设备获取所需服务,而不需要安装臃肿的app:今后的智能设备将不再依赖软件.操作系统和硬件,或许一台51单片机都可以提供给用户所需信息.当然连名字都可以简单到不叫a ...
- win10 64位 mysql安装
一.安装mysql 1.下载mysql-5.7.15-winx64.zip http://dev.mysql.com/downloads/mysql/ 2.解压缩到D:\ProgramFiles 3. ...