Java程序员学习Go语言—之一
转载:https://www.luozhiyun.com/archives/206
GOPATH 工作空间
GOPATH简单理解成Go语言的工作目录,它的值是一个目录的路径,也可以是多个目录路径,每个目录都代表Go语言的一个工作区(workspace)。
在GOPATH放置Go语言的源码文件(source file),以及安装(install)后的归档文件(archive file,也就是以“.a”为扩展名的文件)和可执行文件(executable file)。
源码安装
比如,一个已存在的代码包的导入路径是
github.com/labstack/echo,
那么执行命令进行源码的安装
go install github.com/labstack/echo
在安装后如果产生了归档文件(以“.a”为扩展名的文件),就会放进该工作区的pkg子目录;如果产生了可执行文件,就可能会放进该工作区的bin子目录。
上面该命令在安装后生成的归档文件的相对目录就是 github.com/labstack, 文件名为echo.a。
除此之外,归档文件的相对目录与pkg目录之间还有一级目录,叫做平台相关目录。平台相关目录的名称是由build(也称“构建”)的目标操作系统、下划线和目标计算架构的代号组成的。
比如,构建某个代码包时的目标操作系统是Linux,目标计算架构是64位的,那么对应的平台相关目录就是linux_amd64。
代码块中的重名变量
我们来看一下下面的代码:
var block = "package"
func main() {
block := "function"
{
block := "inner"
fmt.Printf("The block is %s.\n", block)
}
fmt.Printf("The block is %s.\n", block)
blockFun()
}
这个命令源码⽂件中有四个代码块,它们是:全域代码块、main包代表的代码块、main函数代表的代码块,以及在main函 数中的⼀个⽤花括号包起来的代码块。
如果运行该代码,那么会得到如下结果:
The block is inner.
The block is function.
在go中,首先,代码引⽤变量的时候总会最优先查找当前代码块中的那个变量。
其次,如果当前代码块中没有声明以此为名的变量,那么程序会沿着代码块的嵌套关系,从直接包含当前代码块的那个代 码块开始,⼀层⼀层地查找。
⼀般情况下,程序会⼀直查到当前代码包代表的代码块。如果仍然找不到,那么Go语⾔的编译器就会报错了。
所以上面的例子中,main代码块首先无法引用到最内层代码块中的变量,最内层的代码块也会优先去找自己代码块的变量。
需要注意一点的是,在不同的代码块中,变量的名字可以相同但是类型可以不同的。
其实如果使用过java,就会发现这些都和java的变量申明是一样的。
变量的类型
判断变量类型
在java中,我们可以用instanceof来判断类型,在go中要稍微麻烦一点,具体的如下:
func main() {
container := map[int]string{0: "zero", 1: "one", 2: "two"}
fmt.Printf("The element is %q.\n", container[1])
value2, ok2 := interface{}(container).(map[int]string)
value1, ok1 := interface{}(container).([]string)
fmt.Println(value1)
fmt.Println(value2)
if !(ok1 || ok2) {
fmt.Printf("Error: unsupported container type: %T\n", container)
return
}
}
也就是说需要通过interface{}(container).(map[int]string)这样的一句表达式来实现判断类型。
它包括了⽤来把container变量的值转换为空接⼝值的interface{}(container)。 以及⼀个⽤于判断前者的类型是否为map类型 map[int]string 的 .(map[int]string)。
这个表达式返回两个变量,ok代表是否判断成功,如果为true,那么被判断的值将会被自动转换为map[int]string,否则value将被赋 予nil(即“空”)。

强制类型转换
我们一般可以通过如下的方式实现类型转换:
var srcInt = int16(-255)
dstInt := int8(srcInt)
fmt.Println(dstInt)
在上面的类型转换中需要注意的是,这里是范围大的类型转换成范围小的类型,Go语⾔会把在较⾼ 位置(或者说最左边位置)上的8位⼆进制数直接截掉,所以dstInt的值就是1。
类似的快⼑斩乱麻规则还有:当把⼀个浮点数类型的值转换为整数类型值时,前者的⼩数部分会被全部截掉。
所以在类型转换的时候要时刻提防类型范围的问题。
类型别名和潜在类型
别名类型与其源类型的区别恐怕只是在名称上,它们 是完全相同的。
type MyString = string
定义新的类型,这个类型会不同于其他任何类型。
type MyString2 string // 注意,这⾥没有等号。
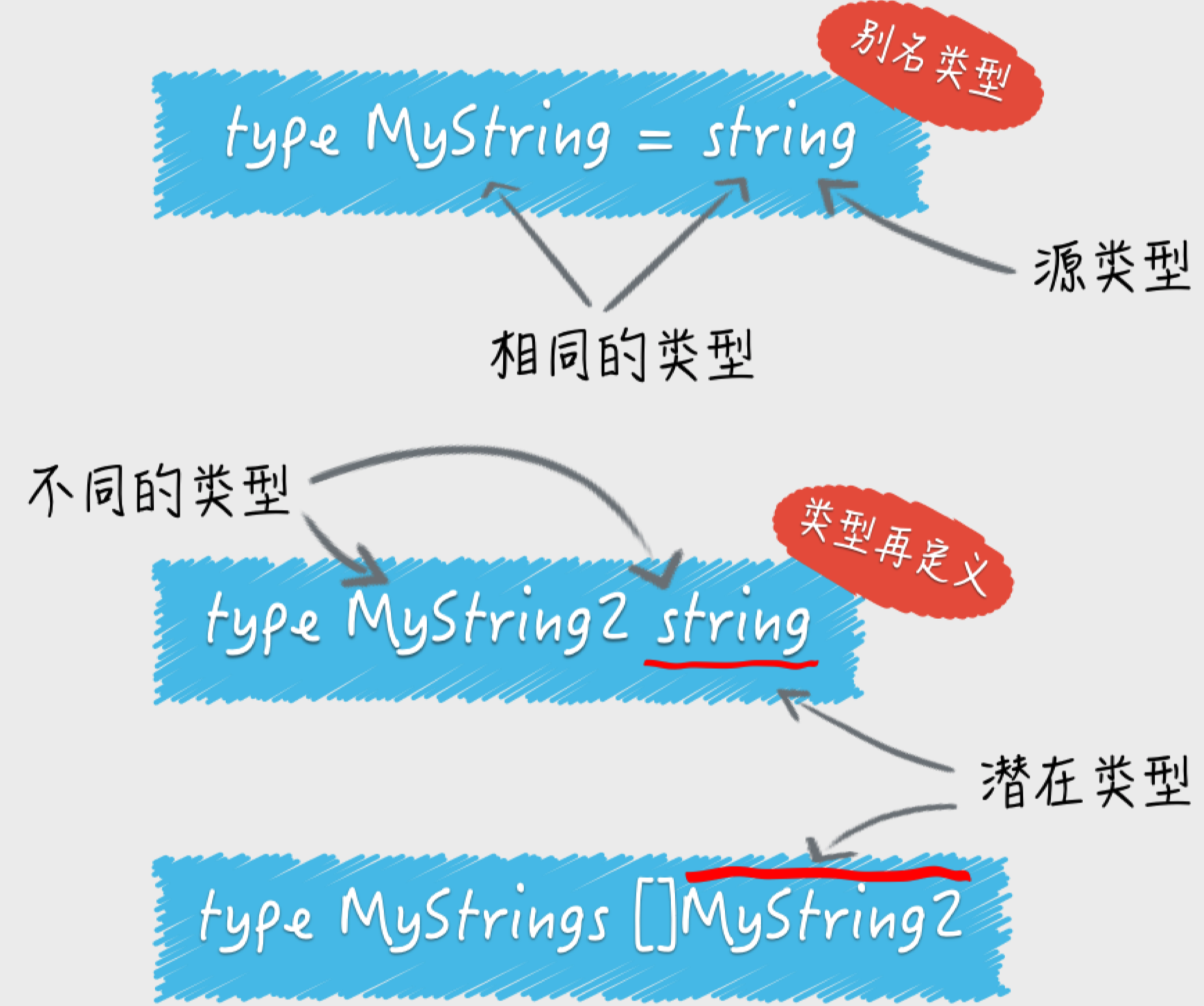
如果两个值潜在类型相同,却属于不同类型,它们之间是可以进⾏类型转换的。如下:
type MyString string
str := "BCD"
myStr1 := MyString(str)
myStr2 := MyString("A" + str)
但是两个类型的潜在类型相同,它们的值之间也不能进⾏判等或⽐较,它们的变量之间也不能赋值。如下:
type MyString2 string
str := "BCD"
myStr2 := MyString2(str)
//myStr2 = str // 这里的赋值不合法,会引发编译错误。
//fmt.Printf("%T(%q) == %T(%q): %v\n",
// str, str, myStr2, myStr2, str == myStr2) // 这里的判等不合法,会引发编译错误。
对于集合类的类型[]MyString2与[]string来说是不可以进⾏类型转换和比较的,因为[]MyString2与[]string的潜在类型不 同,分别是MyString2和string。如下:
type MyString string
strs := []string{"E", "F", "G"}
var myStrs []MyString
//myStrs := []MyString(strs) // 这里的类型转换不合法,会引发编译错误。
管道channel
通道类型的值本身就是并发安全的,这也是Go语⾔⾃带的、唯⼀⼀个可以满⾜并发安全性的类型。
当容量为0时,我们可以称通道为⾮缓冲通道,也就是不带缓冲的通道。⽽当容量⼤于0时,我们可以称为缓冲通道,也就是 带有缓冲的通道。
⼀个通道相当于⼀个先进先出(FIFO)的队列。也就是说,通道中的各个元素值都是严格地按照发送的顺序排列的,先被发 送通道的元素值⼀定会先被接收。元素值的发送和接收都需要⽤到操作符<-。我们也可以叫它接送操作符。⼀个左尖括号紧 接着⼀个减号形象地代表了元素值的传输⽅向。
func main() {
ch1 := make(chan int, 3)
//往channel中放入元素
ch1 <- 2
ch1 <- 1
ch1 <- 3
//往channel中获取元素
elem1 := <-ch1
fmt.Printf("The first element received from channel ch1: %v\n",
elem1)
}
基本特性
- 对于同⼀个通道,发送操作之间是互斥的,接收操作之间也是互斥的。
在同⼀时刻,Go语⾔的运⾏时系统(以下简称运⾏时系统)只会执⾏对同⼀个通道的任意个发 送操作中的某⼀个。直到这个元素值被完全复制进该通道之后,其他针对该通道的发送操作才可能被执⾏。
类似的,在同⼀时刻,运⾏时系统也只会执⾏,对同⼀个通道的任意个接收操作中的某⼀个。
另外,对于通道中的同⼀个元素值来说,发送操作和接收操作之间也是互斥的。例如,虽然会出现,正在被复制进通道但还未 复制完成的元素值,但是这时它绝不会被想接收它的⼀⽅看到和取⾛。
需要注意的是:进⼊通道的并不是在接收操作符右边的那个元素 值,⽽是它的副本。
发送操作和接收操作中对元素值的处理都是不可分割的。
如发送操作要么还没复制元素值,要么已经复制完毕,绝不会出现只复制了⼀部分的情况。发送操作在完全完成之前会被阻塞。接收操作也是如此。
发送操作包括了“复制元素值”和“放置副本到通道内部”这两个步骤。
在这两个步骤完全完成之前,发起这个发送操作的那句代码会⼀直阻塞在那⾥。也就是说,在它之后的代码不会有执⾏的机 会,直到这句代码的阻塞解除。
⻓时间的阻塞
- 缓冲通道
如果通道已满,那么对它的所有发送操作都会被阻塞,直到通道中有元素值被接收⾛。
由于发送操作在这种情况下被阻塞后,它们所在的goroutine会顺序地进⼊通道内部的发送等待队列,所以通知的顺序总是公平的。
// 示例1。
ch1 := make(chan int, 1)
ch1 <- 1
//ch1 <- 2 // 通道已满,因此这里会造成阻塞。
// 示例2。
ch2 := make(chan int, 1)
//elem, ok := <-ch2 // 通道已空,因此这里会造成阻塞。
//_, _ = elem, ok
ch2 <- 1
- ⾮缓冲通道
⽆论是发送操作还是接收操作,⼀开始执⾏就会被阻塞,直到配对的操作也开始执⾏,才 会继续传递。由此可⻅,⾮缓冲通道是在⽤同步的⽅式传递数据。也就是说,只有收发双⽅对接上了,数据才会被传递。
ch1 := make(chan int )
ch1 <- 10
fmt.Println("End." )//这里会造成阻塞。
关闭通道
对于⼀个已初始化的通道来说,如果通道一旦关闭,再对它进⾏发送操作,就会 引发panic。
如果试图关闭⼀个已经关闭了的通道,也会引发panic。
所以我们在关闭通道的时候应当让发送方做这件事,接收操作是可以感知到通道的关闭的,并能够安全退出。
如果通道关闭时,⾥⾯还有元素值未被取出,那么接收表达式的第⼀个结果,仍会是通道中的某⼀个元素值,⽽第⼆个 结果值⼀定会是true。
func main() {
ch1 := make(chan int, 2)
// 发送方。
go func() {
for i := 0; i < 10; i++ {
fmt.Printf("Sender: sending element %v...\n", i)
ch1 <- i
}
fmt.Println("Sender: close the channel...")
close(ch1)
}()
// 接收方。
for {
elem, ok := <-ch1
if !ok {
fmt.Println("Receiver: closed channel")
break
}
fmt.Printf("Receiver: received an element: %v\n", elem)
}
fmt.Println("End.")
}
单向通道
如下,这表示了这个通道是单向的,并且只能发⽽不能收。
var uselessChan = make(chan<- int, 1)
单向通道最主要的⽤途就是约束其他代码的⾏为。
例如:
func main() {
// 初始化一个容量为3的通道
intChan1 := make(chan int, 3)
//将通道传入到函数中
SendInt(intChan1)
}
//使用单向通道限制这个函数只能放入元素到通道中
func SendInt(ch chan<- int) {
ch <- rand.Intn(1000)
}
在SendInt函数中的代码只能 向参数ch发送元素值,⽽不能从它那⾥接收元素值。这就起到了约束函数⾏为的作⽤。
同样单通道也可以作为函数的返回值:
func main() {
intChan2 := getIntChan()
for elem := range intChan2 {
fmt.Printf("The element in intChan2: %v\n", elem)
}
}
func getIntChan() <-chan int {
num := 5
ch := make(chan int, num)
for i := 0; i < num; i++ {
ch <- i
}
close(ch)
return ch
}
函数getIntChan会返回⼀个<-chan int类型的通道,这就意味着得到该通道的程序,只能从通道中接收元素值。
select多路选择
select语句与通道联⽤
select语句只能与通道联⽤,它⼀般由若⼲个分⽀组成。每次执⾏这种语句的时候,⼀般只有⼀个分⽀中的代码会被运⾏。
我们通过下面的例子来展示:
func example1() {
// 准备好几个通道。
intChannels := [3]chan int{
make(chan int, 1),
make(chan int, 1),
make(chan int, 1),
}
// 随机选择一个通道,并向它发送元素值。
index := rand.Intn(3)
fmt.Printf("The index: %d\n", index)
intChannels[index] <- index
// 哪一个通道中有可取的元素值,哪个对应的分支就会被执行。
select {
case <-intChannels[0]:
fmt.Println("The first candidate case is selected.")
case <-intChannels[1]:
fmt.Println("The second candidate case is selected.")
case elem := <-intChannels[2]:
fmt.Printf("The third candidate case is selected, the element is %d.\n", elem)
default:
fmt.Println("No candidate case is selected!")
}
}
在使用select语句中,需要注意:
- 如果像上述示例那样加⼊了默认分⽀,那么⽆论涉及通道操作的表达式是否有阻塞,select语句都不会被阻塞。如果那 ⼏个表达式都阻塞了,或者说都没有满⾜求值的条件,那么默认分⽀就会被选中并执⾏。
- 如果没有加⼊默认分⽀,那么⼀旦所有的case表达式都没有满⾜求值条件,那么select语句就会被阻塞。直到⾄少有⼀ 个case表达式满⾜条件为⽌。
- select语句只能对其中的每⼀个case表达式各求值⼀次。
- select语句包含的候选分⽀中的case表达式都会在该语句执⾏开始时先被求值,并且求值的顺序是依从代码编写的顺序 从上到下的。
- 对于每⼀个case表达式,如果其中的发送表达式或者接收表达式在被求值时,相应的操作正处于阻塞状态,那么对 该case表达式的求值就是不成功的。
- 如果select语句发现同时有多个候选分⽀满⾜选择条件,那么它就会⽤⼀种伪随机的算法在这些分⽀中选择⼀个并执⾏。
超时控制
select 里面会根据两个case的返回时间来选择运行,哪个先返回哪个就先执行,所以利用这个功能,可以实现超时返回。
func TestSelect(t *testing.T) {
//select 里面会根据两个case的返回时间来选择运行
//哪个先返回哪个就先执行
//所以利用这个功能,可以实现超时返回
select {
case ret:=<-AsyncService():
t.Log(ret)
case <-time.After(time.Microsecond*100):
t.Error("time out")
}
}
func AsyncService() chan string {
retCh := make(chan string,1)
go func() {
ret := service()
fmt.Println("return result.")
retCh <- ret
fmt.Println("service exited.")
}()
return retCh
}
函数
接受其他的函数作为参数传⼊
我们可以先申明一个函数类型:
type operate func(x, y int) int
然后将这个函数当做参数传入到函数内
func calculate(x int, y int, op operate) (int, error) {
if op == nil {
return 0, errors.New("invalid operation")
}
return op(x, y), nil
}
闭包
可以借闭包在程序运⾏的过程中,根据需要⽣成功能不同的函数,继⽽影响后续的程序⾏为。
例如:
type calculateFunc func(x int, y int) (int, error)
func genCalculator(op operate) calculateFunc {
return func(x int, y int) (int, error) {
if op == nil {
return 0, errors.New("invalid operation")
}
return op(x, y), nil
}
}
func main() {
x, y = 56, 78
add := genCalculator(op)
result, err = add(x, y)
fmt.Printf("The result: %d (error: %v)\n",
result, err)
}
参数值在函数中传递
分为两种类型来处理,值类型和引用类型
- 值类型
所有传给函数的参数值都会被复制,函数在其内部使⽤的并不是参数值的原 值,⽽是它的副本。
如下:
func main() {
// 示例1。
array1 := [3]string{"a", "b", "c"}
fmt.Printf("The array: %v\n", array1)
array2 := modifyArray(array1)
fmt.Printf("The modified array: %v\n", array2)
fmt.Printf("The original array: %v\n", array1)
fmt.Println()
}
// 示例1。
func modifyArray(a [3]string) [3]string {
a[1] = "x"
return a
}
返回的是:
The array: [a b c]
The modified array: [a x c]
The original array: [a b c]
由于数组是值类型,所以每⼀次复制都会拷⻉它,以及它的所有元素值。我在modify函数中修改的只是原数组的副本⽽已, 并不会对原数组造成任何影响。
- 引用类型
对于引⽤类型,⽐如:切⽚、字典、通道,像上⾯那样复制它们的值,只会拷⻉它们本身⽽已,并不会拷⻉它们引⽤的 底层数据。也就是说,这时只是浅表复制,⽽不是深层复制。
以切⽚值为例,如此复制的时候,只是拷⻉了它指向底层数组中某⼀个元素的指针,以及它的⻓度值和容量值,⽽它的底层数 组并不会被拷⻉。
如下:
func main() {
slice1 := []string{"x", "y", "z"}
fmt.Printf("The slice: %v\n", slice1)
slice2 := modifySlice(slice1)
fmt.Printf("The modified slice: %v\n", slice2)
fmt.Printf("The original slice: %v\n", slice1)
fmt.Println()
}
func modifySlice(a []string) []string {
a[1] = "i"
return a
}
返回:
The slice: [x y z]
The modified slice: [x i z]
The original slice: [x i z]
由于类modifySlice传入的是一个指针的引用,所以当指针所指向的底层数组发生变化,那么原值就会发生变化。
- 引用类型和值类型结合的类型
如下:
func main() {
complexArray1 := [3][]string{
[]string{"d", "e", "f"},
[]string{"g", "h", "i"},
[]string{"j", "k", "l"},
}
fmt.Printf("The complex array: %v\n", complexArray1)
complexArray2 := modifyComplexArray(complexArray1)
fmt.Printf("The modified complex array: %v\n", complexArray2)
fmt.Printf("The original complex array: %v\n", complexArray1)
}
func modifyComplexArray(a [3][]string) [3][]string {
a[1][1] = "s"
a[2] = []string{"o", "p", "q"}
return a
}
返回:
The complex array: [[d e f] [g h i] [j k l]]
The modified complex array: [[d e f] [g s i] [o p q]]
The original complex array: [[d e f] [g s i] [j k l]]
实际上还是和上面的一样的理论,传入modifyComplexArray方法的数组是复制的,但是数组里面的元素传的是引用,所以直接修改引用的切片值会影响到原来的值,但是直接以这样的方式a[2] = []string{"o", "p", "q"}新建了一个数组则不会改变。
Java程序员学习Go语言—之一的更多相关文章
- Java程序员学习之路
1. Java语言基础 谈到Java语 言基础学习的书籍,大家肯定会推荐Bruce Eckel的<Thinking in Java>.它是一本写的相当深刻的技术书籍,Java语言基础部分基 ...
- 聊聊阿里社招面试,谈谈“野生”Java程序员学习的道路
引言 很尴尬的是,这个类型的文章其实之前笔者就写过,原文章里,笔者自称LZ(也就是楼主,有人说是老子的简写,笔者只想说,这位同学你站出来,保证不打死你,-_-),原文章名称叫做<回答阿里社招面试 ...
- 【Python】Java程序员学习Python(五)— 函数的定义和使用
不想做一个待宰的羔羊!!!!要自己变得强大.... 函数的定义和使用放在最前边还是有原因的,现在语言趋于通用,基本类型基本都是那些,重点还是学习对象的使用方法,而最根本的还是方法的使用,因此优先介绍, ...
- 如何准备阿里社招面试,顺谈 Java 程序员学习中各阶段的建议
引言 其实本来真的没打算写这篇文章,主要是LZ得记忆力不是很好,不像一些记忆力强的人,面试完以后,几乎能把自己和面试官的对话都给记下来.LZ自己当初面试完以后,除了记住一些聊过的知识点以外,具体的内容 ...
- 写给自己的Java程序员学习路线图
恩,做开发的工作已经三年多了,说起来实在是惭愧,自己的知识树还像一棵小草一样,工作中使用到了许多的知识和技术,不过系统性不够.根基不牢.并且不够深入!当然,慢慢的我也更加的清楚,我需要学习一些什么样的 ...
- 写给自己的Java程序员学习路线图_转载
如下是我做开发这三年经常使用一些技术和工具,当然这些技术也都是需要加强的(有些是我一直使用的,不过不深入,有些内部的原理等等不是很清楚) 前端部分: 1)HTML:网页的核心语言,构成网页的基础 2) ...
- 【Python】Java程序员学习Python(二)— 开发环境搭建
巧妇难为无米之炊,我最爱的还是鸡蛋羹,因为我和鸡蛋羹有段不能说的秘密. 不管学啥,都要有环境,对于程序员来说搭建个开发环境应该不是什么难题.按顺序一步步来就可以,我也只是记录我的安装过程,你也可以滴. ...
- 普通Java程序员学习使用的6个JDK内建工具
与你的问题不同,我认为软件工程主要是用来解决问题的.有些博客认为“每个小孩都应该学习编程”,“你认为学数学只是玩玩而已?如果你有看过我的HTML5调试器的话,你会发现我是一个程序员,但我做的工作远不止 ...
- 【Python】Java程序员学习Python(三)— 基础入门
一闪一闪亮晶晶,满天都是小星星,挂在天上放光明,好像许多小眼睛.不要问我为什么喜欢这首歌,我不会告诉你是因为有人用口琴吹给我听. 一.Python学习文档与资料 一般来说文档的资料总是最权威,最全面的 ...
随机推荐
- LuoguP2765 魔术球问题
LuoguP2765 魔术球问题 首先,很难看出来这是一道网络流题.但是因为在网络流24题中,所以还是用网络流的思路 首先考虑完全平方数的限制. 如果\(i,j\)满足\(i < j\) 且 $ ...
- 安装低版本Microsoft .NET Framework 4.5受阻解决方案
在VS目标框中找不到Microsoft .NET Framework 4.5,项目出错,安装受阻.... 1.Microsoft .NET Framework 安装了高版本后,低版本通过网上上下载的d ...
- 微信群打卡机器人XiaoV项目开源 | 蔡培培的独立博客
原文首发于蔡培培的独立博客.原文链接<微信群打卡机器人XiaoV项目开源>. 5月21日,在米花(后面" 亚里士多德式友谊"专题会提及)的影响下,决定搞个私人运动群,拉 ...
- 分布式大牛详解Zookeeper底层原理
很多学员都在反馈,说zk很难学,学的不是很明白,在这里,我继续带着大家详解一遍Zookeeper 首先zk是什么呢首先肯定是一个个分布式服务框架,是Apache Hadoop 的一个子项目,它主要是用 ...
- Kubernetes Clusters
1. 创建集群 Kubernetes集群 Kubernetes协调一个高可用的计算机集群,作为一个单独的单元来一起工作.有了这种抽象,在Kubernetes中你就可以将容器化的应用程序部署到集群中, ...
- LINQ 实现多字段关联查询 C#
var query = from main in _userDeviceChannelRole.Table join deviceChannelInfo in _deviceChannelReposi ...
- 洛谷$P3620\ [APIO/CTSC 2007]$数据备份 贪心
正解:贪心 解题报告: 传送门$QwQ$ $umm$感觉这种问题还蛮经典的,,,就选了某个就不能选另一个这样儿,就可以用堆模拟反悔操作 举个$eg$,如果提出了$a_i$,那就$a_{i-1}$和$a ...
- 洛谷$P5038\ [SCOI2012]$奇怪的游戏 二分+网络流
正解:二分+网络流 解题报告: 传送门$QwQ$ 这种什么,"同时增加",长得就挺网络流的$QwQ$?然后看到问至少加多少次,于是考虑加个二分呗?于是就大体确定了做题方向,用的网络 ...
- $CH$3801 $Rainbow$的信号 期望+位运算
正解:位运算 解题报告: 传送门! 其实就是个位运算,,,只是顺便加了个期望的知识点$so$期望的帕并不难来着$QwQ$ 先把期望的皮扒了,就直接分类讨论下,不难发现,答案分为两个部分 $\left\ ...
- Python3 pip换源
pip安装源 介绍 """ 1.采用国内源,加速下载模块的速度 2.常用pip源: -- 豆瓣:https://pypi.douban.com/simple -- 阿里: ...