第七篇 css选择器实现字段解析
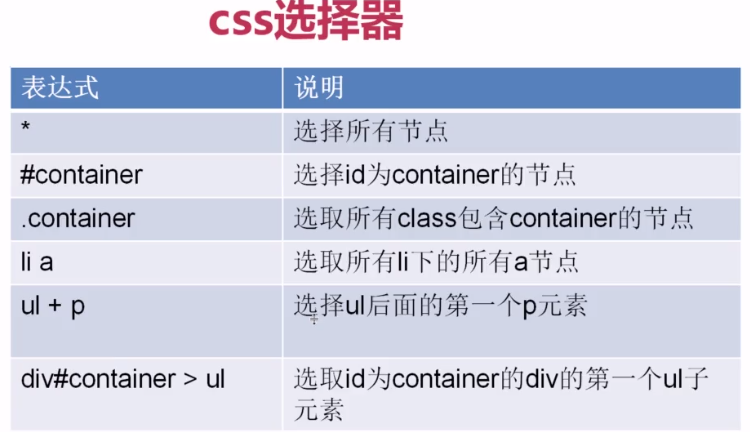
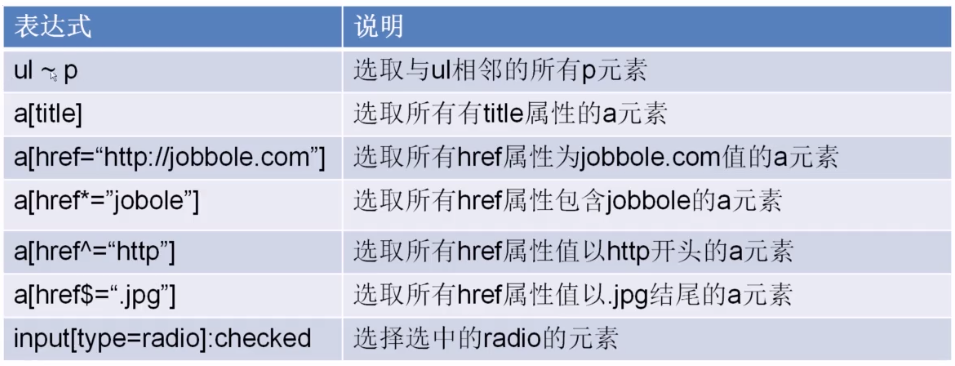
CSS选择器的作用实际和xpath的一样,都是为了定位具体的元素

举例我要爬取下面这个页面的标题
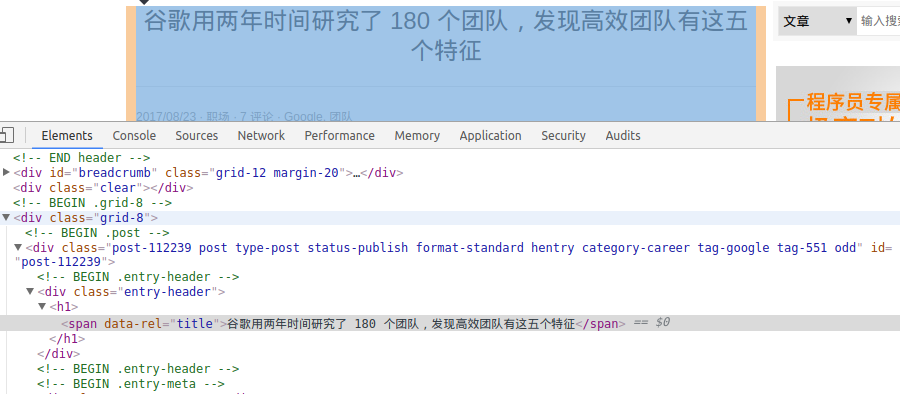
In []: title = response.css(".entry-header h1")
In []: title
Out[]: [<Selector xpath="descendant-or-self::*[@class and contains(concat(' ', normalize-space(@class), ' '), ' entry-header ')]/descendant-or-self::*/h1" data='<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>'>]
In []: title = response.css(".entry-header h1").extract()
In []: title
Out[]: ['<h1>谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征</h1>']
In []: ##可以使用css的::text取到内容
In []: title = response.css(".entry-header h1::text").extract()
In []: title
Out[]: ['谷歌用两年时间研究了 180 个团队,发现高效团队有这五个特征']
获取文章创建日期:
In []: date_text = response.css(".entry-meta-hide-on-mobile").extract()
In []: date_text
Out[]: ['<p class="entry-meta-hide-on-mobile">\r\n\r\n 2017/08/23 · <a href="http://blog.jobbole.com/category/career/" rel="category tag">职场</a>\r\n \r\n · <a href="#article-comment"> 7 评论 </a>\r\n \r\n\r\n \r\n · <a href="http://blog.jobbole.com/tag/google/">Google</a>, <a href="http://blog.jobbole.com/tag/%e5%9b%a2%e9%98%9f/">团队</a>\r\n \r\n</p>']
In []: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()
In []: date_text
Out[]:
['\r\n\r\n 2017/08/23 · ',
'\r\n \r\n · ',
'\r\n \r\n\r\n \r\n · ',
', ',
'\r\n \r\n']
In []: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[
...: ]
In []: date_text
Out[]: '\r\n\r\n 2017/08/23 · '
In []: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[
...: ].strip()
In []: date_text
Out[]: '2017/08/23 ·'
In []: date_text = response.css(".entry-meta-hide-on-mobile::text").extract()[
...: ].strip().replace("·","").strip()
In []: date_text
Out[]: '2017/08/23'
获取评论数
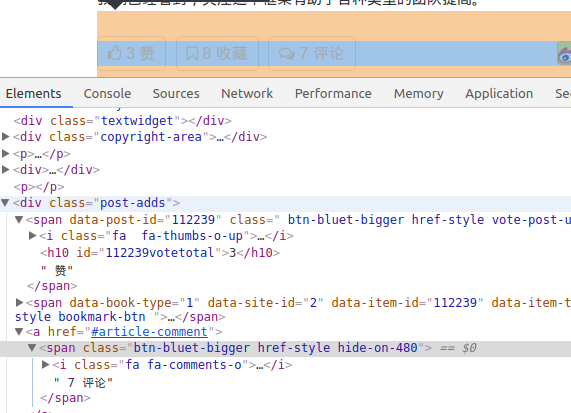
In []: comment_num = response.css("a[href='#article-comment']")
In []: comment_num
Out[]:
[<Selector xpath="descendant-or-self::a[@href = '#article-comment']" data='<a href="#article-comment"> 7 评论 </a>'>,
<Selector xpath="descendant-or-self::a[@href = '#article-comment']" data='<a href="#article-comment"><span class="'>]
In []: comment_num = response.css("a[href='#article-comment'] span::text").ext
...: ract()
In []: comment_num
Out[]: [' 7 评论']
In []: comment_num = response.css("a[href='#article-comment'] span::text").ext
...: ract().strip()
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input--18ae8761867f> in <module>()
----> comment_num = response.css("a[href='#article-comment'] span::text").extract().strip()
AttributeError: 'list' object has no attribute 'strip'
In []: comment_num = response.css("a[href='#article-comment'] span::text").ext
...: ract()[]
In []: comment_num
Out[]: ' 7 评论'
In []:
PS:css选择器里,不同标签使用空格隔开
第七篇 css选择器实现字段解析的更多相关文章
- css选择器优先级全解析
这样一个问题: <!doctype html> <htmllang="en"> <head> <metacharset="UTF ...
- 第七篇 CSS盒子
CSS盒子模型 在页面上,我们要控制元素的位置,比如:写作文一样,开头的两个字会空两个格子(这是在学校语文作文一样),其后就不会空出来,还有,一段文字后面跟着一张图,它们距离太近,不好看,我们要移 ...
- 网页抓取解析,使用JQuery选择器进行网页解析
最近开发一个小功能,数据库中一个基础表的数据从另一个网站采集. 因为网站的数据不定时更新,需要更新后自动采集最新的内容. 怎么判断更新数据没有? 好在网站有一个更新日志提示的地方,只需要对比本地保留的 ...
- 为什么排版引擎解析 CSS 选择器时一定要从右往左解析?
首先我们要看一下选择器的「解析」是在何时进行的. 主要参考这篇「 How browsers work」(http://taligarsiel.com/Projects/howbrowserswork1 ...
- 30个最常用css选择器解析(zz)
你也许已经掌握了id.class.后台选择器这些基本的css选择器.但这远远不是css的全部.下面向大家系统的解析css中30个最常用的选择器,包括我们最头痛的浏览器兼容性问题.掌握了它们,才能真正领 ...
- 30个最常用css选择器解析
转自:http://www.cnblogs.com/yiyuanke/archive/2011/10/22/CSS.html 你也许已经掌握了id.class.后台选择器这些基本的css选择器.但这远 ...
- 看这一篇就够了,css选择器知识汇总
对大多技术人员来说都比较熟悉CSS选择器,举一例子来说,假设给一个p标签增加一个类(class),可是执行后该class中的有些属性并没有起作用.通过Firebug查看,发现没有起作用的属性被覆盖了, ...
- 浏览器如何解析css选择器?
浏览器会『从右往左』解析CSS选择器. 我们知道DOM Tree与Style Rules合成为 Render Tree,实际上是需要将Style Rules附着到DOM Tree上, 因此需要根据选择 ...
- 第四篇、CSS选择器
<html> <head> <meta charset="UTF-8"> <title>CSS选择器</title> & ...
随机推荐
- 常用内置模块(一)——time、os、sys、random、shutil、pickle、json
常用内置模块 一.time模块 在python中,时间分为3种 1.时间戳: timestamp,从1970年1月1日到现在的秒数, 主要用于计算两个时间的差 2.localtime ...
- 打开myeclipse出现这个错是为什么
- 开发效率优化之自动化构建系统Gradle(二)上篇
阿里P7移动互联网架构师进阶视频(每日更新中)免费学习请点击:https://space.bilibili.com/474380680 本篇文章将以下两个内容来介绍自动化构建系统Gradle: gra ...
- Python系列——常用第三方库
幕布视图(更加方便.明了):https://mubu.com/doc/AqoVZ8x6m0 参考文献:嵩天老师的Python讲义 模块 定义 计算机在开发过程中,代码越写越多,也就越难以维护,所以为了 ...
- redis 入门之列表
lpush 将一个或多个值 value 插入到列表 key 的表头如果有多个 value 值,那么各个 value 值按从左到右的顺序依次插入到表头: 比如说,对空列表 mylist 执行命令 LPU ...
- redis 学习入门篇
基本概念 redis是一个开源的.使用C语言编写的.支持网络交互的.可基于内存也可持久化的Key-Value数据库(非关系性数据库). redis的特点 速度快,因为数据存在内存中,读写数据的时候都不 ...
- pytest_参数化之3*3
import pytesttest_user_data1=[{'user':'linda','password':'888888'}, {'user':'servenruby','password': ...
- arcpy-栅格转其他格式
import arcpy in_format=arcpy.GetParameterAsText(0) out_format=arcpy.GetParameterAsText(1) out_folder ...
- Vue项目引入sass
最近两天手头的事情暂时搞完了,可以抽出空来学习一下东西,之前项目都是鹏哥搭建好了,我们在直接在里面写代码,sass语法用来写样式还是比较方便常用的,今天就来试试怎么引入和配置sass 参考文章:Vue ...
- teb教程1
http://wiki.ros.org/teb_local_planner/Tutorials/Setup%20and%20test%20Optimization 简介:本部分关于teb怎样优化轨迹以 ...