hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接
1、集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点
2、解压tar.gz包
[root@node01 ~]# cd software/
[root@node01 software]# ll
总用量
-rw-r--r-- root root 2月 hadoop-2.6..tar.gz
[root@node01 software]# tar xf hadoop-2.6..tar.gz -C /opt/sxt/
[root@node01 software]# cd /opt/sxt/
[root@node01 sxt]# ll
总用量
drwxr-xr-x root root 5月 hadoop-2.6.
3、HADOOP_HOME环境变量的配置
[root@node01 hadoop-2.6.]# vi + /etc/profile
结果如图
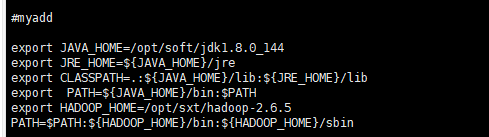
配置完毕之后,要重新的去读取一下这个文件
[root@node01 hadoop-2.6.]# source /etc/profile
4、java环境变量配置文件的配置
转到目录,注意点:hadoop启动 的时候只会去加载这个目录下的配置文件,如果这个目录下有其他的文件夹的话,没有影响

JAVA_HOME的环境变量的二次设置(原因:因为你启动集群的时候的话,你如果不在这个hadoop的文件下设置某些项的话,他会去找你默认本地的java的配置路径,他会找Local ,但是由于是集群启动,根本没有Local这一说,所以你要在一些配置文件中去配置java的路径,让之启动的时候能够找到,如果你不二次配置的话,可能会出现 java command not found)
配置1: hadoop-env.sh 如果你是只是安装HDFS的话,只改这个配置文件就可以了,但是如果之后会用到mapreduce、yarn等,也需要第二三步的配置
[root@node01 hadoop]# vi hadoop-env.sh

配置2: mapred-env.sh
[root@node01 hadoop]# vi mapred-env.sh
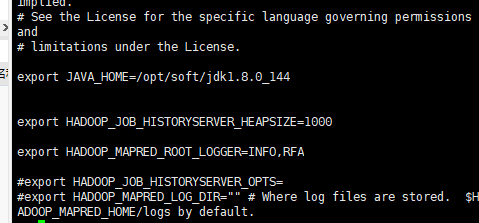
配置3: yarn-env.sh
[root@node01 hadoop]# vi yarn-env.sh
结果

5 hadoop的结点及副本配置文件配置
参考hadoop官网即可
Pseudo-Distributed Operation
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process. Configuration
Use the following: etc/hadoop/core-site.xml:
------------------------------------------------------------------------- <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml: <configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置1:core.env.xml
[root@node01 hadoop]# vi core-site.xml

配置2:
[root@node01 hadoop]# vi hdfs-site.xml

6、第五步配置的是NameNode的配置,这里需要去配置DataNode和SecondaryNameNode了
配置DataNode:slaves
[root@node01 hadoop]# vi slaves
配置第二主节点:默认是配置在 hdfs-site.xml 中的 ,第二个dfs.namenode.secondary.http-adress中的值:是第二主节点在的ip和以及端口号
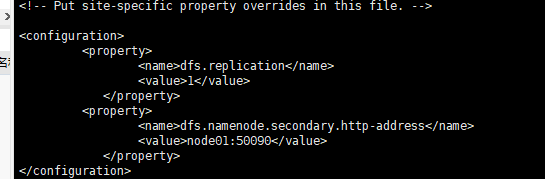
7、更改主结点,从结点的数据的存储位置。因为不更改的话默认是一个临时的文件夹,这样的话,系统可能不会经过你的允许就会删除这个文件!!
[root@node01 hadoop]# vi core-site.xml
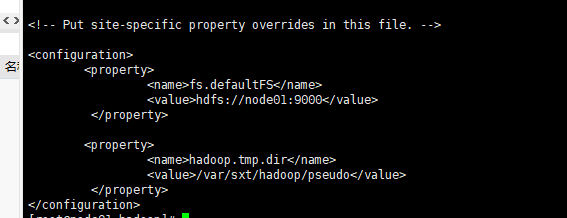
从此所有的配置完成,但是仍需要格式化namenode,生成fsimage文件
8、生成fsimage文件
格式化之前:

格式化命令
[root@node01 hadoop]# hdfs namenode -format #就是为了生成一个fsimage文件
格式化完成

出现
// :: INFO common.Storage: Storage directory /var/sxt/hadoop/pseudo/dfs/name has been successfully formatted.
代表格式化成功
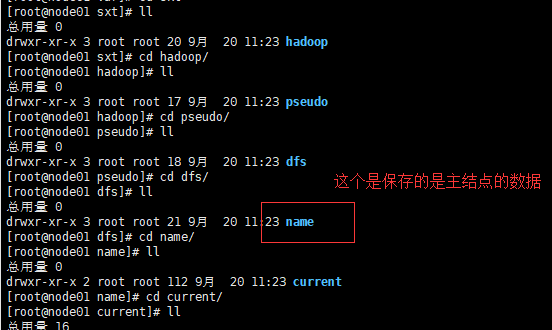
格式化之后,会生成一个目录和一些文件name .内容包括唯一ID、镜像文件等,(特别需要注意的是这个文件所在的位置自己在core-site.xml配置的属性hadoop.tmp.dir的值中设置的),而且在格式化主结点完毕之后。只会生成主结点的数据文件name,,对于从结点和第二主结点的数据文件(data、secondaryNameNode)是当集群启动的时候才会产生的
如下图:

其中包含:fsimage镜像文件,如sfiamge_00000000000
clusterID:集群的唯一标识的ID 这个ID是供集群使用的,集群中的每一个结点都有这样的一个集群ID,而且是一样的,如果不一样的话,就不代表是隶属于一个集群了,特别的需要注意的是:对于集群之前的namenode格式化,只能进行一次,因为进行多次的话,会导致每次都会产生一个新的clusterID,只是主结点的clusterID变了而其他的结点的并没有变,这样的话会导致整个集群启动的时候,一部分启动不起来,只要是集群ID不一样的,就不会启动,这就是多次格式化产生的问题!!!!

注意 :格式化的时候只会产生一个主结点的数据文件夹,name,具体的DataNode和第二主结点的文件夹是在启动集群的时候才会产生的!!!!
到此为止,所有的配置完成,可以启动集群了
启动集群
[root@node01 hadoop-2.6.]# start-dfs.sh
遇见的问题
hadoop伪分布式集群启动出现错误[root@node01 hadoop-2.6.5]# start-dfs.sh
Starting namenodes on [node01] The authenticity of host 'node01 (::1)' can't be established.
ECDSA key fingerprint is SHA256:hCsbjhUULX1rayvyVwh4EVZzIh49utgmghXRynCvVDE. ECDSA key fing
自己不知道是什么问题,jps进程查询也只有DataNode和SecondaryNameNode两个,没有主结点进程,之后从新的启动了一些集群,就有nameNode进程了,
如果有大佬知道的话,还请下方评论,告诉小白我哦,谢谢啦。
下面是第二次启动的时候并没有关闭第一次启动的集群出现的问题:让我们先关闭DataNode和secondaryNamenode两个结点

启动完毕之后,再次转到hadoop.tmp.dir的值指向的那个目录,就会多data和secondaryNameNode两个文件夹了,这分别是针对从结点和第二主节点的文件夹,具体看下图效果

特别需要注意的是:所有的结点的clusterID的值都应该是一样的,因为隶属于同一个集群。因为所有的结点都属于同一个集群,所以才会在集群启动的时候每个结点以不同的进程进行显示
- 具体的从结点中有无数据可以从下面的目录中来看
[root@node01 dfs]# cd data/ #这里的data代表的是从结点
[root@node01 data]# ll
总用量
drwxr-xr-x root root 9月 : current
[root@node01 data]# cd current/
[root@node01 current]# ll
总用量
drwx------ 4 root root 72 9月 20 14:23 BP-782039128-127.0.0.1-1568949808230
-rw-r--r-- root root 9月 : VERSION
[root@node01 current]# cd B*
[root@node01 BP--127.0.0.1-]# ll
总用量
drwxr-xr-x root root 9月 : current
-rw-r--r-- root root 9月 : dncp_block_verification.log.curr
drwxr-xr-x root root 9月 : tmp
[root@node01 BP--127.0.0.1-]# cd current/
[root@node01 current]# ll
总用量
-rw-r--r-- root root 9月 : dfsUsed
drwxr-xr-x 2 root root 6 9月 20 14:23 finalized
drwxr-xr-x root root 9月 : rbw
-rw-r--r-- root root 9月 : VERSION
[root@node01 current]# cd finalized/
[root@node01 finalized]# ll
总用量 0
[root@node01 finalized]# pwd
/var/sxt/hadoop/pseudo/dfs/data/current/BP--127.0.0.1-/current/finalized

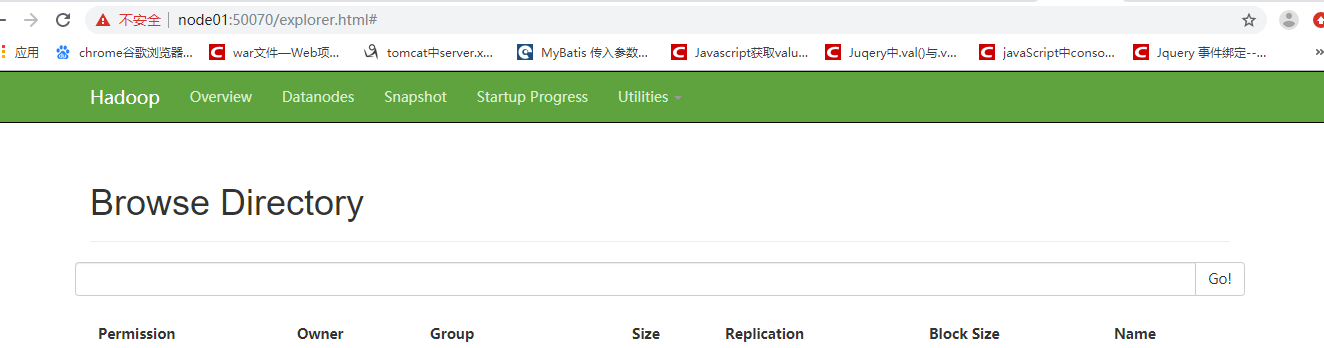
- 一般的集群还会提供一个可视化的管理界面:浏览器访问我们的集群中的HDFS系统的话,默认的浏览器访问集群的端口是50070,而不是9000,9000是结点之间通信的端口
通过浏览器访问自己的集群:http://结点的ip地址或者别名:50070/ 如:http://192.168.27.102:50070/
结果界面

下面来查看自己的集群中的内容:但是还没向集群中上传文件,如果想要上传文件的话,需要先在nameNode的位置创建一个存放数据文件块的路径
未创建之前,从浏览器中存储的内容为空
创建的过程
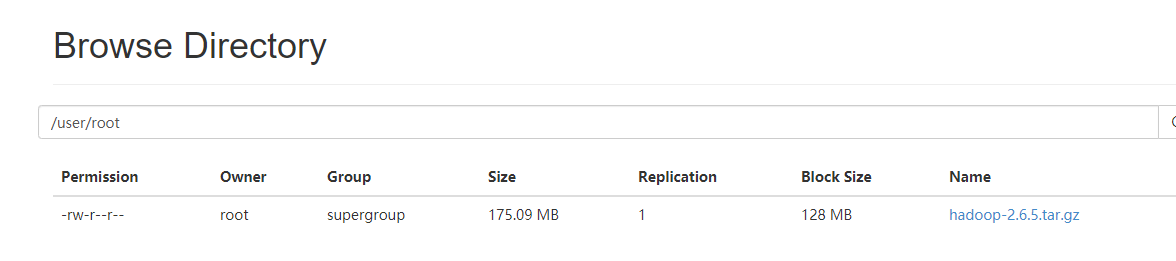
[root@node01 sbin]# hdfs dfs -mkdir -p /user/root 如果不清楚hdfs的命令的话:可以用命令查询 见下面

之后的结果

最后就可以向自己搭建起来的集群中上传数据文件了
上传命令语法

#上传文件
[root@node01 software]# ll
总用量 179292
-rw-r--r-- 1 root root 183594876 2月 26 2019 hadoop-2.6.5.tar.gz
[root@node01 software]# hdfs dfs -put hadoop-2.6.5.tar.gz /user/root
成功
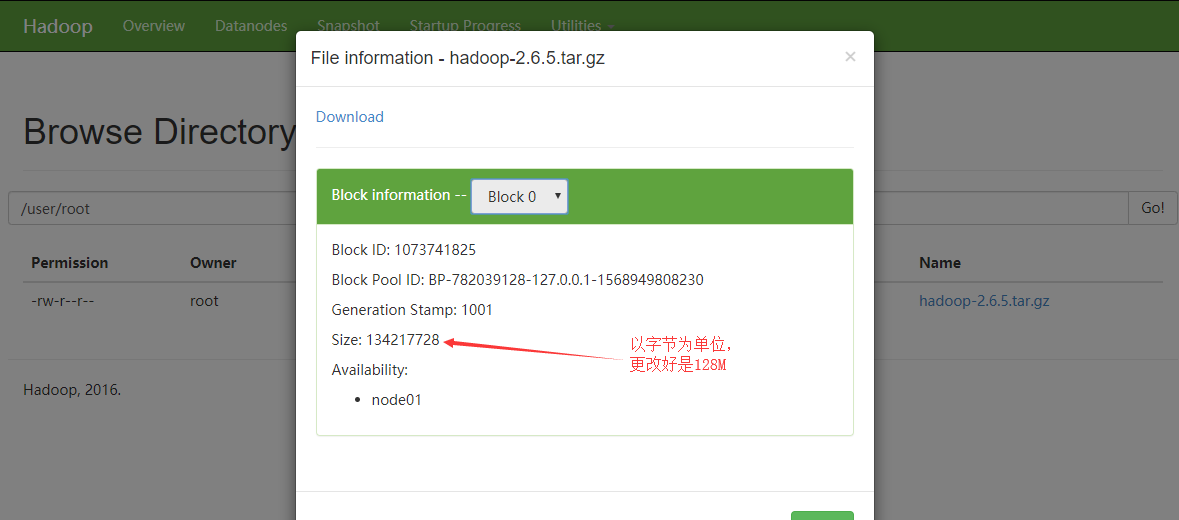
注意点:具体上传的这个文件不是整个的存储的,而是以块的形式存储的,这次上传文件总的大小是175M,所以会分成两块,一个默认的是128M,另一个是175-128M
块0
块1
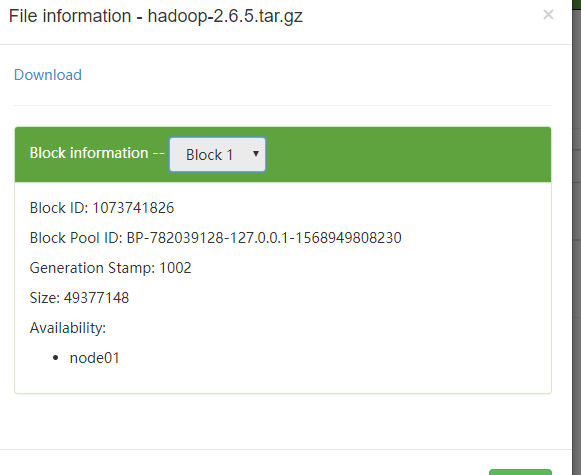
控制台查看,块的存储形式
drwxr-xr-x root root 9月 : pseudo
[root@node01 hadoop]# cd pseudo/
[root@node01 pseudo]# ll
总用量
drwxr-xr-x root root 9月 : dfs
[root@node01 pseudo]# cd dfs/
[root@node01 dfs]# ll
总用量
drwx------ root root 9月 : data
drwxr-xr-x root root 9月 : name
drwxr-xr-x root root 9月 : namesecondary
[root@node01 dfs]# cd data/
[root@node01 data]# ll
总用量
drwxr-xr-x root root 9月 : current
-rw-r--r-- root root 9月 : in_use.lock
[root@node01 data]# cd current/
[root@node01 current]# ll
总用量
drwx------ root root 9月 : BP--127.0.0.1-
-rw-r--r-- root root 9月 : VERSION
[root@node01 current]# cd B*
[root@node01 BP--127.0.0.1-]# ll
总用量
drwxr-xr-x root root 9月 : current
-rw-r--r-- root root 9月 : dncp_block_verification.log.curr
-rw-r--r-- root root 9月 : dncp_block_verification.log.prev
drwxr-xr-x root root 9月 : tmp
[root@node01 BP--127.0.0.1-]# cd current/
[root@node01 current]# ll
总用量
-rw-r--r-- root root 9月 : dfsUsed
drwxr-xr-x root root 9月 : finalized
drwxr-xr-x root root 9月 : rbw
-rw-r--r-- root root 9月 : VERSION
[root@node01 current]# cd finalized/
[root@node01 finalized]# ll
总用量
drwxr-xr-x root root 9月 : subdir0
[root@node01 finalized]# cd subdir0/
[root@node01 subdir0]# ll
总用量
drwxr-xr-x root root 9月 : subdir0
[root@node01 subdir0]# cd subdir0/
[root@node01 subdir0]# ll
总用量
-rw-r--r-- 1 root root 134217728 9月 20 15:57 blk_1073741825
-rw-r--r-- 1 root root 1048583 9月 20 15:57 blk_1073741825_1001.meta
-rw-r--r-- 1 root root 49377148 9月 20 15:57 blk_1073741826
-rw-r--r-- 1 root root 385767 9月 20 15:57 blk_1073741826_1002.meta
[root@node01 subdir0]# pwd
/var/sxt/hadoop/pseudo/dfs/data/current/BP--127.0.0.1-/current/finalized/subdir0/subdir0
[root@node01 subdir0]# pwd
/var/sxt/hadoop/pseudo/dfs/data/current/BP-782039128-127.0.0.1-1568949808230/current/finalized/subdir0/subdir0
其中的 blk_1073741825 块就是我们的block0 blk_1073741826 是block1, blk_1073741825_1001.meta和 blk_1073741826_1002.meta 是两个块的元数据信息,用于验证块的完整性用的
至此,整个伪分布式集群的搭建完成!!!
hadoop学习笔记(五)hadoop伪分布式集群的搭建的更多相关文章
- Hadoop伪分布式集群环境搭建
本教程讲述在单机环境下搭建Hadoop伪分布式集群环境,帮助初学者方便学习Hadoop相关知识. 首先安装Hadoop之前需要准备安装环境. 安装Centos6.5(64位).(操作系统再次不做过多描 ...
- hadoop伪分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 设置静态IP地址 Hadoop伪分布式集群搭建: 为普通用户添加su ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- zookeeper伪分布式集群环境搭建
step1.下载 下载地址:http://zookeeper.apache.org/releases.html 将下载的压缩包放到用户家目录下(其他目录也可以) step2.解压 $tar –zxvf ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop单机/伪分布式集群搭建(新手向)
此文已由作者朱笑笑授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 本文主要参照官网的安装步骤实现了Hadoop伪分布式集群的搭建,希望能够为初识Hadoop的小伙伴带来借鉴意 ...
- hadoop完全分布式集群的搭建
集群配置: jdk1.8.0_161 hadoop-2.6.1 linux系统环境:Centos6.5 创建普通用户 dummy 准备三台虚拟机master,slave01,slave02 hado ...
- ZooKeeper的伪分布式集群搭建
ZooKeeper集群的一些基本概念 zookeeper集群搭建: zk集群,主从节点,心跳机制(选举模式) 配置数据文件 myid 1/2/3 对应 server.1/2/3 通过 zkCli.sh ...
- Hadoop学习笔记(一):ubuntu虚拟机下的hadoop伪分布式集群搭建
hadoop百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin hadoop官网:http://hadoop.apache.org/ ...
随机推荐
- jquery 清除内容
jQuery empty() 方法删除被选元素的子元素. $("#div1").empty(); 清空文本框的值 $("#password").val(&quo ...
- [LGR-054]洛谷10月月赛II
浏览器 结论popcnt(x^y)和popcnt(x)+popcnt(y)的奇偶性相同. 然后就是popcnt为奇数的乘为偶数的.预处理一下\(2^{16}\)次方以内的popcnt,直接\(O(1) ...
- 一点点学习PS--实战一
1.安装ps cc 2017,软件包获取:关注公众号软件管家 2.ps常用快捷键 ALT+J 复制图层 CTRL+T 旋转(右键点击可垂直翻转,画倒影常用) CTRL+M 曲线,提亮图片颜色 CTR ...
- Learning to See in the Dark论文阅读笔记
这是一篇图像增强的论文,作者创建了一个数据集合,和以往的问题不同,作者的创建的see in the dark(SID)数据集合是在极其暗的光照下拍摄的,这个点可以作为一个很大的contribution ...
- cmake编译升级
cmake的升级依赖于gcc版本,例如cmake 3.15.3依赖与gcc 4.8以上的版本 1)先升级gcc到4.8 参考:https://blog.csdn.net/Kangshuo2471781 ...
- EF的预先加载--Eager Loading
预先加载 在对一种类型的实体进行查询时,将相关的实体作为查询的一部分一起加载.预先加载可以使用Include()方法实现. 在此需要说明的是:EF中有两种表关联的方法,一种是Join()方法,一种是I ...
- jQuery操作css
jQuery addClass() 方法 向被选中元素添加class属性,参数为属性值 $("div").addClass("imp"); 也可以同时向多个元素 ...
- Unity中常用的数据结构总结
本篇博文对U3D经常用到的数据结构和各种数据结构的应用场景总结下. 1.几种常见的数据结构 这里主要总结下在工作中常碰到的几种数据结构:Array,ArrayList,List<T>,Li ...
- 1.Java多线程之wait和notify
1.首先我们来从概念上理解一下这两个方法: (1)obj.wait(),当obj对象调用wait方法时,这个方法会让当前执行了这条语句的线程处于等待状态(或者说阻塞状态),并释放调用wait方法的对象 ...
- Go_CSP并发模型
go语言的最大两个亮点,一个是goroutine,一个就是chan了.二者合体的典型应用CSP,基本就是大家认可的并行开发神器,简化了并行程序的开发难度,我们来看一下CSP. 11.1.CSP是什么 ...