spark在不同环境下的搭建|安装|local|standalone|yarn|HA|
spark的集群环境安装搭建

1、spark local模式运行环境搭建
常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
- 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,直接运行在本地,便于调试,通常用来验证开发出来的应用程序逻辑上有没有问题。
- 其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程有1个core)。
- 如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.
第一步:上传压缩包并解压
上传spark压缩包到/export/softwares并解压
将我们编译之后的spark的压缩包上传到/export/softwares路径下,然后进行解压
tar -zxf spark-2.2.0-bin-2.6.0-cdh5.14.0.tgz -C /export/servers/
第二步:修改spark的配置文件
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf cp spark-env.sh.template spark-env.sh
第三步:启动验证进入spark-shell
启动验证
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0 ./bin/spark-shell --master local
退出spark shell客户端
:quit
第四步:运行spark自带的测试jar包
执行我们spark自带的程序jar包运算圆周率
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ --executor-memory 1G \ --total-executor-cores 2 \ /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \ 100
其中100表示迭代计算100次来求取我们圆周率的值,注意迭代计算的次数越多,最终求得的值就会越接近圆周率的值
2、spark的standAlone模式
第一步:修改配置文件
修改spark-env.sh
node01修改spark-env.sh
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf vim spark-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141 export SPARK_MASTER_HOST=node01 export SPARK_MASTER_PORT=7077 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
修改slaves文件
node01修改slaves配置文件
cp slaves.template slaves vim slaves node02 node03
修改spark-defaults.conf
spark的程序运行,我们为了方便调试开发,一般我们都会配置spark的运行日志,将spark程序的运行日志保存到hdfs上面,方便我们运行程序之后的开发调试
node01修改spark-defaults.conf
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf cp spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://node01:8020/spark_log spark.eventLog.compress true
hdfs创建日志文件存放的目录
hdfs dfs -mkdir -p /spark_log
第三步:安装包分发到其他机器
node01服务器执行以下命令
cd /export/servers/ scp -r spark-2.2.0-bin-2.6.0-cdh5.14.0/ node02:$PWD scp -r spark-2.2.0-bin-2.6.0-cdh5.14.0/ node03:$PWD
第四步:启动spark程序
node01服务器执行以下命令启动spark程序
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0 sbin/start-all.sh sbin/start-history-server.sh
第五步:浏览器页面访问
浏览器页面访问spark
查看spark任务的历史日志
第六步:使用进入spark-shell
node01执行以下命令进入spark-shell
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0 bin/spark-shell --master spark://node01:7077
退出spark-shell
scala> :quit
第七步:运行spark自带的测试jar包
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://node01:7077 \ --executor-memory 1G \ --total-executor-cores 2 \ /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \ 100
其中100表示迭代计算100次来求取我们圆周率的值,注意迭代计算的次数越多,最终求得的值就会越接近圆周率的值
3、spark的HA模式

为了解决master单节点的故障,spark也支持master的高可用配置,其中spark的高可用HA模式支持两种方式,一种是手动切换,另外一种是借助zookeeper实现自动切换
第一步:停止spark集群
停止spark的所有进程
node01服务器执行以下命令停止spark集群
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0 sbin/stop-all.sh sbin/stop-history-server.sh
第二步:修改配置文件
修改spark-env.sh
node01服务器修改spark-env.sh
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf vim spark-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141 #export SPARK_MASTER_HOST=node01 export SPARK_MASTER_PORT=7077 export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log" export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181 -Dspark.deploy.zookeeper.dir=/spark"
修改slaves文件(standAlone模式已经修改过,不用修改了)
node01修改slaves配置文件
cp slaves.template slaves vim slaves
node02 node03
修改spark-defaults.conf(standAlone模式已经修改过,不用修改了)
spark的程序运行,我们为了方便调试开发,一般我们都会配置spark的运行日志,将spark程序的运行日志保存到hdfs上面,方便我们运行程序之后的开发调试
node01修改spark-defaults.conf
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf cp spark-defaults.conf.template spark-defaults.conf vim spark-defaults.conf
spark.eventLog.enabled true spark.eventLog.dir hdfs://node01:8020/spark_log spark.eventLog.compress true
hdfs创建日志文件存放的目录
hdfs dfs -mkdir -p /spark_log
第三步:配置文件分发到其他服务器
node01服务器执行以下命令进行分发
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf scp spark-env.sh node02:$PWD scp spark-env.sh node03:$PWD
第四步:启动spark集群
node01服务器执行以下命令启动spark集群
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0 sbin/start-all.sh sbin/start-history-server.sh
node02服务器启动master节点
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0 sbin/start-master.sh
第五步:浏览器页面访问
第六步:进入spark-shell
spark的HA模式,进入spark-shell
node01执行以下命令进入spark-shell
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/ bin/spark-shell --master spark://node01:7077,node02:7077
第七步:运行spark自带的测试jar包
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://node01:7077,node02:7077 \ --executor-memory 1G \ --total-executor-cores \ /export/servers/spark-2.2.-bin-2.6.-cdh5.14.0/examples/jars/spark-examples_2.-2.2..jar \
4、spark的on yarn模式
spark on yarn 模式官方文档说明
http://spark.apache.org/docs/latest/running-on-yarn.html
http://spark.apache.org/docs/latest/running-on-yarn.html#configuration
如果我们的spark程序是运行在yarn上面的话,那么我们就不需要spark 的集群了,我们只需要找任意一台机器配置我们的spark的客户端提交任务到yarn集群上面去即可
小提示:如果yarn集群资源不够,我们可以在yarn-site.xml当中添加以下两个配置,然后重启yarn集群,跳过yarn集群资源的检查
<property> <name> yarn.nodemanager.pmem-check-enabled</name <value>false</value> </property> <property> <name> yarn.nodemanager.vmem-check-enabled</name <value>false</value> </property>
1、环境准备
第一步:三台机器修改spark-env.sh
第一台机器修改spark-env.sh配置文件
第一天机器node01执行以下命令修改spark-env.sh配置文件
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf vim spark-env.sh
export HADOOP_CONF_DIR=/export/servers/hadoop-2.6.-cdh5.14.0/etc/hadoop export YARN_CONF_DIR=/export/servers/hadoop-2.6.-cdh5.14.0/etc/hadoop
将第一台机器的spark-env.sh配置文件同步到第二台和第三台机器上面去
第一台机器执行以下命令同步spark-env.sh配置文件
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/conf scp spark-env.sh node02:$PWD scp spark-env.sh node03:$PWD
第二步:三台机器添加spark环境变量
三台机器修改/etc/profile配置文件添加spark的环境变量
三台机器执行以下命令添加spark环境变量
vim /etc/profile
export SPARK_HOME=/export/servers/spark-2.2.-bin-2.6.-cdh5.14.0 export PATH=:$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
三台机器执行source命令让修改立即生效
source /etc/profile
2、spark on yarn client模式提交任务
1、任务提交命令
node03服务器执行以下命令,将spark计算任务提交到yarn集群上面去
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ /export/servers/spark-2.2.-bin-2.6.-cdh5.14.0/examples/jars/spark-examples_2.-2.2..jar \
2、任务提交过程解析
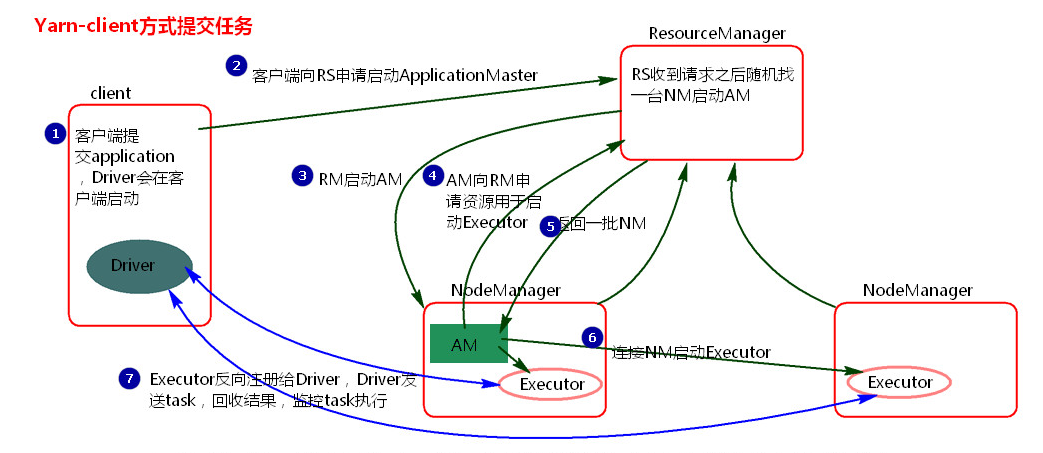
1、客户端提交一个Application,在客户端启动一个Driver进程。
2、Driver进程会向RS(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
3、RS收到请求,随机选择一台NM(NodeManager)启动AM。这里的NM相当于Standalone中的Worker节点。
4、AM启动后,会向RS请求一批container资源,用于启动Executor.
RS会找到一批NM返回给AM,用于启动Executor。
5、AM会向NM发送命令启动Executor。
6、Executor启动后,会反向注册给Driver,Driver发送task到Executor,执行情况和结果返回给Driver端。
总结:
1、Yarn-client模式是适用于测试,因为Driver运行在本地,Driver会与yarn集群中的Executor进行大量的通信,会造成客户机网卡流量的大量增加.
2、 ApplicationMaster的作用:
为当前的Application申请资源
给NodeManager发送消息启动Executor。
注意:ApplicationMaster有launchExecutor和申请资源的功能,并没有作业调度的功能。
3、spark on yarn cluster模式提交任务
1、任务提交命令
node03执行以下命令提交spark任务
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
2、任务提交过程解析
bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores \ /export/servers/spark-2.2.-bin-2.6.-cdh5.14.0/examples/jars/spark-examples_2.-2.2..jar \

执行流程
1、客户机提交Application应用程序,发送请求到RS(ResourceManager),请求启动AM(ApplicationMaster)。
2、RS收到请求后随机在一台NM(NodeManager)上启动AM(相当于Driver端)。
3、AM启动,AM发送请求到RS,请求一批container用于启动Executor。
4、RS返回一批NM节点给AM。
5、AM连接到NM,发送请求到NM启动Executor。
6、Executor反向注册到AM所在的节点的Driver。Driver发送task到Executor。
总结
1、Yarn-Cluster主要用于生产环境中,因为Driver运行在Yarn集群中某一台nodeManager中,每次提交任务的Driver所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过yarn查看日志。
2.ApplicationMaster的作用:
为当前的Application申请资源
给nodemanager发送消息 启动Excutor。
任务调度。(这里和client模式的区别是AM具有调度能力,因为其就是Driver端,包含Driver进程)
3、 停止集群任务命令:yarn application -kill applicationID
3、访问历史日志界面
http://node01:8088/cluster/app/applicationId
注意:如果出现以下这种情况,

这是因为我们在yarn-site.xml当中缺少一行配置,在所有机器的yarn-site.xml当中添加以下配置,然后重启yarn集群以及hadoop的jobHistoryserver即可
第一步:三台机器修改yarn-site.xml配置文件
node01修改yarn-site.xml
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop vim yarn-site.xml
<property>
<name>yarn.log.server.url</name>
<value>http://node01:19888/jobhistory/logs</value>
</property>
node01执行以下命令,将修改后的yarn-site.xml同步到其他机器
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop scp yarn-site.xml node02:$PWD scp yarn-site.xml node03:$PWD
第二步:重新启动yarn以及jobhistoryServer服务
node01执行以下命令重启yarn集群以及jobhistoryserver服务
停止yarn集群以及jobhistoryserver服务
cd /export/servers/hadoop-2.6.0-cdh5.14.0/ sbin/stop-yarn.sh sbin/mr-jobhistory-daemon.sh stop historyserver
重新启动yarn集群以及jobhistoryserver服务
cd /export/servers/hadoop-2.6.0-cdh5.14.0/ sbin/start-yarn.sh sbin/mr-jobhistory-daemon.sh start historyserver
第三步:重新提交spark任务到yarn集群上面去
node03执行以下命令重新提价任务
cd /export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
bin/spark-submit --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ --driver-memory 1g \ --executor-memory 1g \ --executor-cores \ /export/servers/spark-2.2.-bin-2.6.-cdh5.14.0/examples/jars/spark-examples_2.-2.2..jar \
然后就可以查看到spark任务提交的日志了
spark在不同环境下的搭建|安装|local|standalone|yarn|HA|的更多相关文章
- centos下yum搭建安装linux+apache+mysql+php环境
一.脚本YUM源安装: 1.yum install wget #安装下载工具wget 2.wge ...
- centos下yum搭建安装linux+apache+mysql+php环境教程
我们利用linux系统中yum安装Apache+MySQL+PHP是非常的简单哦,只需要几步就可以完成,具体如下: 一.脚本YUM源安装: 1.yum install wget ...
- 007 关于Spark下的第二种模式——standalone搭建
一:介绍 1.介绍standalone Standalone模式是Spark自身管理资源的一个模式,类似Yarn Yarn的结构: ResourceManager: 负责集群资源的管理 NodeMan ...
- Spark集群搭建(local、standalone、yarn)
Spark集群搭建 local本地模式 下载安装包解压即可使用,测试(2.2版本)./bin/spark-submit --class org.apache.spark.examples.SparkP ...
- Spark 在 Window 环境下的搭建
1.java/scala的安装 - 安装JDK下载: http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-21 ...
- 【转】android 最新 NDK r8 在window下开发环境搭建 安装配置与使用 详细图文讲解,完整实际配置过程记录(原创)
原文网址:http://www.cnblogs.com/zdz8207/archive/2012/11/27/android-ndk-install.html android 最新 NDK r8 在w ...
- android 最新 NDK r8 在window下开发环境搭建 安装配置与使用 详细图文讲解,完整实际配置过程记录(原创)
android 最新 NDK r8 在window下开发环境搭建 安装配置与使用 详细图文讲解,完整实际配置过程记录(原创) 一直想搞NDK开发却一直给其他事情耽搁了,参考了些网上的资料今天终于把 ...
- Android NDK r8 Cygwin CDT 在window下开发环境搭建 安装配置与使用 具体图文解说
版权声明:本博客全部文章均为原创.欢迎交流.欢迎转载:转载请勿篡改内容,而且注明出处,谢谢! https://blog.csdn.net/waldmer/article/details/3272500 ...
- CentOS6.5下源码安装多个MySQL实例及复制搭建
多实例安装本节是在CentOS6.5下源码安装MySQL5.6.35的基础上,在同一台机器增加一个MySQL实例.参考Centos中安装多个mysql数据的配置实例,安装目录为/usr/local/m ...
随机推荐
- 30分钟全方位了解阿里云Elasticsearch
摘要:阿里云Elasticsearch提供100%兼容开源Elasticsearch的功能,以及Security.Machine Learning.Graph.APM等商业功能,致力于数据分析.数据搜 ...
- 阿里云资深技术专家黄省江:让天下没有难做的SaaS
导语:本文中,阿里云资深技术专家黄省江(花名禅笑)将聚焦“SaaS加速器——让天下没有难做的SaaS”,对伙伴来说,SaaS加速器帮助他们做好SaaS,卖好SaaS:对企业来说,SaaS加速器帮助他们 ...
- sql 条件查询
使用SELECT * FROM <表名>可以查询到一张表的所有记录.但是,很多时候,我们并不希望获得所有记录,而是根据条件选择性地获取指定条件的记录,例如,查询分数在80分以上的学生记录. ...
- JCF——Map
Hashtable LinkedHashMap Properties
- 质数密度+思维——cf1174D
/* 构造 n个点的无向图,无重边自环 边数e也是质数 点的度数也是质数 */ #include<bits/stdc++.h> #include<vector> using n ...
- (转)Linux查看程序端口占用情况
转:http://www.cnblogs.com/benio/archive/2010/09/15/1826728.html 今天发现服务器上Tomcat 8080端口起不来,老提示端口已经被占用. ...
- Dynamic partition strict mode requires at least one static partition column.
https://blog.csdn.net/huobumingbai1234/article/details/81099856
- c#委托(Delegates)--基本概念及使用 转发
在我这菜鸟理解上,委托就是可以用方法名调用另一方法的便捷方法,可以简化switch等语句的重复.最近做项目的时候恰好需要用到委托,便来复习及学习委托的使用.嗯...本人以前并没有用过,只是稍微知道而已 ...
- 文本表征:SoW、BoW、TF-IDF、Hash Trick、doc2vec、DBoW、DM
原文地址:https://www.jianshu.com/p/2f2d5d5e03f8 一.文本特征 (一)基本文本特征提取 词语数量 常,负面情绪评论含有的词语数量比正面情绪评论更多. 字符数量 常 ...
- URAL 1748 The Most Complex Number
题目链接:https://vjudge.net/problem/11177 题目大意: 求小于等于 n 的最大反素数. 分析: n <= 10^18,而前20个素数的乘积早超过10^18,因此可 ...