2014-VGG-《Very deep convolutional networks for large-scale image recognition》翻译
2014-VGG-《Very deep convolutional networks for large-scale image recognition》翻译
题目:用于大规模图像识别的非常深层的网络
摘要
在这项工作中,我们调查了在大规模图像识别设置中,卷积神经网络的深度对其精确度的影响。我们的主要贡献是使用具有非常小(3 * 3)卷积滤波器的架构对于增加了深度的网络的全面评估,这表明将通过将深度推到16-19个权重层可以实现对现有技术配置的显著改进。这些发现是我们ImageNet Challenge 2014提交的基础,我们的团队分别在定位和分类问题中获得了第一和第二名。我们还表明,我们的方法很好地推广到了其他数据集上,在那里他们实现了最好的结果。我们已经使我们的两个性能最好的ConvNet模型公开可用,以便进一步研究在计算机视觉中使用深度视觉表示。
1 引言
卷积网络(ConvNets)最近在大规模图像和视频识别方面取得了巨大的成功,由于大型的公共图像库,高性能计算系统,例如GPU或者大规模的分布式集群。特别的,ImageNet大规模视觉识别挑战(ILSVRC)在深度视觉识别架构中发挥了重要的作用,它已经作为几代大型图像分类系统的实验台了,从高维的浅特征编码到深的ConvNets。
随着ConvNets在计算机视觉领域变得越来越流行,已经进行了许多尝试来改进Krizhevsky等人的原始结构,以达到更好的准确性。例如,ILSVRC-2013中最好的提交使用较小的接受窗口大小和在第一个卷积层更小的步长。另一个改进涉及在整个图像和多个尺度上密集地训练和测试网络。在本文中,我们讨论了ConvNet架构设计的另一个重要方面-深度。最后,我们固定了结构的其他参数,并通过添加更多的卷积层来稳定地增加网络的深度,这种方法的可行性是因为在所有层中都使用了非常小的(3*3)的卷积滤波器。
结果,我们提出了更加准确的ConvNet的结构,它不仅实现了在ILSVRC分类和定位任务的最好的精度,而且也适用于其他的图像识别数据集。在这些数据集中本文的方法即使是用作相对简单的管道(例如,由没有经过微调的线性SVM分类的深度特征)的一部分,也实现了非常卓越的性能表现。我们已经发布了两个最好的模型,以促进进一步的研究。
本文的其余部分组织如下。在第2部分,我们描述我们的ConvNet的配置。图像分类训练和评估的细节展示在第3部分。关于ILSVRC分类任务的配置比较是在第4部分。第5节总结本文。为了完整性,我们还在附录A中描述和评估了我们的ILSVRC-2014目标定位系统,并在附录B中讨论了对其他数据集的深层特征的泛化能力。最后,附录C包含了主要论文修定版本的列表。
2 ConvNet配置
为了测量在公平的环境中增加的ConvNet深度带来的改进,我们所有的ConvNet层的配置使用与Ciresan(2011)和Krizhevsky(2012)相同的原则设计。在本节中,首先描述了我们的ConvNet的配置(第2.1节)的通用布局,然后详细介绍了评估中使用的具体配置(2.2节)。然后在2.3节讨论了我们的设计选择并将其与现有的技术相比较。
2.1 架构
在训练期间,我们的ConvNet的输入是固定大小的224 * 224的RGB图像。我们做的唯一的预处理是从每个像素值上减去在训练集上计算的平均RGB值。图像通过一堆卷积层(conv.),其中我们使用具有非常小的接收野的滤波器:3 * 3(这是捕获左/右,上/下,中心概念的最小尺寸)。在其中一个配置中,我们还使用了1 * 1的卷积过滤器,这可以看作是输入通道的线性变换(之后接一个非线性变换)。卷积步长固定为1个像素;卷积层的输入的空间填充是使得在卷积之后保留空间分辨率,如,对于一个3 * 3的卷积层来说填充是1个像素。空间池化是由5个最大池化层执行的,基在一些卷积层后面(不是所有的卷积层之后都跟着最大池化层)。最大池化是在2*2的像素窗口上执行的,步长为2。
一堆卷积层(在不同的架构中具有不同的深度)之后是三个全连接层(FC):前两个每一个都有4096个通道,第三个执行1000类的ILSVRC分类,因此包含1000个通道(每个类一个通道)。最后一层是soft-max层。全连接层的配置在所有网络中都是相同的。
所有的隐藏层都配有修正的非线性单元(ReLU)。注意到我们的网络只有一个包含有局部响应正则化(LRN):会在第4节中展示,这种正则化不会改善在ILSVRC数据集中的性能,但会导致内存消耗和计算时间增加。在适用的情况下,LRN层的参数是(Krizhevsky et al., 2012)等人的参数。
2.2 配置
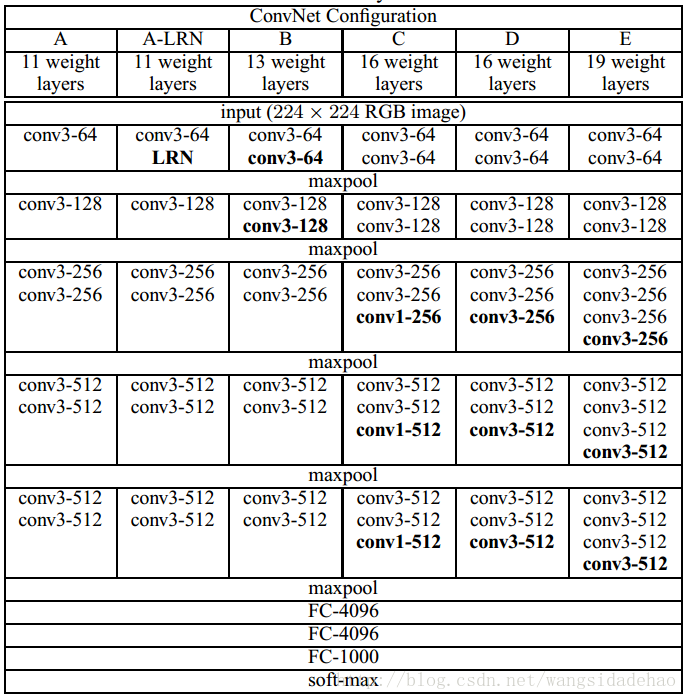
本文评估的ConvNet配置在表1中罗列,每列一个。在下文中我们将会通过他们的名字(A-E)来指代网络。所有配置都遵循2.1节中提出的通用设计,仅在深度上有所不同:从网络A的11个权重层(8个卷积层和3个全连接层)到网络E的19个权重层(16个卷积层和3个全连接层)。卷积层的宽度(通道的数量)越来越大(PS:感觉论文说错了,论文是rather small),从第一层的64个开始,然后在每个最大池化层之后以2次幂增加,直到其达到512。
在表2中,我们报告了每个配置的参数数量。尽管有较大的深度,我们网络中权重的数量不大于具有较大的卷积层宽度和接收野的较浅的网络中的权重的数目(114M个权重在(Sermanet等人,2014))。
2.3 讨论
我们的ConvNet配置与ILSVRC-2012(Krizhevsky等人 2012)和ILSVRC-2013比赛(Zeiler & Fergus, 2013; Sermanet 等人, 2014)中表现最好的模型有很大的不同。我们在第一个卷积层没有使用相对大的感受野(例如,在(Krizhevsky et al., 2012)中是11 * 11 步长是4,或者在 (Zeiler & Fergus,2013; Sermanet et al., 2014)中是7 * 7 步长是2, 而是在整个网络中使用了非常小的3 * 3 的感受野,对输入中的每一个像素进行卷积处理,步长为1。很容易看到两个3 * 3 的卷积层(中间不带空间池化)和一个5 * 5的卷积层具有相同的感受野(PS: 就是说假如输入是5*5的图像,用3*3的filter卷积之后输入图像变成3*3,再来一个3 * 3 的filter卷积后输入图像变成1*1 。这和直接用一个5*5的filter卷积图像是一样的效果;)。3个这样的层就会相当于一个7*7的感受野。所以我们通过使用,例如,三个3*3卷积层的堆叠而不是单个的7*7的卷积层,我们获得了什么?我们引入了三个非线性修正层,而不是一个,这使得决策函数更具有辨别力。第二,我们减少了参数的数量:假设三层3*3的卷积层的一个堆的输入和输出都具有C个通道(PS:通道就是卷积层的输出数量,还需要注意的是输入也是C个通道,后面的公式就好理解了)。这个堆就由3(32C2)=27C23(32C2)=27C2个权重参数化(PS:第一个3是3层,第二个3的平方是filter的大小,因为输入也是C个通道,输出C个通道的每一个的权重都对应着C个,所以是C2C2)。同时,一个单独的7*7的卷积层将会需要72C2=49C272C2=49C2个参数,比上面的多了81%还多(27 的81%是21.87,加上27 是48.87,所以比81%还多)。这可以被看成是对7*7的卷积过滤器强加了一个正则化,迫使它们通过3*3滤波器(在其间注入非线性)进行分解。
表一:ConvNet配置(以列展示)。配置的深度从左(A)向右(E)增加,因为添加了更多的层(添加的层以粗体表示)。卷积层参数表示成“conv<感受野大小>-<通道数量>”。为了简洁,未展示ReLU激活函数

引入1*1卷积层(表1,配置C)是增加决策树的非线性而不影响卷积层的感受野的方式。即使在我们的情况下,1*1卷积本质上是在相同维度空间上的线性映射(输入和输出通道的数量是相同的),由修正函数引入附加的非线性。应当注意,1*1的卷积层最近已经被用于Lin等人(2014)的“Network in Network”架构中。小尺寸的卷积滤波器之前已由 Ciresan(2011)等人使用,但是他们的网络没有我们的网络深,并且他们没有在大规模ILSVRC数据集上进行评估。Goodfellow等人(2014)将深层ConvNets(11个权重层)应用到街道号码识别任务中,并且表明增加的深度能产生更好的性能。GoogLeNet(Szegedy等人2014)是ILSVRC-2014分类任务中表现最好的一个模型,它是独立于我们的工作开发的,但是类似的是它基于非常深的ConvNets(22个权重层)和非常小的卷积过滤器(除了3*3的,他们也使用1*1和5*5的卷积)。然而,他们的网络拓扑结构比我们的更复杂,在第一层中更剧烈的减少特征映射的空间分辨率以减少计算量。如第4.5节所示,我们的模型在单网络分类精度方面优于Szegedy等人(2014)的模型。
3 分类框架
在上一节中,我们展示了我们网络配置的细节。在本节中,我们描述分类ConvNet训练和评估的细节。ConvNet的训练过程一般遵循Krizhevsky等人的方法(除了从不同尺寸的训练图像中抽取剪裁的图像,会在正文中解释)。也就是通过使用带有momentum的mini-batch梯度下降算法(基于(LeCun,1989)等人的反向传播)来优化多项逻辑回归目标函数,以此来达到训练目的。批量(batch)大小被设置成256,momentum设置成0.9。训练通过权重衰减(L2惩罚系数设置成5∗10−45∗10−4)和对前两个全连接进行droupout正则化(随机失活率设成0.5)来达到规则化的目的。学习率最初设置为10−210−2,然后当在验证集上的精度停止提高时学习率以10倍的速率向下减。总的来说,学习率降低了3次,并且在370K次迭代(74次训练)之后停止学习。我们推测,与Krizhevsky等人相比,尽管我们的网络具有更大的参数量和更大的深度,但是我们的网络需要更少的训练次数就会收敛,由于(a)更大的深度和更小的卷积过滤器大小施加的隐性的正则化;(b)某些层的预初始化。
网络权重的初始化是非常重要的,因为坏的初始化可能会由于深度网络中的梯度的不稳定性而使得学习停止。为了规避这个问题,我们开始训练配置A(表1),它是足够浅的可以用随机初始化来训练。当训练更深的架构时,我们用网络A的初始化前四个卷积层和最后三个全连接层(中间层被随机初始化)。我们没有降低预初始化层的学习速率,允许它们在学习期间改变。对于随机初始化(如果适用的话),我们从均值为0,方差为10−210−2的正态分布中抽样权重。偏差用零初始化。值得注意的是,在提交论文之后,我们发现可以通过使用Glorot & Bengio (2010)的随机初始化过程来初始化权重,而不用进行预训练。
为了获得固定大小的224*224ConvNet输入图像,它们从重新绽放的训练图像上随机裁剪(每次SGD迭代一个图像上一个裁剪)。为了进一步增加训练集,对剪裁的图像进行随机水平翻转和随机的RGB颜色转移(Krizhevsky等人2012)。训练图像的重新缩放会在下文解释。
训练图像大小。令S是各向同性重新缩放的训练图像的最小侧,从中截取ConvNet的输入(我们也将S称为训练尺度)。当裁剪尺寸固定为224*224时,原则上S可以取不小于224的任何值:对于S=224来说,裁剪将会捕获整个的图像统计数据,将会完整横跨训练图像的最小边。对于S ≫ 224,裁剪将会对应于图像的一小部分,包括一个小对象,或者对象的一部分。
我们考虑两种方法来设置训练尺寸S。第一种就是固定S,这对应于单一尺寸的训练(注意,在抽样裁剪内的图像内容仍然可以代表多尺度的图像统计数据)。在我们的实验中,我们评估了以两个固定尺寸训练的模型:S = 256(其在先前的工作中被广泛使用(Krizhevsky et al., 2012; Zeiler & Fergus, 2013; Sermanet et al., 2014))和S = 384。给定ConvNet配置,我们首先使用S = 256训练网络。为了加速S=384网络的训练,使用S=256预训练的权重初始化训练,并且我们使用了较小的初始学习率10−310−3。设置S的第二种方法是多尺度训练,其中通过从某个范围[SminSmin, SmaxSmax](我们使用SminSmin=256,并且SmaxSmax=512)随机采样S来单独地重新缩放每个训练图像。因为图像中的对象可以具有不同的大小,因此在训练期间将这一点考虑进去是非常有益的。这也可以看成是通过尺寸抖动的训练集增加,其中单个模型被训练以识别大范围尺度上的对象。出于速度上的考虑,我们通过微调具有相同配置的单尺度模型的所有层来训练多尺度模型,用固定的S = 384来预训练。
3.2 测试
在测试时,给定训练的ConvNet和一个输入图像,它按以下方式分类。首先,它被各向同性地重新缩放到预定义的图像的最小边,表示为Q(我们也称为测试尺寸)。我们注意到Q不一定等于训练尺寸S(如我们将在第4节中展示的,对每个S使用几个Q值来改善性能)。然后,以类似于(Sermanet等人,2014)的方式将网络密集地应用于重新缩放的测试图像。也就是说,全连接层首先被转换成卷积层(第一个FC层转换成7*7的卷积层,最后两个FC层转换成1*1的卷积层)。然后将所得到的全卷积网络应用于整个(未剪裁)图像。结果是类别分数图(其通道数量等于类的数量)和一个变化的空间大小(取决于输入图像的大小)。最后,为了获得图像的类分数的固定大小的向量,类别分数图被空间平均了(sum-pooled)。我们也通过水平翻转图像来增加测试集;将原始图像和翻转图像的soft-max分类后验概率进行平均以获得图像的最终分数。
由于全卷积网络是应用于整个图像上的,因此在测试的时候不需要抽取多个剪裁 (Krizhevsky et al., 2012),因为它需要对每个裁剪进行网络的重新计算,所以效率低下。同时,如Szegedy et al. (2014)做的一样,使用大量的裁剪,可以导致精度的提升,因为它导致输入图像比全卷积网络有更精细的采样。此外,由于不同的卷积边界条件,多裁剪评估与密集评价互补:当将ConvNet应用于剪裁的图像时,卷积特征图用零填充,而在密集评估时,用于相同的裁剪的图像的填充自然来自于图像的相邻部分(由于卷积和空间池化),这大大增加了整个网络的感受野,因此捕获了更多的上下文信息。虽然我们相信在实践中由多裁剪增加的计算时间并不能证明准确性的潜在增加,但是做为参考,我们也评估了我们的网络在每个尺寸上使用了50个剪裁(25个规则网格和2个翻转),在3个尺寸上总共150个裁剪图像,这与Szegedy et al. (2014)等人使用的的4个尺寸上的144个裁剪图像相对比。
3.3 实现细节
我们的实现源自公开提供的C++Caffe工具箱(2013年12月提供),但是包含了一些重要的修改,允许我们在安装在单个系统中的多个GPU上执行训练和评估,并且也可以在多尺度(如上所述)上对全尺寸(未裁剪)的图像进行训练和评估。多GPU训练利用了数据的并行性,并且通过将每批训练图像分割成若干GPU小批块来执行,并且在每块GPU上并行处理。在计算GPU小批块梯度之后,将它们平均以获得整个批次的梯度。梯度计算在多个GPU上是同步的,因此结果与在单个GPU上训练时的结果完全相同。虽然最近提出了加速ConvNet训练的更复杂的方法(Krizhevsky, 2014),它们对网络的不同层采用模型和数据的并行处理,但是我们发现,我们概念上更简单的方案在现成的4-GPU系统上已经提供了3.75倍的加速,与使用单个GPU相比。在配备有四个NVIDIA Titan Black GPU的系统上,根据架构不同训练一个单独的网络需要2-3周。
4. 分类实验
数据集。在本节中,我们介绍了通过上文描述的ConvNet结构在ILSVRC-2012数据集(用于ILSVRC2012-2014挑战赛)上实现的图像分类结果。这个数据集包含了1000类的图像,并且被分成了3个集合:训练集(1.3M个图像),验证集(50K的图像),和测试集(100K图像带有类标签)。使用两种测量方法来评估分类性能:top-1和top-5的误差。前者是多类分类误差,例如,不正确分类的图像的比例。后者是ILSVRC中使用的主要评估标准,按如下方法计算,正确类别在前5个预测类别之外的的图像所占的比例。对于大多数实验,我们使用验证集作为测试集。在测试集上也进行了一些实验,并作为“VGG”团队进入ILSVRC-2014比赛(Russakovsky et al., 2014)提交给官方ILSVRC服务器。
4.1 单一尺度评估
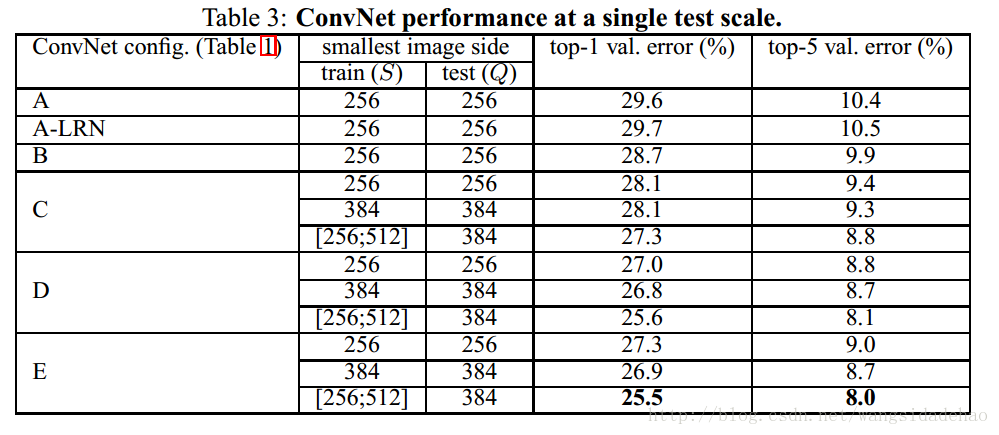
我们开始评估单个ConvNet模型在单个尺度上的性能,用的上2.2节描述的层配置。测试图像大小设置如下:Q=S,S固定,和 Q=0.5(Smin+SmaxSmin+Smax),S∈[Smin,Smax]S∈[Smin,Smax]。结果展示在表3中。
首先,我们注意到,使用局部响应归一化(A-LRN网络)在没有任何归一化层的模型A上没有提升。因此,我们不在更深的架构(B-E)中采用归一化。
第二,我们观察到分类误差随着ConvNet的深度的增加而减小:从A中的11层到E中的19层。值得注意的是,尽管深度相同,配置C(包含了三个1*1的卷积层)比整个网络中使用3*3的卷积层的配置D更差。这表明虽然附加了非线性确实有帮助(C比B好),但是通过使用具有更大感受野的卷积过滤器来捕获空间上下文也是非常重要的(D优于C)。当深度达到19层时,我们架构的错误率达到饱和,但是可能更深的模型对于更大的数据集会有益。我们还将网络B与具有5个5*5的卷积层的浅层网络进行比较。其通过用单个5*5的卷积层代替B中的每对3*3的卷积层得来(正如2.3节解释的那样,他们具有相同的感受野)。浅层网络的top-1误差被测量为高于B(在中心裁剪上)7%,这证实了具有小过滤器的深度网络优于具有较大过滤器的浅层网络。
最后,即使在测试的时候使用单个尺度,训练时候的尺度抖动(S∈[256,512]S∈[256,512])比在具有固定最小边(S=256或S=384)的图像上训练产生明显的更好的结果。这证实了通过尺寸抖动的训练集的增加确实有助于捕获多尺度的图像统计数据。
4.2 多尺度评估
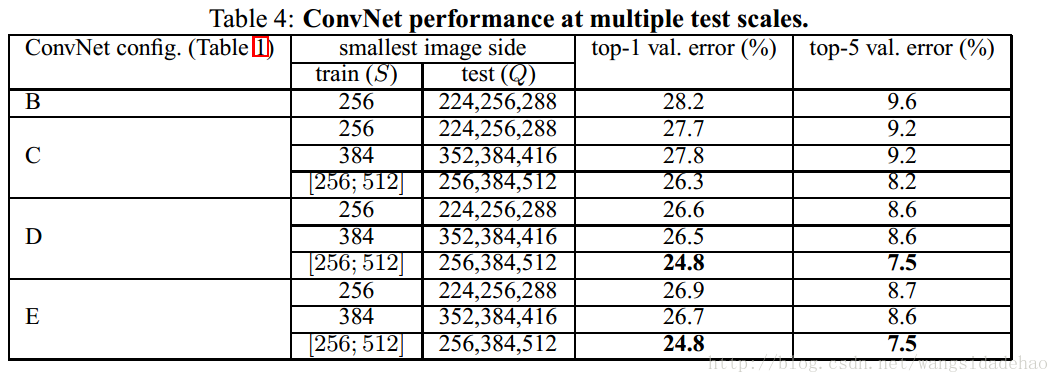
已经在单个尺度上评估了ConvNet模型后,我们现在在测试的时候评估尺度抖动的影响。它包括在一个测试图像(对应于不同的Q值)的几个重新缩放的版本上运行一个模型,然后平均所得到的类的后验概率。考虑到训练和测试尺度之间的大的差异会导致性能的下降,用固定的S训练的模型在三个测试图像尺度(接近于训练时的尺度:Q={S-32,S,S+32})上进行评估。与此同时,训练时候的尺度抖动允许网络在测试的时候应用于更宽的尺度范围,所以用变化的S(S∈[Smin,Smax]S∈[Smin,Smax])训练的模型可以在较大的尺度范围内进行评估(Q=Smin,0.5(Smin+Smax,Smax),SmaxQ=Smin,0.5(Smin+Smax,Smax),Smax)。
表4中呈现的结果表明测试时候的尺度抖动会导致更好的性能(对比于表3中所示的在单个尺度上评估相同的模型)。与以前一样,最深的配置(D和E)表现最好,尺度抖动的训练比用固定最小边S训练效果要好。我们在验证集上的最佳单一网络的性能是24.8%/7.5% 对应于top-1/top-5 错误率(在表4中以粗体显示)。在测试集上,配置E实现了7.3%的Top-5错误率。
4.3 多裁剪评估
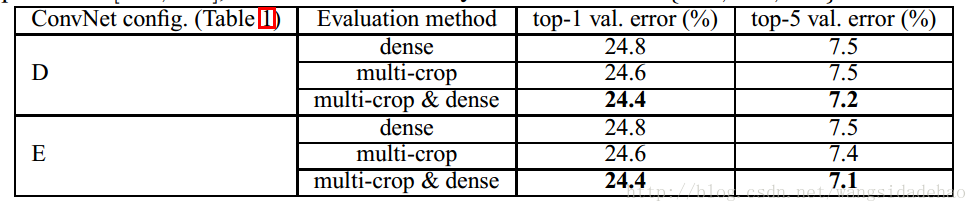
在表5中我们比较了密集ConvNet评估与多裁剪评估(详见第3.2节)。我们还通过平均Softmax输出来评估两种评估技术的互补性。可以看出,使用多种剪裁表现要略好于密集评估,并且这两种方法确实是互补的,因为它们的结合优于他们中的每一种。如上所述,我们假设这是由于卷积边界条件的不同处理造成的。
表5:ConvNet评估技术对比。在所有的实验中训练尺度S是从[256; 512]中抽取的,并且3个测试尺度Q被认为是:{256,384,512}。
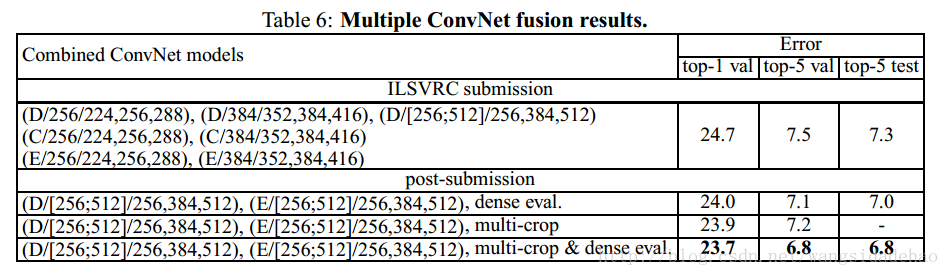
4.4 ConvNet融合
到目前为止,我们只计算了一个ConvNet模型的性能。在实验部分,我们通过平均几个模型的soft-max类的后验概率来结合输出。由于模型之间的互补,这种方法提高了性能,并且在2012年 (Krizhevsky et al., 2012) 和2013年 (Zeiler & Fergus, 2013; Sermanet et al., 2014)被顶级的ILSVRC提交使用。
结果展示在表6中。到ILSVRC提交的时间,我们仅仅训练了一个单一尺度的网络,和一个多尺度的模型D(仅仅通过微调了全连接层而不是所有层)。所得到的7个网络的融合具有7.3%的ILSVRC测试错误率。在提交之后,我们考虑只融合两个表现最好的多尺度模型(配置D和E),这种方法在使用密集评估的时候将错误率减少到了7.0%,并且在使用密集和多尺度评估组合的时候将错误率减少到了6.8%。做为参考,我们最好的单个模型实现了7.1%的错误率(模型E,表5)。
4.5 与现有技术的比较
最后,我们在表7中将我们的结果与现有的技术进行了比较。在ILSVRC-2014挑战赛的分类任务(Russakovsky et al., 2014)中,我们的“VGG”团队使用7个模型的融合用7.3%的测试错误率达得到了第2。提交之后,我们使用2个模型的融合将错误率减少到了6.8%。 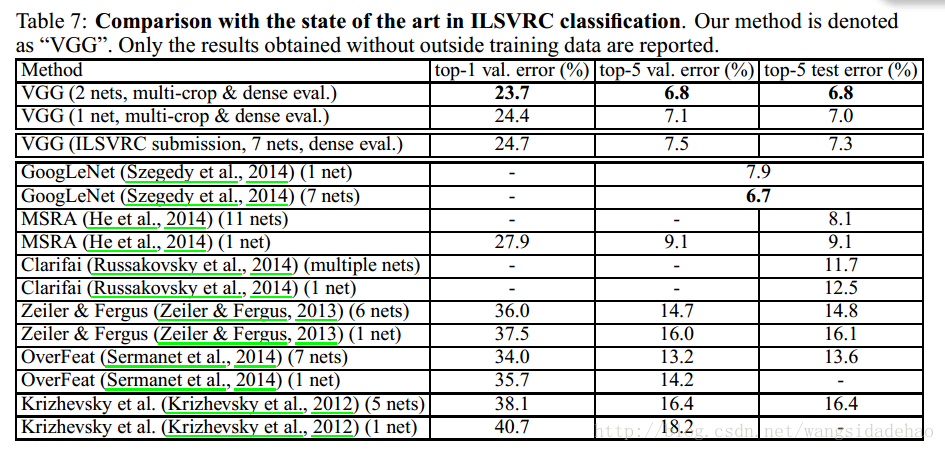
在表7中可以看出,我们的非常深的ConvNets明显优于上一代模型,它们在ILSVRC-2012和ILSVRC-2013竞赛中实现了最好的结果。我们的结果对于分类任务的冠军(GoogLeNet with 6.7% error)也是非常具有竞争性的,并且大大优于ILSVRC-2013的冠军提交的模型Clarifai,它在用了外部训练数据的情况下实现了11.2%,在没用外部数据的情况下实现了11.7%。值得注意的是我们最好的结果是仅仅融合了两个模型实现的-显著小于大多数ILSVRC提交中使用的。关于单一网络性能,我们的结构实现了最好的结果(7.0%的测试错误率),比超过单一GoogLeNet0.9%。值得注意的是,我们没有偏离 LeCun et al. (1989)的经典结构,而且大大提升了它的深度。
5 结论
在这次工作中我们评估了非常深的卷积神经网络(达到19层)用于大规模的图像分类。证明了深度有益于分类准确度,在ImageNet挑战数据集上的最先进的表现可以使用一个ConvNet架构(LeCun et al., 1989; Krizhevsky et al., 2012)加上深度的增加来实现。在附录中,我们还显示我们的模型适用于各种各样的任务的数据集,匹配或超过了构建在较深图像表示上的更复杂的管道。我们的结果再次证实了在视觉表示中深度的重要性。
2014-VGG-《Very deep convolutional networks for large-scale image recognition》翻译的更多相关文章
- VGG——Very deep convolutional networks for large-scale image recognition
1. 摘要 在使用非常小(3×3)的卷积核情况下,作者对逐渐增加网络的深度进行了全面的评估,通过设置网络层数达 16-19 层,最终效果取得了显著提升. 2. 介绍 近来,卷积神经网络在大规模图像识别 ...
- VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNTION(翻译)
0 - ABSTRACT 在这个工作中,我们研究了卷积网络的深度对于它在大规模图像识别设置上的准确率的效果.我们的主要贡献是对使用非常小的卷积核(3×3)来增加深度的网络架构进行彻底评估,这说明了通过 ...
- 大规模视觉识别挑战赛ILSVRC2015各团队结果和方法 Large Scale Visual Recognition Challenge 2015
Large Scale Visual Recognition Challenge 2015 (ILSVRC2015) Legend: Yellow background = winner in thi ...
- VGGNet论文翻译-Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition Karen Simonyan[‡] & Andrew Zi ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- Very Deep Convolutional Networks for Large-Scale Image Recognition
Very Deep Convolutional Networks for Large-Scale Image Recognition 转载请注明:http://blog.csdn.net/stdcou ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
随机推荐
- Django项目基础配置和基本使用
博文配置内容包括: django项目的创建 django项目下应用的创建及配置 数据库的配置 templates模板的配置 命令行创建项目: 在需要的目录下创建Django项目输入命令:django- ...
- Appium 微信 webview 的自动化技术
Appium 微信 webview 的自动化技术 最近好多人问微信webview自动化的事情, 碰巧我也在追微信webview的自动化和性能分析方法. 先发出来一点我的进展给大家参考下. 此方法用 ...
- Mysql: [Warning] Using a password on the command line interface can be insecure
mysql: [Warning] Using a password on the command line interface can be insecure MySQL 5.6 警告信息 comma ...
- Java 基础 - public、private、protected区别
ref: https://www.cnblogs.com/pengfeiliu/p/3745934.html 类中的数据成员和成员函数据具有的访问权限包括:public.private.protect ...
- jQuery ajax - post() 方法
实例 请求 test.php 网页,忽略返回值: $.post("test.php"); TIY 实例 通过 AJAX POST 请求改变 div 元素的文本: $("i ...
- Markdown转义字符表
- mysql mac客户端: sequel,mysql-workbench
sequel: https://sequelpro.com/download#auto-start mysql-workbench:https://dev.mysql.com/downloads/fi ...
- iOS开发之SceneKit框架--实战地月系统围绕太阳旋转
1.创建地月太阳系统scn文件 注意:moon在earth结构下,earth和moon在sun结构下. 2.获取scn中模型的对应节点和自转(太阳为例) 获取节点: name是对应的Identity字 ...
- openstack实战部署
简介:Openstack系统是由几个关键服务组成,他们可以单独安装,这些服务根据你的云需求工作在一起,这些服务包括计算服务.认证服务.网络服务.镜像服务.块存储服务.对象存储服务.计量服务.编排服务和 ...
- 使用Navicat连接管理远程linux服务器上的mysql数据库
第一步:选择连接,选择mysql 第二步:填写下面弹出框的信息:连接名随便写,主机名或IP地址:写上服务器的ip. 端口不变 用户名不变. 密码:输入服务器数据库的密码12345678. 接着测 ...