schema文件及XML文件的DOM和Sax解析
schema文件
<?xml version="1.0" encoding="UTF-8"?>
<schema xmlns="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.example.org/book"
xmlns:book="http://www.example.org/book"
elementFormDefault="qualified">
<!--创建books根元素-->
<element name="books">
<complexType>
<sequence>
<element name="book" maxOccurs="unbounded" minOccurs="1">
<complexType>
<sequence>
<element name="name" type="string"/>
<element name="author" type="string" maxOccurs="2"/>
<element name="price" type="decimal"/>
<element name="date" type="date"/>
<element name="pageNumbers" type="int" minOccurs="0" maxOccurs="2"/>
</sequence>
<attribute name="id" type="ID" use="required"/>
<attribute name="name" type="string"/>
</complexType>
</element>
</sequence>
</complexType>
</element>
</schema>
<?xml version="1.0" encoding="UTF-8"?>
<books xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.example.org/book"
xmlns:book="http://www.example.org/book"
xsi:schemaLocation="http://www.example.org/book book.xsd">
<book:book id="CSN001" name="图书1">
<book:name></book:name>
<book:author>图书作者1</book:author>
<book:author>图书作者</book:author>
<book:price>66.6</book:price>
<book:date>1966-10-22</book:date>
<book:pageNumbers>1</book:pageNumbers>
</book:book>
</books>
xml解析
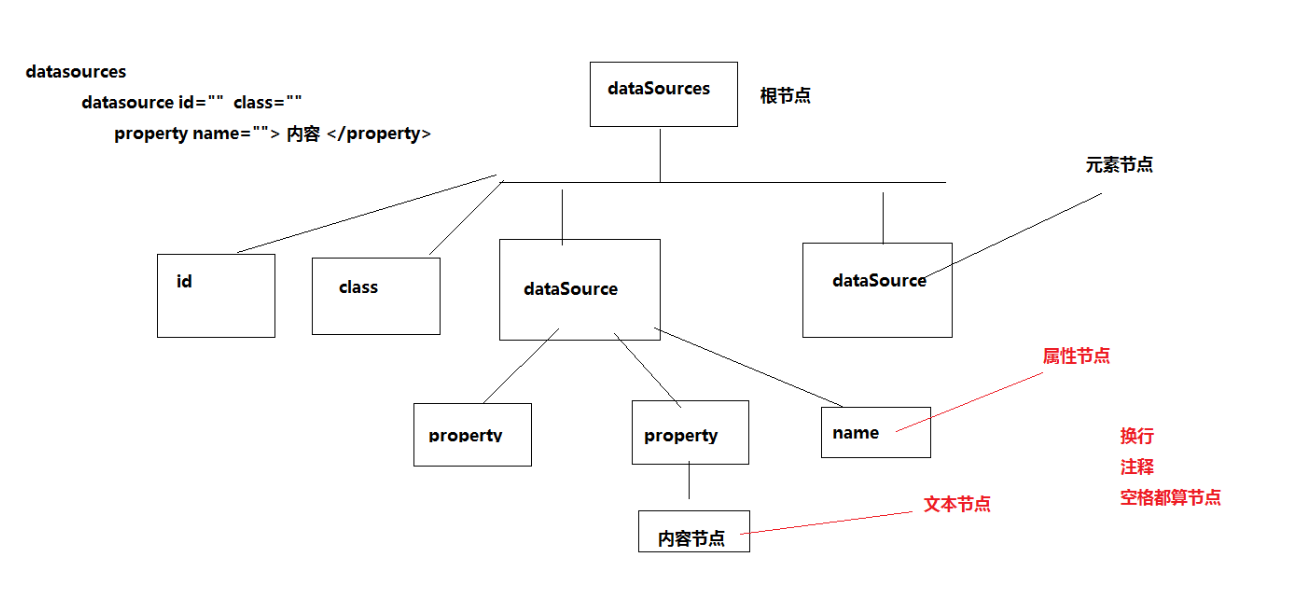
<?xml version="1.0" encoding="UTF-8"?>
<dataSources>
<!-- 定义MySQL数据源 -->
<dataSource id="mysql" class="xxx.xxx.xx">
<property name="driverClassName">com.mysql.jdbc.Driver</property>
<property name="url">jdbc:mysql://127.0.0.1:3306/userdb</property>
<property name="username">root</property>
<property name="password">123</property>
</dataSource> <!-- 定义Oracle的数据源 -->
<dataSource id="oracle" class="xxx.xxx.xx">
<property name="driverClassName">com.oracle.jdbc.OracleDriver</property>
<property name="url">jdbc:oracle:thin:@127.0.0.1:1521:ORCL</property>
<property name="username">scott</property>
<property name="password">tiger</property>
</dataSource>
</dataSources>
package com.demo.dom; import java.io.InputStream; import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory; import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList; /**
* 使用DOM解析XML文件
*
* 把XML文件转换后为流程在把流在内存中构建一个DOM模型,使用对应API操作DOM树
*
* @author Administrator
*
*/
public class DOMParser { public static void main(String[] args) {
long start = System.nanoTime();
try {
// 创建一个文档构建工厂对象
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
// 通过工厂对象创建一个文档构建对象
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
// 吧XML转换为输入流操作
InputStream inputStream = DOMParser.class.getClassLoader().getResourceAsStream("datasource.xml");
// 通过文档构建对象构建一个文档对象
Document document = documentBuilder.parse(inputStream);
// 获取文档中的根元素
Element rootElement = document.getDocumentElement();
// 获取根元素先所有dataSource子节点
NodeList nodeList = rootElement.getChildNodes(); for (int i = 0; i < nodeList.getLength(); i++) {
/**
* 3: 换行节点->文本节点 8: 注释节点 1: 元素节点
*/
Node node = nodeList.item(i);
// 判断元素节点才操作
if (Node.ELEMENT_NODE == node.getNodeType()) {
// 读取属性节点的值
String clazz = node.getAttributes().getNamedItem("class").getNodeValue();
String id = node.getAttributes().getNamedItem("id").getNodeValue();
System.out.println("class="+clazz);
System.out.println("id="+id);
// 获取元子节点
NodeList datasourceNodes = node.getChildNodes();
for (int j = 0; j < datasourceNodes.getLength(); j++) {
Node dataSourceNode = datasourceNodes.item(j); if (Node.ELEMENT_NODE == dataSourceNode.getNodeType()) {
// 获取属性的值
String nameValue = dataSourceNode.getAttributes().getNamedItem("name").getNodeValue();
String contentValue = dataSourceNode.getTextContent();
System.out.println(nameValue+"="+contentValue);
}
}
}
} } catch (Exception e) {
e.printStackTrace();
} long end = System.nanoTime();
System.out.println(end - start);
} }
package com.demo.sax; import java.io.InputStream; import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory; import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler; import com.demo.dom.DOMParser; /**
* Sax解析
*
* @author Administrator
*
*/
public class SaxParserDemo {
public static void main(String[] args) {
long start = System.nanoTime();
// 创建一个Sax工厂对象->工厂设计
SAXParserFactory factory = SAXParserFactory.newInstance();
try {
// 创建解析器
SAXParser saxParser = factory.newSAXParser();
// 吧XML转换为输入流操作
InputStream inputStream = DOMParser.class.getClassLoader().getResourceAsStream("datasource.xml");
saxParser.parse(inputStream, new DefaultHandler() {
//解析开始标题文档
public void startDocument() throws SAXException {
System.out.println("<?xml version= 1.0 encoding= utf-8 ?>");
}
//解析节点
@Override
public void startElement(String uri, String localName,
String qName, Attributes attributes) throws SAXException {
System.out.print("<"+qName+" ");
for (int i = 0; i < attributes.getLength(); i++) {
System.out.print(attributes.getQName(i)+"="+attributes.getValue(i)+" ");
}
System.out.print(">");
} @Override
//解析结束
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.print("</"+qName+">");
} @Override
//解析内容
public void characters(char[] ch, int start, int length)
throws SAXException {
String string = new String(ch, start, length);
System.out.print(string);
} });
} catch (Exception e) {
e.printStackTrace();
}
long end = System.nanoTime();
System.out.println(end - start);
} /**
* 定义默认处理的内部类
* @author Administrator
*
*/
private static class XMLHanlder extends DefaultHandler { @Override
public void startDocument() throws SAXException {
System.out.println("解析开始");
} @Override
public void startElement(String uri, String localName, String qName, Attributes attributes)
throws SAXException {
System.out.println("开始解析元素"+qName);
System.out.println(attributes.getValue("id"));
System.out.println(attributes.getValue("class"));
} @Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("解析结束");
} @Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.println("解析内容");
System.out.println(new String(ch,start, length));
} }
}
schema文件及XML文件的DOM和Sax解析的更多相关文章
- XML - 十分钟了解XML结构以及DOM和SAX解析方式
引言 NOKIA 有句著名的广告语:"科技以人为本".不论什么技术都是为了满足人的生产生活须要而产生的.详细到小小的一个手机.里面蕴含的技术也是浩如烟海.是几千年来人类科技的结晶, ...
- JavaEE实战——XML文档DOM、SAX、STAX解析方式详解
原 JavaEE实战--XML文档DOM.SAX.STAX解析方式详解 2016年06月22日 23:10:35 李春春_ 阅读数:3445 标签: DOMSAXSTAXJAXPXML Pull 更多 ...
- LINQ to XML 从逗号分隔值 (CSV) 文件生成 XML 文件
参考:http://msdn.microsoft.com/zh-cn/library/bb387090.aspx 本示例演示如何使用 语言集成查询 (LINQ) 和 LINQ to XML 从逗号分隔 ...
- web端自动化——Python读取txt文件、csv文件、xml文件
1.读取txt文件 txt文件是我们经常操作的文件类型,Python提供了以下几种读取txt文件的方式. 1)read(): 读取整个文件. 2)readline(): 读取一行数据. 3)readl ...
- 关于跨域策略文件crossdomain.xml文件
下载flexpaper源码修改后做成swf阅读器,要加入待阅读的swf文件,可以在flex里调用js的方法来获取swf文件的路径的方法,在js只专注获取路径就行,等着flex来调用:但这里会遇到一个问 ...
- iOS开发中XML的DOM和SAX解析方法
一.介绍 dom是w3c指定的一套规范标准,核心是按树形结构处理数据,dom解析器读入xml文件并在内存中建立一个结构一模一样的“树”,这树各节点和xml各标记对应,通过操纵此“树”来处理xml中的文 ...
- Java SE之XML<二>XML DOM与SAX解析
[文档整理系列] Java SE之XML<二>XML DOM与SAX解析 XML编程:CRUD(Create Read Update Delete) XML解析的两种常见方式: DOM(D ...
- java基础71 XML解析中的【DOM和SAX解析工具】相关知识点(网页知识)
本文知识点(目录):本文下面的“实例及附录”全是DOM解析的相关内容 1.xml解析的含义 2.XML的解析方式 3.xml的解析工具 4.XML的解析原理 5.实例 6 ...
- Java文件操作①——XML文件的读取
一.邂逅XML 文件种类是丰富多彩的,XML作为众多文件类型的一种,经常被用于数据存储和传输.所以XML在现今应用程序中是非常流行的.本文主要讲Java解析和生成XML.用于不同平台.不同设备间的数据 ...
随机推荐
- 请问具体到PHP的代码层面,改善高并发的措施有哪些
1.今天被问一个问题:请问具体到PHP的代码层面,改善高并发的措施有哪些? 面对高并发问题我首先想到的是集群.缓存(apt.redis.mem.内存...),但具体到PHP代码层面除了想到队列.减少网 ...
- C++中static和const关键字的作用
static关键字至少有下列几个作用: 函数体内static变量的作用范围为该函数体,不同于auto变量,该变量的内存只被分配一次,因此其值在下次调用时仍维持上次的值: 在模块内的static全局变量 ...
- C++面向对象的设计思想——小结
1 对象的概念 面向对象(Object Oriented Analysis Design,OOAD)的思想把整个世界看成是由具有某种特征行为功能的基本单元——对象构成的.OOAD把一个对象的特征称为属 ...
- CorelDRAW X6+PhotoZoom这组合,无敌了啊!
520就这样毫无察觉的过去了,对于额这种单身狗,额表示,什么520,什么情人节,统统略过,,可是,可是,即便这样,还是硬生生的吃了一把来势凶猛的远在天际的狗粮,当我看到CorelDRAW X6和Pho ...
- nginx上搭建https
nginx上配置https的条件: 1.SSL证书和服务器私钥文件 2.nginx支持SSL模块 一.获取SSL证书 网上有提供权威认证的SSL证书的网站,但多数是收费的,而且不便宜.在正式的生产环境 ...
- Iterator与Asyc/Await的实现
https://wanago.io/2018/04/23/demystifying-generators-implementing-async-await/
- [中文] 以太坊(Ethereum )白皮书
以太坊(Ethereum ):下一代智能合约和去中心化应用平台 翻译|巨蟹 .少平 译者注|中文读者可以到以太坊爱好者社区(www.ethfans.org)获取最新的以太坊信息. 当中本聪在2009年 ...
- sudo日志审计
一般企业生产环境都会用跳板机把操作日志记录下来,不过有些公司内部的测试机可以用本机的sudo日志审计功能将执行的sudo命令保存日志. 为什么要使用sudo审计,因为可以通过sudo授权给普通用户执行 ...
- 数组实例的 entries(),keys() 和 values()
数组实例的 entries(),keys() 和 values() entries(),keys()和values(),用于遍历数组.它们都返回一个遍历器对象,可以用for...of循环进行遍历,唯一 ...
- js实现点击复制网页内容(基于clipboard.js)
浏览网页过程中会遇到点击复制链接地址的情况,下面就介绍一种实现方法,该方法是基于clipboard.js: 官网地址:https://clipboardjs.com/: clipboard.js使用比 ...