Linux分布式测试
在使用Jmeter进行性能测试时,如果并发数比较大(比如最近项目需要支持1000并发),单台电脑的配置(CPU和内存)可能无法支持,这时可以使用Jmeter提供的分布式测试的功能。
执行机和调度机做好在同一个路径 比如jmeter的bin目录下
一、Jmeter分布式执行原理:
1、Jmeter分布式测试时,选择其中一台作为调度机(master),其它机器做为执行机(slave)。
2、执行时,master会把脚本发送到每台slave上,slave 拿到脚本后就开始执行,slave执行时不需要启动GUI,我理解它应该是通过命令行模式执行的。
3、执行完成后,slave会把结果回传给master,master会收集所有slave的信息并汇总。
二、执行机(slave)配置:
1、slave机上需要安装Jmeter,具体如何安装这里不详细介绍了。
2、添加环境变量:JMETER_HOME=D:\B_TOOLS\apache-jmeter-2.13,此处为你Jmeter的路径
3、启动bin目录下的:jmeter-server.bat,启动成功如下图:
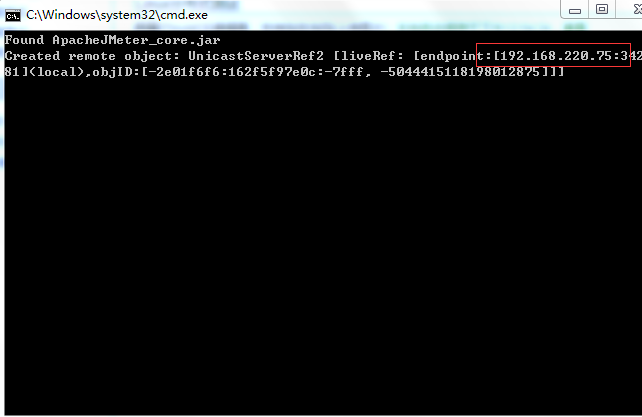
4、上图上标红的IP和端口会在master里配置时用到。IP就是slave机器IP,端口默认是1099,端口也可以自定义,这里我自定义为1000,这个后面会讲。
5、多台slave的话,重复1~4步骤就好。
在Linux执行jmeter-server报错了

解决方法如下:

[root@localhost bin]# ./jmeter-server -Djava.rmi.server.hostname=192.168.220.57 192.168.220.57是你Linux本机的虚拟ip
报错如下:
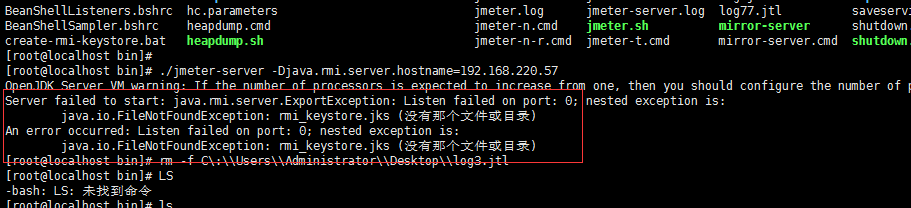
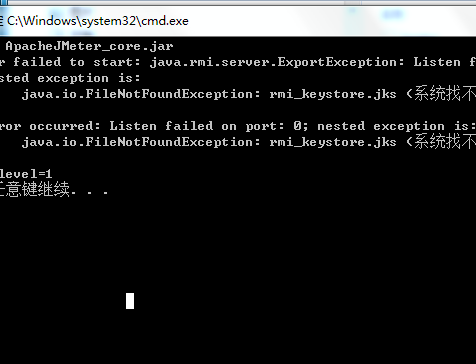
解决如下:
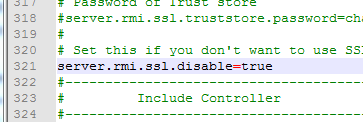
在windows下的jmeter.properties文件改成true 注意#注释符号去掉 Linux的也是一样 vi jmeter.properties 注意#注释符号去掉 !!!! : wq保存
也有人可以这样改
点击批处理文件
${PIBW]AM_BEL.png)
报错如下,解决如下 报错是右面图,不是左边 表示端口被占用了
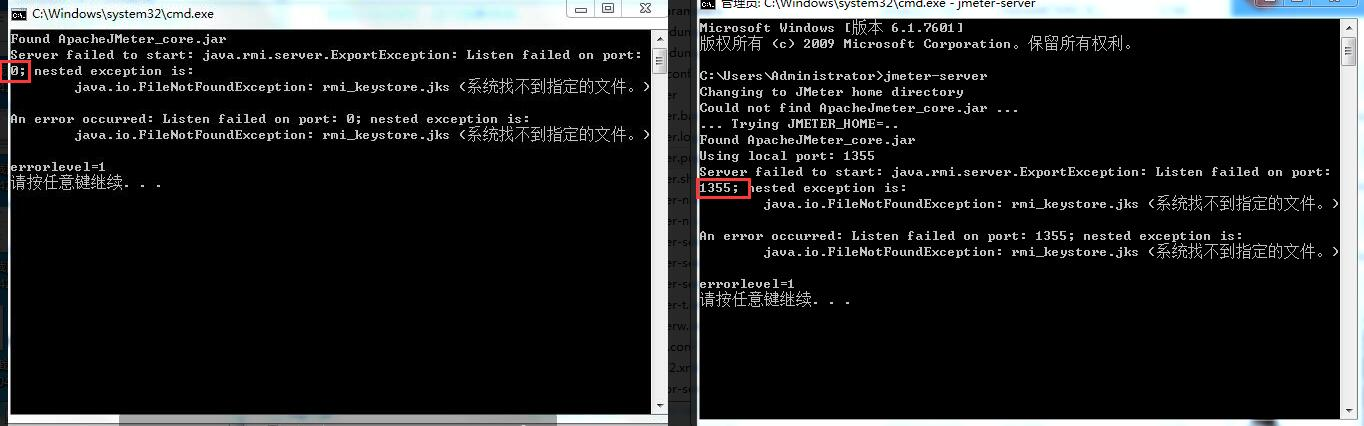
解决如下:
jmeter.properties查找改下没有占用的端口
报错如下

解决如下
关闭你服务器防火墙
service iptables stop
service firewalld stop

解决如下
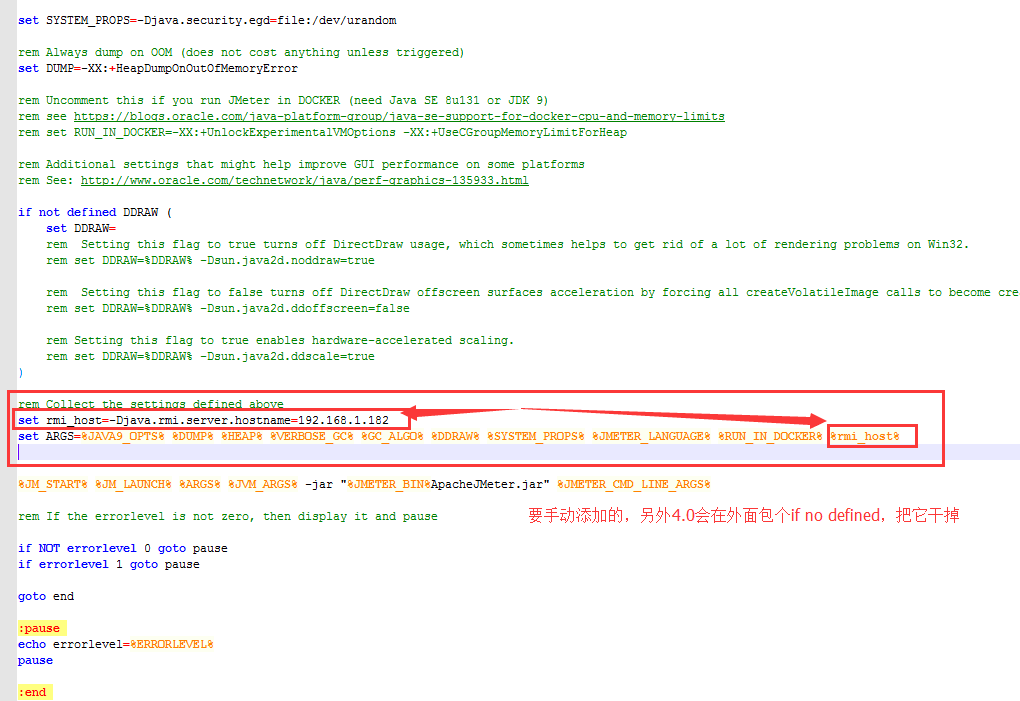
在调度机指定自已的IP
三、调度机(master)配置:
2、找到Jmeter的bin目录下jmeter.properties文件,修改如下配置,IP和Port是slave机的IP以及自定义的端口
remote_hosts=10.13.223.202:1099,10.13.225.12:1099
多台slave之前用","隔开,我这配置了2台,可以看到标红的这个就是上面截图slave的IP和Port.
四、自定义端口:
上面其实已经实现了Jmeter的分布式测试,这部分主要介绍下如何自定义slave端口:
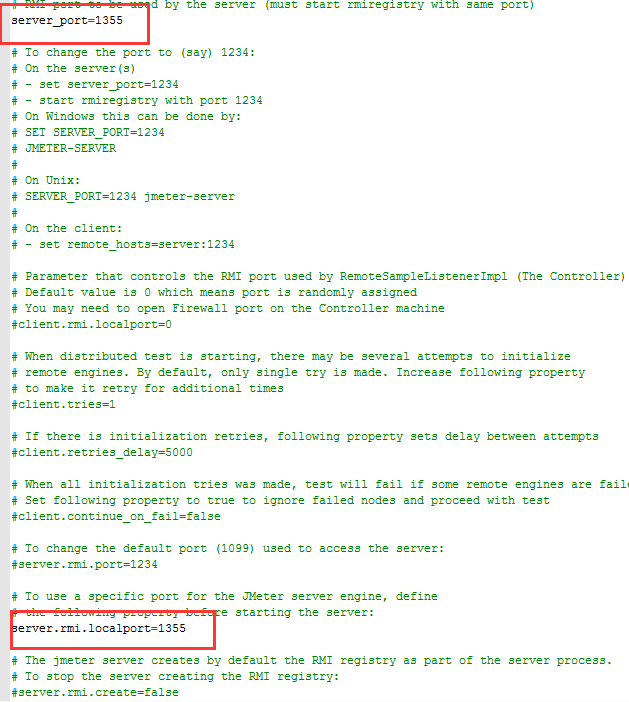
1、slave:在slave机的Jmeter的bin目录下,找到jmeter.properties文件,修改如下两个配置项,比如我这里修改为1888:
server_port=1888
server.rmi.localport=1888
2、启动slave机上的jmeter-server.bat,如下图,端口已经修改为:1888
3、master:修改master机器的jmeter.properties文件:
remote_hosts=10.13.223.202:1000,10.13.225.12:1888
五、其它说明:
1、调度机(master)和执行机(slave)最好分开,由于master需要发送信息给slave并且会接收slave回传回来的测试数据,所以mater自身会有消耗,所以建议单独用一台机器作为mater。
2、参数文件:如果使用csv进行参数化,那么需要把参数文件在每台slave上拷一份且路径需要设置成一样的。
3、每台机器上安装的Jmeter版本和插件最好都一致,否则会出一些意外的问题。
Linux分布式测试的更多相关文章
- 转:Jmeter以non-gui模式进行分布式测试
由于Jmeter是一个纯JAVA的应用,用GUI模式运行压力测试时,对客户端的资源消耗是相当惊人的,所以在进行正式的压测时一定要使用non-gui模式运行,如果并发数很高或者客户端的硬件资源比较一般的 ...
- selenium结合docker构建分布式测试环境
selenium是目前web和app自动化测试的主要框架.对于web自动化测试而言,由于selenium2.0以后socker服务器由本地浏览器自己启动且直接通过浏览器原生API操作页面,故越来越多的 ...
- Jmeter之分布式测试
1)Jmeter 是纯java 应用,对于CPU和内存的消耗比较大,并且受到JVM的一些限制: 一般情况下,依据机器配置,单机的发压量为300-600,因此,当需要模拟数以千计的并发用户时,使用单台机 ...
- jmeter分布式测试的坑
转 : jmeter分布式测试的坑 有关jmeter分布式测试的环境配置,大概就是那样,但是每次想要进行jmeter分布式测试的时候,总是会有各种奇怪的问题,下面整理了一些可能遇到的坑. 只要错误中出 ...
- 转 : jmeter分布式测试的坑
有关jmeter分布式测试的环境配置,大概就是那样,但是每次想要进行jmeter分布式测试的时候,总是会有各种奇怪的问题,下面整理了一些可能遇到的坑. 只要错误中出现:Error in rconfig ...
- selenium 结合 docker 构建分布式测试环境 (初学者视角)
前言:随着自动化测试越学越深,深深觉得有太多的东西需要总结. 1.记录下学习中遇到的坑,当做学习笔记.2.有前人路过看到文章中比较落后的做法,请务必一定要指教.(因为是初学者视角,很多东西只是走通而已 ...
- jmeter分布式测试的坑(转)
本文转自:https://www.cnblogs.com/lsjdddddd/p/5806077.html 有关jmeter分布式测试的环境配置,大概就是那样,但是每次想要进行jmeter分布式测试的 ...
- selenium===使用docker搭建selenium分布式测试环境
准备: #请在此之前先了解,selenium grid :参考:selenium-grid ,下载地址,win-本地部署过程 >>>环境准备: Linux操作系统 >>& ...
- Jmeter分布式测试笔记
在性能测试过程中,如果要求并发数较大时(例如1000+),单机配置cpu与内存等无法支持,则需要使用Jmeter的分布式测试方法. 一.一般什么情况下需要分布式 1.前辈经验:比如机器i5双核的cpu ...
随机推荐
- HDU 2415 Bribing FIPA
Bribing FIPA Time Limit: 1000ms Memory Limit: 32768KB This problem will be judged on HDU. Original I ...
- HDU - 2833 - WuKong
先上题目: WuKong Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tota ...
- 0726xtrbackup实例详解
转自http://www.cnblogs.com/olinux/p/5207887.html MySQL中的xtrabackup的原理解析 xtrabackup的官方下载地址为 http://www. ...
- 做acm 需要学的算法
做acm 需要学的算法 转一个搞ACM需要的掌握的算法. 要注意,ACM的竞赛性强,因此自己应该和自己的实际应用联系起来. 适合自己的才是好的,有的人不适合搞算法,喜欢系统架构,因此不要看到别人什 ...
- MySQL必知必会面试题 基础
1.登录数据库 (1).单实例 mysql -uroot -poldboy (2).多实例 mysql -uroot -poldboy -S /data/3306/mysql.sock 2.查看数据库 ...
- Arcengine设置坐标系
转自原文 Arcengine设置坐标系 ArcGIS Engine提供了一系列对象供开发者管理GIS系统的坐标系统. 对大部分开发者而言了解ProjectedCoordinateSystem, Geo ...
- 第一个关于selenium项目
1.创建一个简单的Python工程 在主菜单中,选择File | New Project ,并指定Python解释器版本 2.创建python类,快捷键alt+insert 3.编写打开浏览器的代码, ...
- Linux 查看负载
top iostat -x 1 10 free uptime cat /proc/cpuinfo cat /proc/meminfo src lsof 1,查看磁盘 df -h 2,查看内存大小 f ...
- ios weak和strong的差别
The difference is that an object will be deallocated as soon as there are no strong pointers to it. ...
- Visual C++ RunTime的特征——非烫即屯
Visual C++ RunTime的特征——非烫即屯 大一刚学C语言,第二次上机课,当我发现我照着书抄写的程序在运行之外的黑框里面跳出一排“烫烫烫烫烫”,当时就震惊了.你们能想象一个来自小城,在大学 ...