机器学习实战笔记--AdaBoost(实例代码)
#coding=utf-8
from numpy import * def loadSimpleData():
dataMat = matrix([[1. , 2.1],
[2. , 1.1],
[1.3 , 1.],
[1. , 1.],
[2. , 1.]])
classLabels = [1.0,1.0,-1.0,-1.0,1.0]
return dataMat, classLabels #训练出单个弱分类器,输出预测值
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
#初始化预测结果为array数组,样本数行,1列,值为1
retArry = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
#dataMatrix[:,dimen]表示为某一特征列的所有行,即存为列向量
retArry[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArry[dataMatrix[:,dimen] > threshVal] = -1.0
return retArry #D是权重向量,此函数功能是训练出最佳的单个的弱分类器,决策桩。返回最佳的弱分类器详情参数(第几维决策桩,阀值,不等于号,错误率,预测结果)
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr)
labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0#在特征所有可能值上遍历
bestStump = {}#用于存储单层决策树的信息
bestClasEst = mat(zeros((m,1)))
minError = inf
for i in range(n):#遍历所有特征
rangeMin = dataMatrix[:,i].min()
rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax - rangeMin) / numSteps
for j in range(-1,int(numSteps)+1):
for inequal in ['lt','gt']:
threshVal = (rangeMin + float(j) * stepSize)#得到阀值
#根据阀值分类,弱分类器结果预测分类结果放入predictedVals
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T * errArr#不同样本的权重是不一样的
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
#bestClasEst为最佳分类结果
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst #此函数控制迭代次数为默认40次(函数中计算总分类器错误率为0时break),训练总分类器weakClassArr,列表里存放元素为每个弱分类器(阀值,不等于号,第几维)
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m =shape(dataArr)[0]
D = mat(ones((m,1))/m)#初始化所有样本的权值一样
aggClassEst = mat(zeros((m,1)))#每个数据点的估计值
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
#计算alpha,max(error,1e-16)保证没有错误的时候不出现除零溢出
#alpha表示的是这个分类器的权重,错误率越低分类器权重越高
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))
bestStump['alpha'] = alpha
weakClassArr.append(bestStump)
#classEst 存放弱分类器 预测出的最佳分类结果,为array数组形式,列向量。
#classLabels存放的是 实际的分类结果(列表形式),mat强制转换为矩阵后再转置为列向量。
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#calc training error of all classifiers, if this is 0 quit for loop early (use break)
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
'''
>>> ones((2,1))!=mat([[-1],[1]])
matrix([[ True],
[False]], dtype=bool)
>>> multiply(ones((2,1))!=mat([[-1],[1]]),ones((2,1)))
matrix([[ 1.],
[ 0.]])
'''
#sign(aggClassEst) != mat(classLabels).T 存放:总分类器的预测结果和实际分类结果作比较后的bool值,预测对为True,预测错为False。
#必须与对应元素相一致的array数组相乘得到矩阵形式的列向量,值为0,1
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error: ",errorRate
if errorRate == 0.0:
break
return weakClassArr #dataToClass 表示要分类的点或点集,预测点或点集的分类结果 def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#do stuff similar to last aggClassEst in adaBoostTrainDS
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
#总分类器中的每个弱分类器是已知的最佳弱分类器,参数都已定好。直接调用stumpClassify函数进行分类,并输出预测结果classEst
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#call stump classify
#利用预测结果以及弱分类器的alpha值,算出单个的结果,然后循环算出总分类器f(x)值
aggClassEst += classifierArr[i]['alpha']*classEst
print aggClassEst
#取结果值得符号
return sign(aggClassEst) def main():
#加载数据,赋初始值样本权重为相等的 1/样本数
dataMat,classLabels = loadSimpleData()
D = mat(ones((5,1))/5)
#classifierArr存放:总分类器,元素为弱分类器的详细情况
classifierArr = adaBoostTrainDS(dataMat,classLabels,30)
t = adaClassify([0,0],classifierArr)
print t if __name__ == '__main__':
main()
AdaBoost实例
AdaBoost算法是以PAC理论为基础,实现了它的理想。PAC理论证明了强可学习与弱可学习的等价。AdaBoost算法将弱学习算法提升为强学习算法。是提升算法boosting的代表作。
简述:
它以弱分类器作为基分类器,对训练样本集进行T轮训练,每次训练选择错误率较低的弱分类器,计算错误率。
依据错误率计算弱分类器在最终总分类器中的投票权重
结合投票权重和样本是否预测正确来改变样本分布,也就是更新样本的权重,预测正确的样本权重降低,预测错误的样本权重增加。使得下一轮的训练着重放在那些预测错误的样本上。实现每轮训练的分类器好而不同,增加多样性。
最后将分类器添加到最终总分类器集中组合成为一个强分类器。最终的分类函数使用一种有权重的投票方式,权重较大的基分类器对结果的影响较大。
算法流程:
(1)设定N组训练样本,S=((x1,y1),(x2,y2),...(xN,yN)),其中xi为输入向量且xi∈X,yi∈Y={-1,1};
(2)初始化:样本初始权值
W1(i)=1/N, i=1,2,...N;
(3)进行T次迭代,t=1 to T
1)使用具有权值分布Wt的训练样本,由基于权重的弱分类器进行学习,得到基分类器ht:X→{-1,1};
2)计算ht的错误率
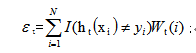
其中,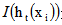 是一个指示函数,其值如下:
是一个指示函数,其值如下:
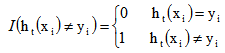
3)计算基分类器在总分类器集中的投票权值

4)更新权重(改变样本分布)
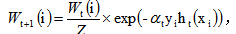 i=1,2,...N;
i=1,2,...N;
这里,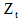 是规范化因子
是规范化因子
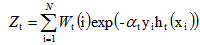
它使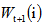 ,i=1,2,...N;成为概率分布。
,i=1,2,...N;成为概率分布。
(4)T次迭代结束,得到集成分类器:

机器学习实战笔记--AdaBoost(实例代码)的更多相关文章
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
- Python 1行代码实现文本分类(实战笔记),含代码详细说明及运行结果
Python 1行代码实现文本分类(实战笔记),含代码详细说明及运行结果 一.详细说明及代码 tc.py =============================================== ...
- 机器学习实战笔记7(Adaboost)
1:简单概念描写叙述 Adaboost是一种弱学习算法到强学习算法,这里的弱和强学习算法,指的当然都是分类器,首先我们须要简介几个概念. 1:弱学习器:在二分情况下弱分类器的错误率会低于50%. 事实 ...
- 机器学习实战笔记(Python实现)-06-AdaBoost
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-00-readme
近期学习机器学习,找到一本不错的教材<机器学习实战>.特此做这份学习笔记,以供日后翻阅. 机器学习算法分为有监督学习和无监督学习.这本书前两部分介绍的是有监督学习,第三部分介绍的是无监督学 ...
- 机器学习实战笔记(Python实现)-08-线性回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-05-支持向量机(SVM)
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-04-Logistic回归
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
- 机器学习实战笔记(Python实现)-03-朴素贝叶斯
--------------------------------------------------------------------------------------- 本系列文章为<机器 ...
随机推荐
- POJ 1061 青蛙的约会( 拓欧经典题 )
链接:传送门 思路:简单拓展欧几里德,分析后可以得到方程 x + m * t = y + n * t + L * s( s控制圈数,t代表跳t次会碰面 ),经过化简可以得到 ( n - m ) * t ...
- 会话cookie和持久化cookie实现session
当你第一次访问一个网站的时候,网站服务器会在响应头内加上Set- Cookie:PHPSESSID=nj1tvkclp3jh83olcn3191sjq3(php服务器),或Set-Cookie JSE ...
- 使用Ansible安装部署nginx+php+mysql之安装nginx(1)
使用Ansible安装nginx 1.nginx.yaml文件 --- - hosts: clong remote_user: root gather_facts: no tasks: # 安装epe ...
- Linux 基础入门一
操作系统1.简介OS: Operating System,通用目的的软件程序操作系统的内核(kernel): 操作系统其实也是一组程序.这组程序的重点在于管理计算机的所有活动及驱动系统中的所有硬件: ...
- 常用前端布局,CSS技巧介绍
常用前端布局,CSS技巧介绍 对前端常用布局的整理总结,并对其性能优劣,兼容等情况进行介绍 css常用技巧之可变大小正方形的绘制 1:若通过设置width为百分比的方式,则高度不能通过百分比来控制. ...
- j2ee消息中间件
http://blog.csdn.net/apanious/article/details/51014396
- 《代码敲不队》第八次团队作业:Alpha冲刺 第四天
项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 代码敲不队 作业学习目标 掌握软件编码实现的工程要求. 团队项目github仓库地址链接 GitH ...
- TOMCAT-IDEA远程debug方法
在很多情况下,tomcat本地启动并不足以完全模拟线上环境,所以,有时候我们可能需要远程debug方法去调试,下面附上远程idea debug方法: IDEA中,选择 Run/Debug Config ...
- centos 如何执行.bin 文件??
默认下载,或者上传到 linux 上的 .bin 文件都是白色的,不能被执行. 想要用 ./ 命令去执行,需要先给这个 bin 文件赋权限 chmod u+x 文件名(全名称) 执行完成这个命令,可以 ...
- LaTeX 加粗
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50997822 LaTeX中文本加粗的方 ...