scrapy爬虫框架实例二
本实例主要通过抓取慕课网的课程信息来展示scrapy框架抓取数据的过程。
1、抓取网站情况介绍
抓取网站:http://www.imooc.com/course/list
抓取内容:要抓取的内容是全部的课程名称,课程简介,课程URL ,课程图片URL,课程人数(由于动态渲染暂时没有获取到)
网站图片:
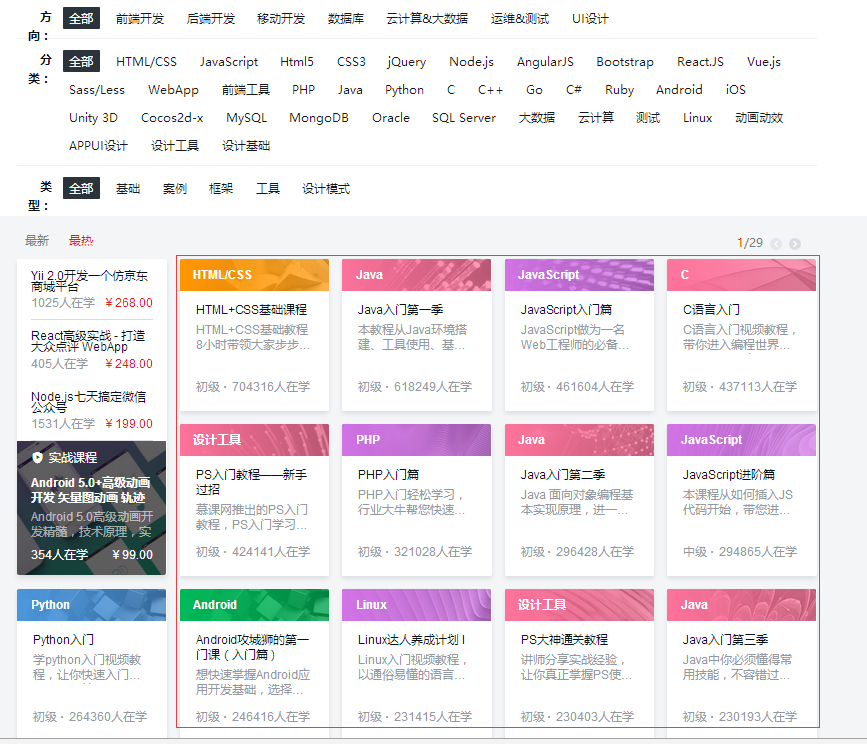
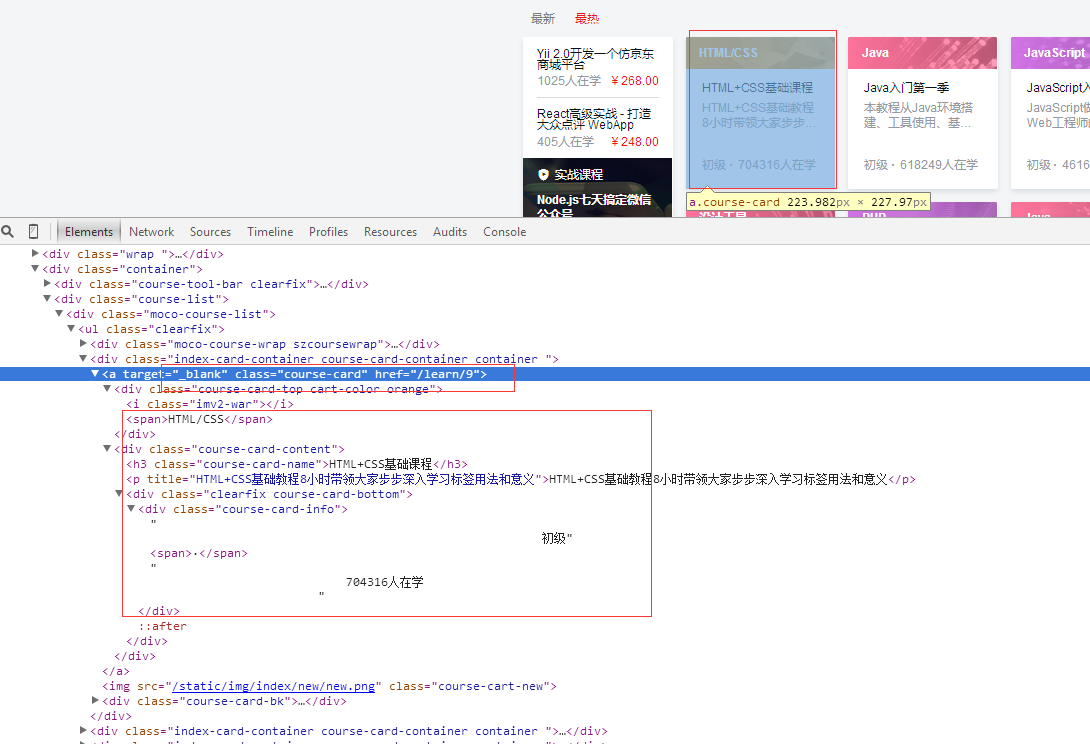

2、建立工程
在命令行模式建立工程
scrapy startproject scrapy_course
建立完成后,用pycharm打开,目录如下:
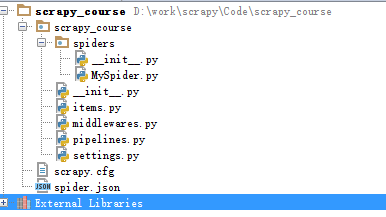
scrapy.cfg: 项目的配置文件
scrapytest/: 该项目的python模块。之后您将在此加入代码。
scrapytest/items.py: 项目中的item文件.
scrapytest/pipelines.py: 项目中的pipelines文件.
scrapytest/settings.py: 项目的设置文件.
scrapytest/spiders/: 放置spider代码的目录.
3、创建一个爬虫
下面按步骤讲解如何编写一个简单的爬虫。
我们要编写爬虫,首先是创建一个Spider
我们在scrapy_course/spiders/目录下创建一个文件MySpider.py
文件包含一个MySpider类,它必须继承scrapy.Spider类。
同时它必须定义一下三个属性:
-name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。
-start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。
-parse() 是spider的一个方法。 被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。
创建完成后MySpider.py的代码如下

定义爬虫项目
创建完了Spider文件,先不急着编写爬取代码
我们先定义一个容器保存要爬取的数据。
这样我们就用到了Item
为了定义常用的输出数据,Scrapy提供了Item类。Item对象是种简单的容器,保存了爬取到得数据。 其提供了 类似于词典(dictionary-like)的API以及用于声明可用字段的简单语法。
我们在工程目录下可以看到一个items文件,我们可以更改这个文件或者创建一个新的文件来定义我们的item。
这里,我们在同一层创建一个新的item文件CourseItems.py
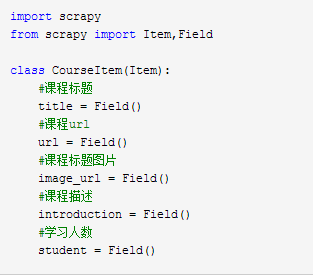
根据如上的代码,我们创建了一个名为courseItem的容器,用来保存、抓取的信息,
title->课程标题, url->课程url, image_url->课程标题图片, introduction->课程描述, student->学习人数
在创建完item文件后我们可以通过类似于词典(dictionary-like)的API以及用于声明可用字段的简单语法。
常用方法如下

4、编写Spider代码
定义了item后我们就能进行爬取部分的工作了。
为了简单清晰,我们先抓取一个页面中的信息。
首先我们编写爬取代码
我们在上文说过,爬取的部分在MySpider类的parse()方法中进行。
parse()方法负责处理response并返回处理的数据以及(/或)跟进的URL。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象。
我们在之前创建的MySpider.py中编写如下代码。
注意和上边MySpider.py的区别
# -*- coding:utf8-*-
import scrapy
import sys
import time
reload(sys)
sys.setdefaultencoding('utf-8')
from scrapy_course.items import CourseItem
from scrapy.selector import Selector
sys.stdout = open('output.txt', 'w')
pageIndex = 0 class MySpider(scrapy.Spider): #用于区别Spider
name = "MySpider"
#允许访问的域
allowed_domains = ['imooc.com']
#爬取的地址
start_urls = ["http://www.imooc.com/course/list"]
#爬取方法
def parse(self, response): # 实例一个容器保存爬取的信息
item = CourseItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
# 先获取每个课程的div
sel = Selector(response)
title = sel.xpath('/html/head/title/text()').extract() # 标题
print title[0]
# sels = sel.xpath('//div[@class="course-card-content"]')
sels = sel.xpath('//a[@class="course-card"]')
pictures = sel.xpath('//div[@class="course-card-bk"]')
index = 0
global pageIndex
pageIndex += 1
print u'%s' % (time.strftime('%Y-%m-%d %H-%M-%S'))
print '第' + str(pageIndex)+ '页 '
print '----------------------------------------------'
for box in sels:
print ' '
# 获取div中的课程标题
item['title'] = box.xpath('.//h3[@class="course-card-name"]/text()').extract()[0].strip()
print '标题:' + item['title'] # 获取div中的课程简介
item['introduction'] = box.xpath('.//p/text()').extract()[0].strip()
print '简介:' + item['introduction'] # 获取每个div中的课程路径
item['url'] = 'http://www.imooc.com' + box.xpath('.//@href').extract()[0]
print '路径:' +item['url'] # 获取div中的学生人数
item['student'] = box.xpath('.//div[@class="course-card-info"]/text()').extract()[0].strip()
print item['student'] # 获取div中的标题图片地址
item['image_url'] = pictures[index].xpath('.//img/@src').extract()[0]
print '图片地址:' + item['image_url']
index += 1
yield item time.sleep(1)
print u'%s' % (time.strftime('%Y-%m-%d %H-%M-%S'))
# next =u'下一页'
# url = response.xpath("//a[contains(text(),'" + next + "')]/@href").extract()
# if url:
# # 将信息组合成下一页的url
# page = 'http://www.imooc.com' + url[0]
# # 返回url
# yield scrapy.Request(page, callback=self.parse)
使用Pipeline处理数据
当我们成功获取信息后,要进行信息的验证、储存等工作,这里以储存为例。
当Item在Spider中被收集之后,它将会被传递到Pipeline,一些组件会按照一定的顺序执行对Item的处理。
Pipeline经常进行一下一些操作:
清理HTML数据
验证爬取的数据(检查item包含某些字段)
查重(并丢弃)
目前暂时将爬取结果保存到文本中
这里只进行简单的将数据储存在json文件的操作。
pipelines.py代码如下
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json class ScrapyCoursePipeline(object):
def __init__(self):
# self.file = open('data.json', 'wb')
# self.file = codecs.open(
# 'spider.txt', 'w', encoding='utf-8')
self.file = codecs.open(
'spider.json', 'w', encoding='utf-8') def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item def spider_closed(self, spider):
self.file.close()
要使用Pipeline,首先要注册Pipeline
找到settings.py文件,这个文件时爬虫的配置文件
在其中添加
ITEM_PIPELINES = {
'scrapy_course.pipelines.ScrapyCoursePipeline':300
}
上面的代码用于注册Pipeline,其中scrapy_course.pipelines.ScrapyCoursePipeline为你要注册的类,右侧的’300’为该Pipeline的优先级,范围1~1000,越小越先执行。
进行完以上操作,我们的一个最基本的爬取操作就完成了
这时我们再运行
5、运行
在命令行下运行scrapy crawl MySpider
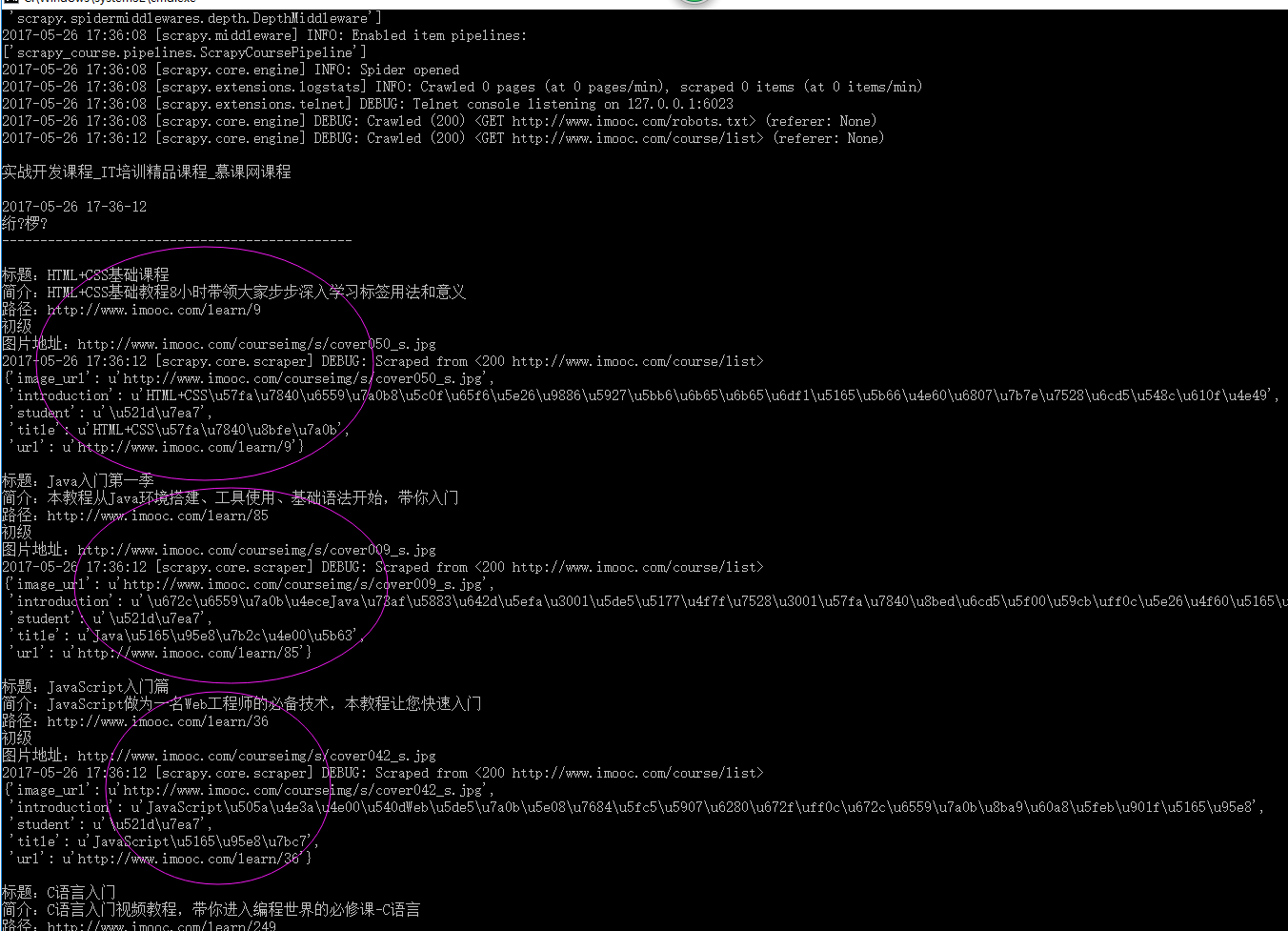
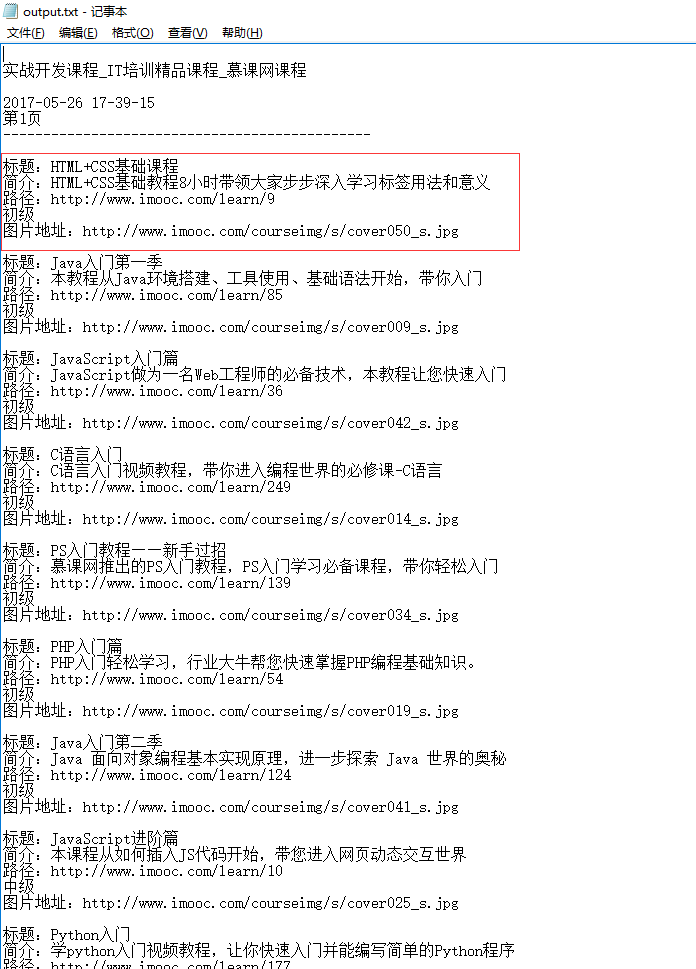
如何要把数据存储到文本文件中,在代码前面增加以后代码,
sys.stdout = open('output.txt', 'w'),这样就会把数据保存到当前项目路径下的output.txt文件里面
如下:
scrapy爬虫框架实例二的更多相关文章
- Python Scrapy 爬虫框架实例(一)
之前有介绍 scrapy 的相关知识,但是没有介绍相关实例,在这里做个小例,供大家参考学习. 注:后续不强调python 版本,默认即为python3.x. 爬取目标 这里简单找一个图片网站,获取图片 ...
- scrapy爬虫框架实例一,爬取自己博客
本篇就是利用scrapy框架来抓取本人的博客,博客地址:http://www.cnblogs.com/shaosks scrapy框架是个比较简单易用基于python的爬虫框架,相关文档:http:/ ...
- Python Scrapy 爬虫框架实例
之前有介绍 scrapy 的相关知识,但是没有介绍相关实例,在这里做个小例,供大家参考学习. 注:后续不强调python 版本,默认即为python3.x. 爬取目标 这里简单找一个图片网站,获取图片 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
随机推荐
- 机器学习方法(八):随机采样方法整理(MCMC、Gibbs Sampling等)
转载请注明出处:Bin的专栏,http://blog.csdn.net/xbinworld 本文是对参考资料中多篇关于sampling的内容进行总结+搬运,方便以后自己翻阅.其实参考资料中的资料写的比 ...
- python语言的模块化
在实际工程中使用的编程语言,都有(也应该有)自己的模块化方式,这是由于:一个文件不可能写的无限长,把不同性质和功能的代码放入不同的文件,再由文件组成不同的文件夹,这种方式符合人们思考和理解的习惯,不过 ...
- jmeter+Jenkins 持续集成中发送邮件报错:MessagingException message: Exception reading response
已经配置好了发送邮件的相关信息,但是执行完脚本出现报错:MessagingException message: Exception reading response 1.查看Jenkins本次构建的控 ...
- Java8之Stream/Map
本篇用代码示例结合JDk源码讲了Java8引入的工具接口Stream以及新Map接口提供的常用默认方法. 参考:http://winterbe.com/posts/2014/03/16/java ...
- pillow实例 | 生成随机验证码
1 PIL(Python Image Library) PIL是Python进行基本图片处理的package,囊括了诸如图片的剪裁.缩放.写入文字等功能.现在,我便以生成随机验证码为例,讲述PIL的基 ...
- Chrome浏览器你可以选择知道的知识
Chrome浏览器我想是每一个前端er必用工具之一吧,一部分原因是它速度快,体积不大,支持的新特性也比其它浏览器多,还有一部分我想就是因为它的控制台功能强大了吧,说它是神器一点也不过分,很方便.但其实 ...
- iwebshop 自动给css js链接加版本信息
lib/core/tag_class.php case 'theme:': $path = $matches[4]; $exts = strtolower(substr($matches[4], st ...
- 转:Apache+Fastcgi+Django
07年作者就贴出的文章了,可见多么古老的运行方式还在用. 转:http://www.cnblogs.com/RChen/archive/2007/03/23/django_fcgi.html 首先要安 ...
- PAT L3-005. 垃圾箱分布
最短路. 枚举垃圾箱放哪里,然后算最短路. #include<map> #include<set> #include<ctime> #include<cmat ...
- Linux的重定向与管道
(1).输出重定向 定义:将命令的标准输出结果保存到指定的文件中,而不是直接显示在显示器上. 输出重定向使用>和>>操作符. 语法:cmd > filename,表示将标准输出 ...