爬虫初体验:Python+Requests+BeautifulSoup抓取广播剧

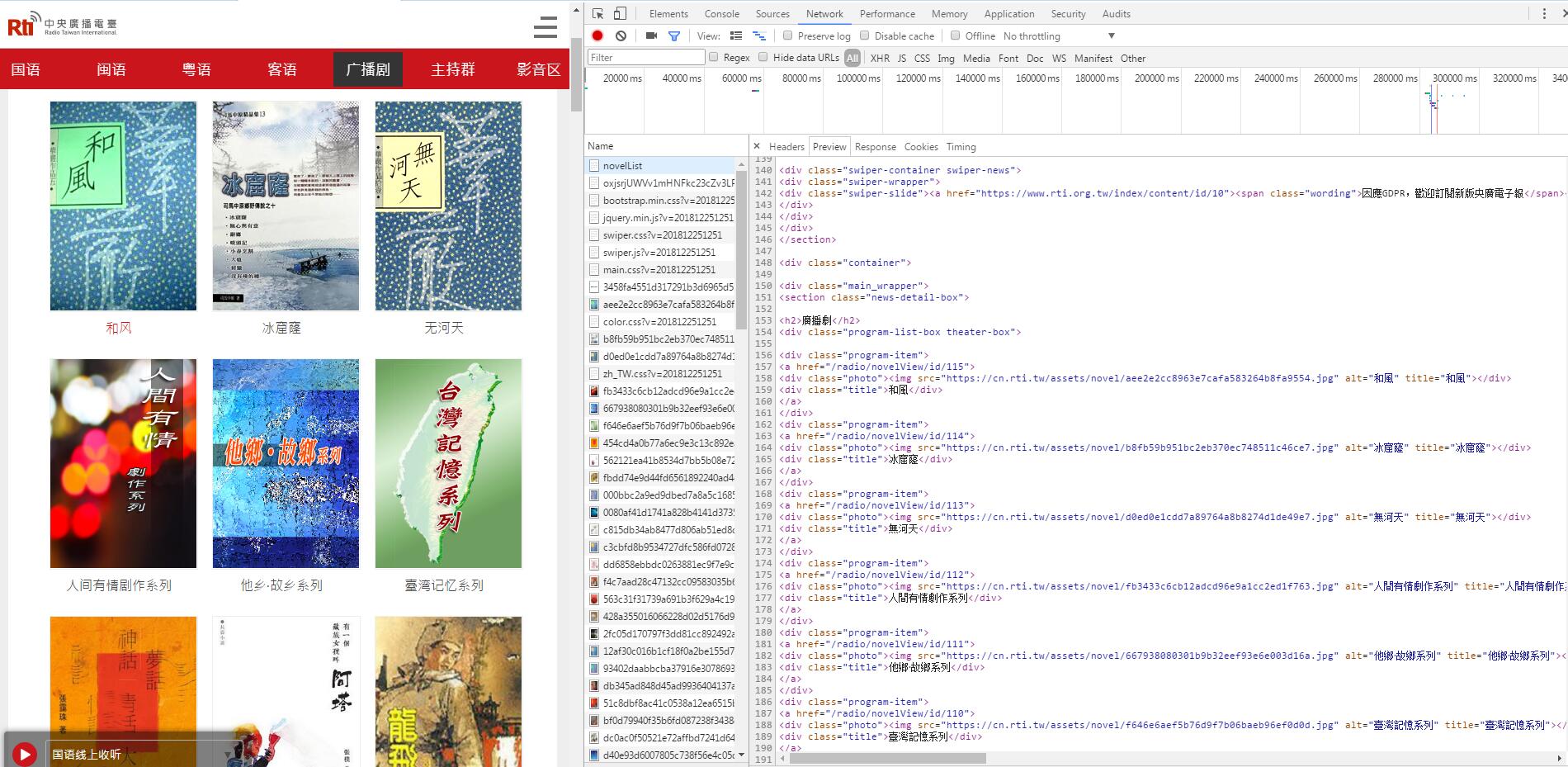
可以看到一个DIV下放一个广播剧的信息,包括名称和地址,第一步我们先收集所有广播剧的收听地址:
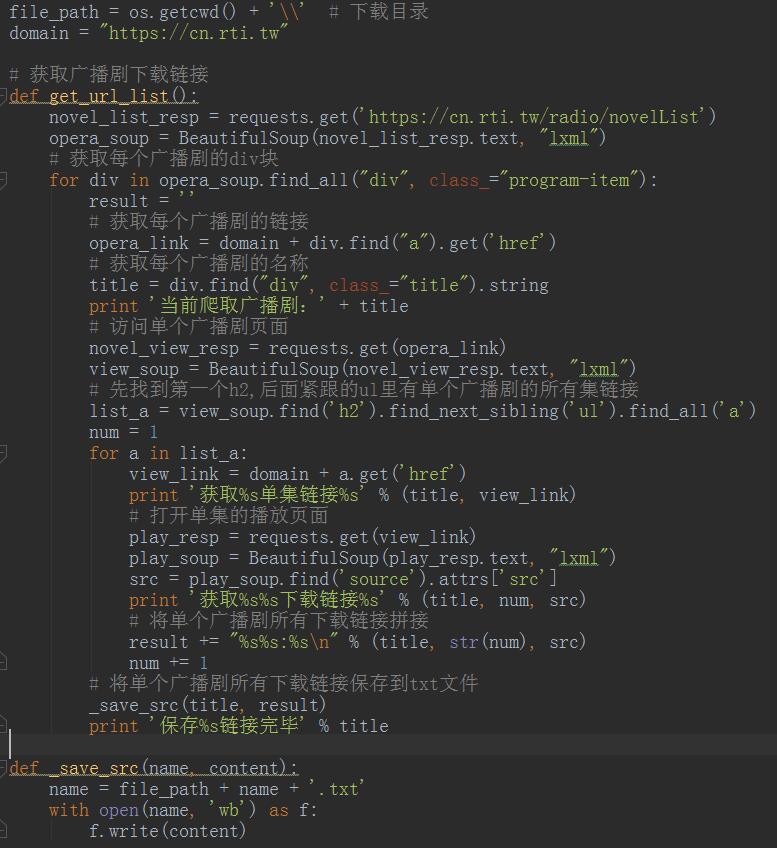
# 用requests的get方法访问
novel_list_resp = requests.get("这里放URL的地址")
# 利用上一步访问返回的结果生成一个BeautifulSoup对象
opera_soup = BeautifulSoup(novel_list_resp.text, "lxml")
# 获取所有class="program-item"的div
opera_soup.find_all("div", class_="program-item")
接着我们遍历这些div,获取每个广播剧的链接和名称:
# 找到div中的a标签,获取每个广播剧的链接
opera_link = domain + div.find("a").get('href')
# 获取每个广播剧的名称
title = div.find("div", class_="title").string
我们点击一个广播剧进去,在HTML中可以看到在ul中,每个li里都有一集的播放链接,并且是按顺序的。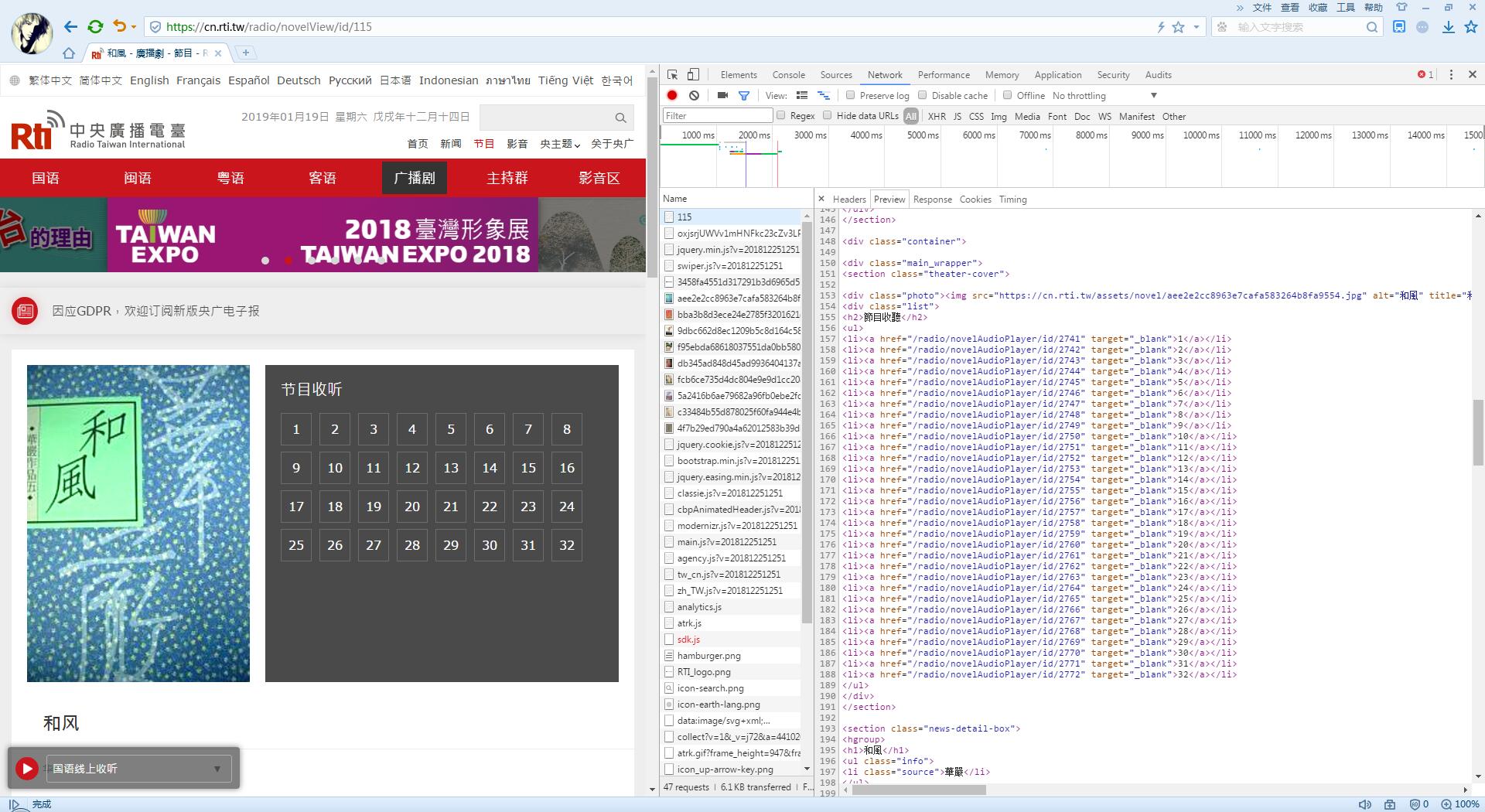
代码中我们继续用之前的方法访问单个广播剧地址,来获取剧集的list:
# 访问单个广播剧页面
novel_view_resp = requests.get(opera_link)
# 利用上一步访问返回的结果生成一个BeautifulSoup对象
view_soup = BeautifulSoup(novel_view_resp.text, "lxml")
# 首先定位h2标签,然后获取h2的下一个ul标签(直接找ul的话会找到其他的ul),然后获取所有a标签
list_a = view_soup.find('h2').find_next_sibling('ul').find_all('a')
# 接着遍历a标签,把每集的地址取出来
view_link = domain + a.get('href')
我们继续看一个单集的播放的HTML,source标签里就是最终的资源地址了,一个MP4文件: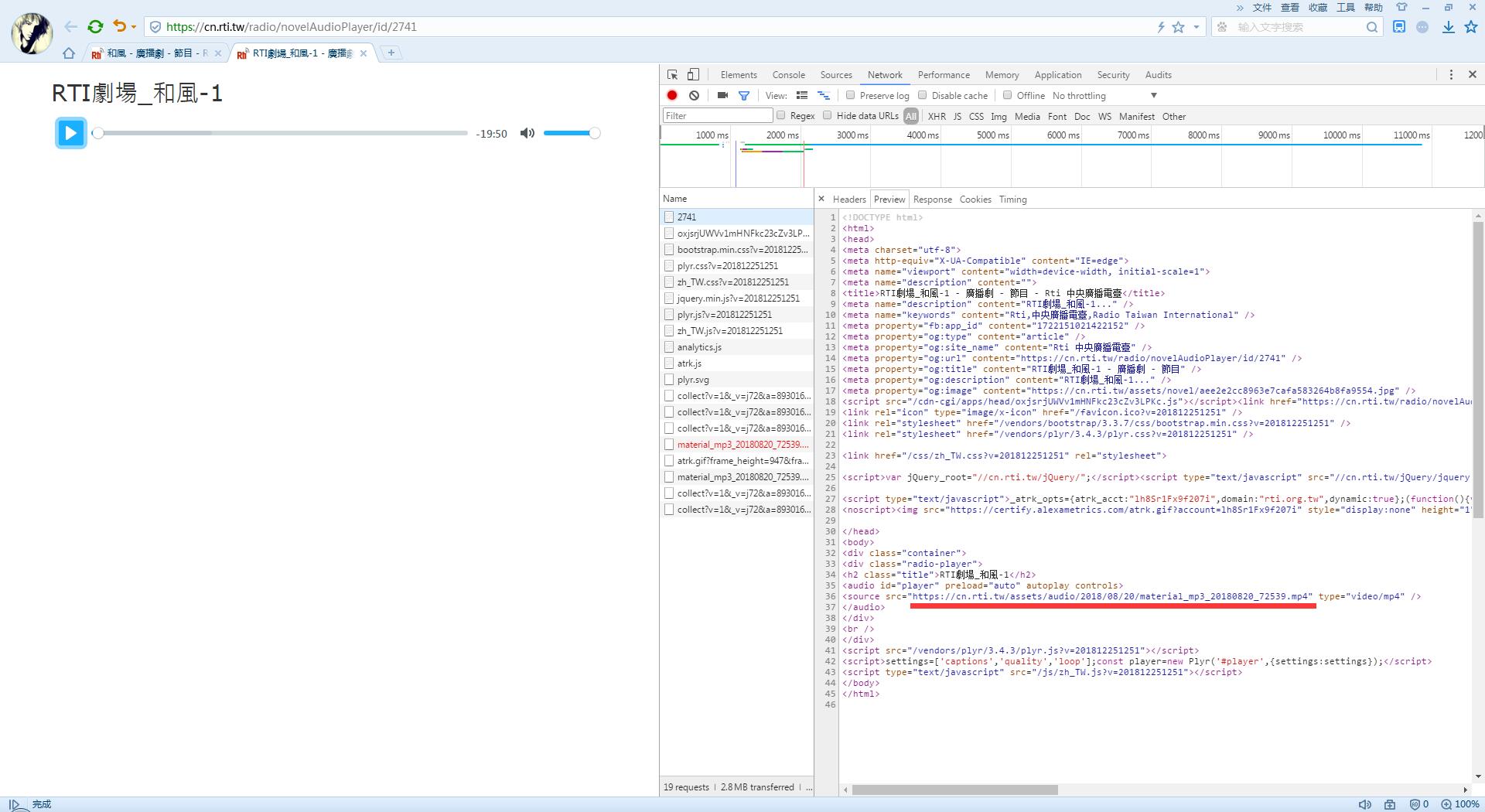
# 打开单集的播放页面
play_resp = requests.get(view_link)
play_soup = BeautifulSoup(play_resp.text, "lxml")
# 获取资源下载地址
src = play_soup.find('source').attrs['src']
现在我还不想下载,我希望先试听确认喜欢后再下载,所以我把下载地址存到一个txt里,一个广播剧存一个txt:
name = file_path + name + '.txt'
with open(name, 'wb') as f:
f.write(content)
由于编码问题,在文件最上加上以下代码:
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
运行效果: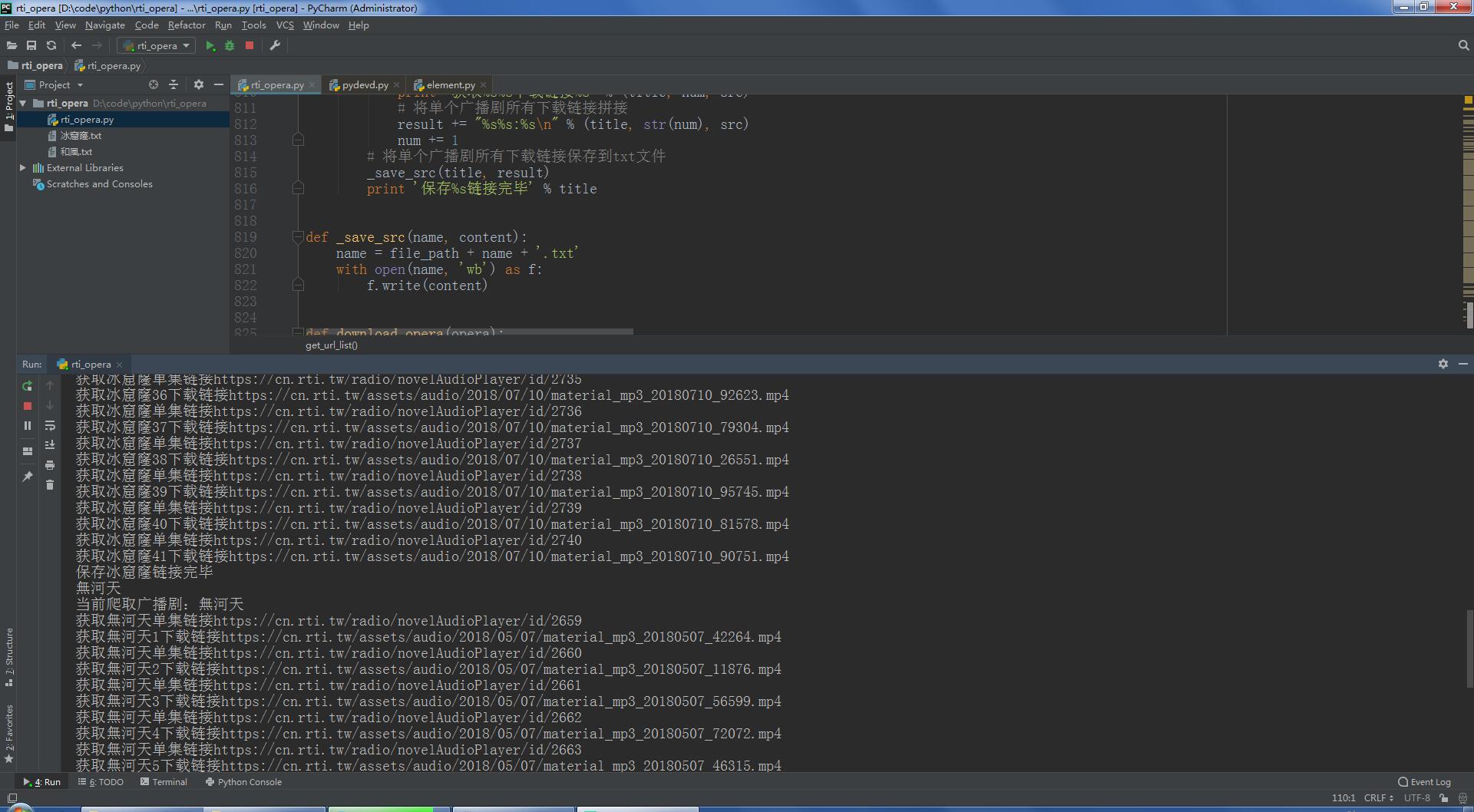
下载的MP4的代码:
# 使用requests的get方法访问下载链接
r = requests.get(url)
# 将访问返回二进制数据内容保存为MP4文件
with open(name, 'wb') as f:
f.write(r.content)
最终的运行结果:
源码地址:https://github.com/songzhenhua/rti_opera/blob/master/rti_opera.py
BeautifulSoup参考地址:
https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#attributes
http://www.cnblogs.com/zhaof/p/6930955.html
爬虫初体验:Python+Requests+BeautifulSoup抓取广播剧的更多相关文章
- python 爬虫(一) requests+BeautifulSoup 爬取简单网页代码示例
以前搞偷偷摸摸的事,不对,是搞爬虫都是用urllib,不过真的是很麻烦,下面就使用requests + BeautifulSoup 爬爬简单的网页. 详细介绍都在代码中注释了,大家可以参阅. # -* ...
- Python requests 多线程抓取 出现HTTPConnectionPool Max retires exceeded异常
https://segmentfault.com/q/1010000000517234 -- ::, - oracle - ERROR - data format error:HTTPConnecti ...
- Python爬虫之requests+正则表达式抓取猫眼电影top100以及瓜子二手网二手车信息(四)
requests+正则表达式抓取猫眼电影top100 一.首先我们先分析下网页结构 可以看到第一页的URL和第二页的URL的区别在于offset的值,第一页为0,第二页为10,以此类推. 二.< ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- 用python实现的抓取腾讯视频所有电影的爬虫
1. [代码]用python实现的抓取腾讯视频所有电影的爬虫 # -*- coding: utf-8 -*-# by awakenjoys. my site: www.dianying.atim ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- Python爬虫工程师必学——App数据抓取实战 ✌✌
Python爬虫工程师必学——App数据抓取实战 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 爬虫分为几大方向,WEB网页数据抓取.APP数据抓取.软件系统 ...
- Python爬虫工程师必学APP数据抓取实战✍✍✍
Python爬虫工程师必学APP数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- Python爬虫工程师必学——App数据抓取实战
Python爬虫工程师必学 App数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
随机推荐
- 从零一起学Spring Boot之LayIM项目长成记(二) LayIM初体验
前言 接上篇,已经完成了一个SpringBoot项目的基本搭建.那么现在就要考虑要做什么,怎么做的问题.所以本篇内容不多,带大家一起来简单了解一下要做的东西,之前有很多人不知道从哪里下手,那么今天我带 ...
- oracle 导出空表问题
select 'alter table '||table_name||' allocate extent;' from user_tables where num_rows=0
- 解决Windows10下小娜无法搜索本地应用的问题
适用场景 小娜突然出现各种问题.比如突然无法搜索到本地应用...等其它问题 一般使用下面的方法,将小娜进行重新注册就ok了. 解决方案 1.用管理员权限打开 C:\Windows\System32\W ...
- MySql is marked as crashed and should be repaired问题
在一次电脑不知道为什么重启之后数据库某表出现了 is marked as crashed and should be repaired这个错误,百度了一下,很多都是去找什么工具然后输入命令之类的,因为 ...
- [videos系列]日本的videos视频让男人产生了哪些误解?
转载自:[videos系列]日本的videos视频让男人产生了哪些误解? 日本的videos视频是每个男人成长过程中都会看的启蒙教育片,也是男人在成年后调剂生活的必需品,但是由于影视作品是艺术的,是属 ...
- 20181030noip模拟赛T1
YY的矩阵 YY有一个大矩阵(N*M), 矩阵的每个格子里都有一个整数权值W[i,j](1<=i<=M,1<=j<=N) 对于这个矩阵YY会有P次询问,每次询问这个大矩阵的一个 ...
- 学习笔记 - 中国剩余定理&扩展中国剩余定理
中国剩余定理&扩展中国剩余定理 NOIP考完回机房填坑 ◌ 中国剩余定理 处理一类相较扩展中国剩余定理更特殊的问题: 在这里要求 对于任意i,j(i≠j),gcd(mi,mj)=1 (就是互素 ...
- (Nagios)-check_openmanage[Dell]
Nagios->check_openmanage[Dell R7*] 2014年11月13日 下午 07:44 需求介绍: 透过Nagios监控Dell R7系列服务器硬件状态 环境信息: ...
- 5. CSS是什么
CSS概念 CSS,层叠样式表,也叫做风格样式表.通过CSS我们可以为页面添加一个美丽的外观,获得更加良好的用户体验.不过值得我们注意的是和HTML一样,CSS也不是编程语言,它只是提供一种配置文件, ...
- curl下载文件
* curl下载文件* 根据业务需求* 通过不同站点去访问路径* 下载文件* 但是不同站点需要设置header头* 这里使用curl方式下载* 具体看代码: //下载地址 $url = 'https: ...