进度条加载与案例优化对比——python使用perf_count方法实现
本章我们将讨论python3 perf_counter()的用法及它的实际应用我从中选取两个python基于rquests库的爬虫实例代码源文件进行举例
Python3 perf_counter() 用法:
调用一次 perf_counter(),从计算机系统里随机选一个时间点A,计算其距离当前时间点B1有多少秒。当第二次调用该函数时,默认从第一次调用的时间点A算起,距离当前时间点B2有多少秒。两个函数取差,即实现从时间点B1到B2的计时功能。
import time
scale = 50
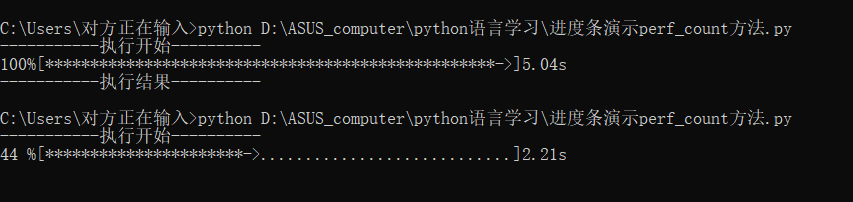
print("执行开始".center(scale//2,"-")) # .center() 控制输出的样式,宽度为 25//2,即 22,汉字居中,两侧填充 -
start = time.perf_counter() # 调用一次 perf_counter(),从计算机系统里随机选一个时间点A,计算其距离当前时间点B1有多少秒。
#当第二次调用该函数时,默认从第一次调用的时间点A算起,距离当前时间点B2有多少秒。两个函数取差,即实现从时间点B1到B2的计时功能。
for i in range(scale+1):
a = '*' * i # i 个长度的 * 符号
b = '.' * (scale-i) # scale-i) 个长度的 . 符号。符号 * 和 . 总长度为50
c = (i/scale)*100 # 显示当前进度,百分之多少
dur = time.perf_counter() - start # 计时,计算进度条走到某一百分比的用时
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end='') # \r用来在每次输出完成后,将光标移至行首,这样保证进度条始终在同一行输出,
#即在一行不断刷新的效果;{:^3.0f},输出格式为居中,占3位,小数点后0位,浮点型数,
#对应输出的数为c;{},对应输出的数为a;{},对应输出的数为b;{:.2f},输出有两位小数的浮点数,
#对应输出的数为dur;end='',用来保证不换行,不加这句默认换行。
time.sleep(0.1) # 在输出下一个百分之几的进度前,停止0.1秒
print("\n"+"执行结果".center(scale//2,'-'))
测试结果:
这当然不止这一点用处
比如你还可以用在程序的性能测试上
进行性能分析比对查找问题
————上例子:
Requests库的爬取性能分析
前一阵子再做网略爬虫,就拿这个最简单例子来讲解感觉挺适合的。
尽管Requests库功能很友好、开发简单(其实除了import外只需一行主要代码),但其性能与专业爬虫相比还是有一定差距的。请编写一个小程序,“任意”找个url,测试一下成功爬取100次网页的时间。(某些网站对于连续爬取页面将采取屏蔽IP的策略,所以,要避开这类网站。)
在这里我们以百度为url链接测试,代码如下:
first_test.py
import time
import requests
def getHtml(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent.encoding
return url.text
except:
return("The requests get url found unkonw-mistakes.")
def main():
url = "https://baidu.com"
time1 = time.time()
i = 0
while(i<100):
start = time.time()
getHtml(url)
end = time.time()
i += 1
print('第{}次爬取耗时{}s'.format(i+1,end-start))
time2 = time.time()
print(time2-time1)
if __name__ =='__main__':
main()
运行结果:

如图所示大约共耗时31.19s .
ok,让我们进行接下来的测试.........
second_test.py
import requests
import time
def getHTMLText_timecost(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return 'ERRO'
def main():
url = 'https://www.baidu.com'
sumtime = 0
succtimes = 0
for i in range(100):
start = time.time()
res = getHTMLText_timecost(url)
if res != 'ERRO':
succtimes += 1
end = time.time()
timecost = end - start
sumtime += timecost
print('第{}次爬取耗时{}s'.format(i+1,timecost))
print('共爬取{}次,耗时{}s,其中爬取成功{}次'.format(i+1,sumtime,succtimes))
if __name__ == '__main__':
main()
运行结果:
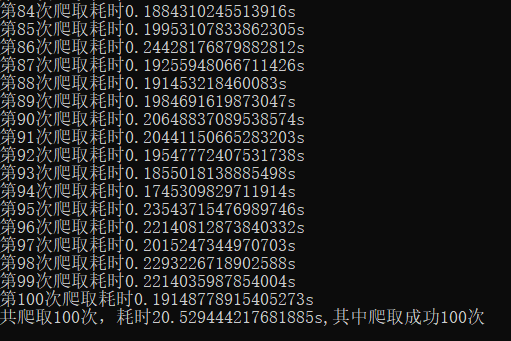
如图所示大约共耗时20.53s .
经过这两段代码的调试运行,我们发现相同功能下不同代码之间存在着性能的差异,并随着运
算工作量的提升而愈发明显这就需要我们对代码进行科学的分析与思考寻求更优的方案投入到实际应用中。
进度条加载与案例优化对比——python使用perf_count方法实现的更多相关文章
- 简单实用的进度条加载组件loader.js
本文提供一个简单的方法实现一个流程的进度条加载效果,以便在页面中可以通过它来更好地反馈耗时任务的完成进度.要实现这个功能,首先要考虑怎样实现一个静态的进度条效果,类似下面这样的: 这个倒是比较简单,两 ...
- 超酷jQuery进度条加载动画集合
在丰富多彩的网页世界中,进度条加载动画的形式非常多样,有利用gif图片实现的loading动画,也有利用jQuery和CSS3实现的进度加载动画,本文主要向大家介绍很多jQuery和CSS3实现的进度 ...
- 【消灭代办】第5周 - null拷贝,input自适应,进度条加载,颜色随机值
2018.12.10 代办一:javascript中js怎么拷贝null的值 null属于简单类型的数值,直接进行拷贝即可: 2018.12.11 代办二:怎么让input自适应宽度? 这样是写下代办 ...
- 学习 | css3实现进度条加载
进度条加载是页面加载时的一种交互效果,这样做的目的是提高用户体验. 进度条的的实现分为3大部分:1.页面布局,2.进度条动效,3.何时进度条增加. 文件目录 加载文件顺序 <link rel=& ...
- vue 路由懒加载 使用,优化对比
vue这种单页面应用,如果没有应用懒加载,运用webpack打包后的文件将会异常的大,造成进入首页时,需要加载的内容过多,时间过长,会出啊先长时间的白屏,即使做了loading也是不利于用户体验,而运 ...
- Vue项目开发,nprogress进度条加载之超详细讲解及实战案例
Nprogress的默认进度条很细,它的设计灵感主要来源于 谷歌,YouTube 他的安装方式也很简单,你可以有两种使用方式: 直接引入js和css文件 使用npm安装的的方式 直接引入: Npm安装 ...
- iOS-WKWebview 带有进度条加载的ViewController【KVO监听Webview加载进度】
前言 为什么要说 WKWebview,在之前做电子书笔记时已经提过 WKWebview 在iOS8之后已完全替代 Webview,原因就不多说了,主要还是内存过大: 封装 封装一个基于 UIViewC ...
- handler 异步执行(进度条加载到100)
生明一个handler 对象(可重写handlerMessage 方法) 声明一个Runnable 对象,需重写run方法 按钮事件:handler对象实例的post方法调用线程. 线程的run方法开 ...
- CSS3 Loading进度条加载动画特效
在线演示 本地下载
随机推荐
- XCode: 如何添加自定义代码片段
转载自:http://rockonmycode.com/tips/xcode-code-snippets#more-185 我们经常会定义一些retain的property,而且大概每次我们都会像这样 ...
- 跟我一起写 Makefile (Linux )
1.昨天 在 Linux 下用 touch 指令 新建了一个 hello.c 并且使用 vim 编辑器 写了代码 ,使用 gcc 指令编译 最后运行 成功了 .具体方式如下: 在Linux 根目 ...
- Oracle 左连接(+)加号用法及常用语法之间的关系
本文目的: 通过分析左连接(+)加号的写法和一些常用语法之间的联系,了解到Oracle 加号(+)的用法 分析步骤: 1.首先创建测试表的结构: create table test_left_a (a ...
- 工具 | Axure基础操作 No.3
下午了,再来补一些学习,今天东西不多哦,感觉慢慢上手了. 1.设置元件禁用状态 2.设置单选按钮唯一选中 注意这里在浏览器中就只能唯一选中了. 3.设置图片上的文字 4.图片的切割和裁剪 5.嵌入多媒 ...
- 爬虫——Scrapy框架案例一:手机APP抓包
以爬取斗鱼直播上的信息为例: URL地址:http://capi.douyucdn.cn/api/v1/getVerticalRoom?limit=20&offset=0 爬取字段:房间ID. ...
- DOM节点操作阶段性总结
HTML中能看到的所有东西都是dom树中的一个节点,注意是“所有”,使用childNodes()可以看到,回车(换行)也是一个节点. 从上图可以看到,select中有四个option,但是有9个节点. ...
- VUE通过索引值获取数据不渲染的问题
问题:vue里面当通过索引值获取数据时,ajax数据成功返回,但是在火狐下不渲染 解决:
- 【Storm一】Storm安装部署
storm安装部署 解压storm安装包 $ tar -zxvf apache-storm-1.1.0.tar.gz -C /usr/local/src 修改解压后的apache-storm-1.1. ...
- python学习——初始面向对象
一.讲在前面 编程的世界中有三大体系,面向过程.面向函数和面向对象编程.而面向过程的编程就包括了面向函数编程,接下来说一下面向对象.假如 ,你现在是一家游戏公司的开发人员,现在需要你开发一款叫做< ...
- vue生命周期和react生命周期对比
一 vue的生命周期如下图所示(很清晰)初始化.编译.更新.销毁 二 vue生命周期的栗子 注意触发vue的created事件以后,this便指向vue实例,这点很重要 <!DOCTYPE ht ...