解决 Python 的字符串 center ljust rjust 在面对中文时的 bug
方法一:修改内置 str 的方法,能更灵活的定制,更准确地判断 CJK 字符,全局有效。甚至还能把转义序列也兼容了。
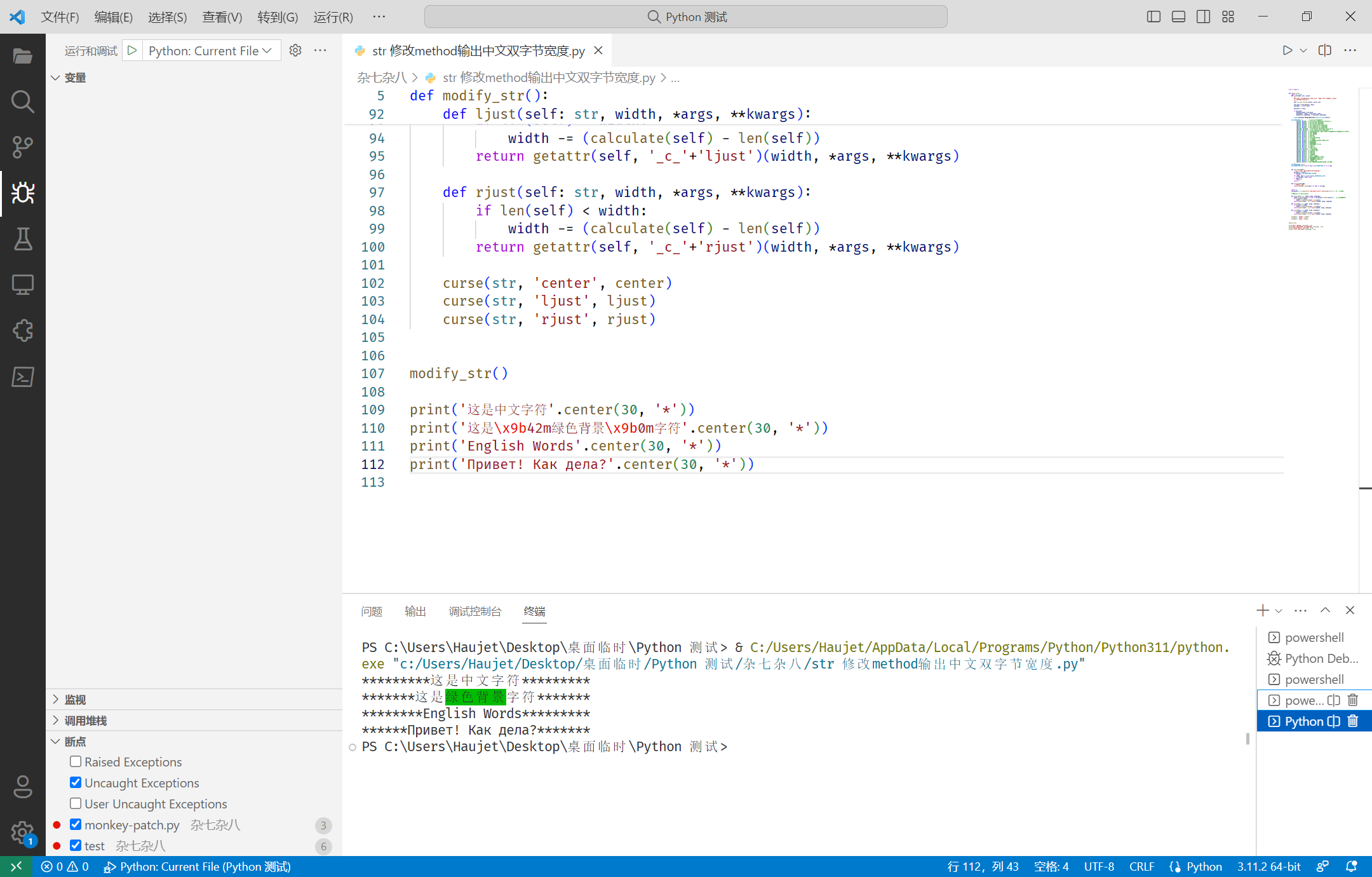
def modify_str():
import gc, ctypes
def curse(klass, attr, value):
"""
这里用的是 forbiddenfruit 库的 curse 简化了一下,省去了下载第三方库
用于修改内置 class 的属性
"""
dikt = gc.get_referents(klass.__dict__)[0]
old_value = dikt.get(attr, None)
old_name = '_c_%s' % attr
dikt[attr] = value
if old_value:
dikt[old_name] = old_value
dikt[attr].__name__ = old_value.__name__
dikt[attr].__qualname__ = old_value.__qualname__
ctypes.pythonapi.PyType_Modified(ctypes.py_object(klass))
CJK_CHARACTERS = [ # 定义 CJK 字符的区间
(0x3400, 0x4DB5), # CJK Unified Ideographs Extension A
(0x4E00, 0x9FA5), # CJK Unified Ideographs
(0x9FA6, 0x9FBB), # CJK Unified Ideographs
(0xF900, 0xFA2D), # CJK Compatibility Ideographs
(0xFA30, 0xFA6A), # CJK Compatibility Ideographs
(0xFA70, 0xFAD9), # CJK Compatibility Ideographs
(0x20000, 0x2A6D6), # CJK Unified Ideographs Extension B
(0x2F800, 0x2FA1D), # CJK Compatibility Supplement
(0xFF00, 0xFFEF), # 全角ASCII、全角中英文标点、半宽片假名、半宽平假名、半宽韩文字母
(0x2E80, 0x2EFF), # CJK部首补充
(0x3000, 0x303F), # CJK标点符号
(0x31C0, 0x31EF), # CJK笔划
(0x2F00, 0x2FDF), # 康熙部首
(0x2FF0, 0x2FFF), # 汉字结构描述字符
(0x3100, 0x312F), # 注音符号
(0x31A0, 0x31BF), # 注音符号(闽南语、客家语扩展)
(0x3040, 0x309F), # 日文平假名
(0x30A0, 0x30FF), # 日文片假名
(0x31F0, 0x31FF), # 日文片假名拼音扩展
(0xAC00, 0xD7AF), # 韩文拼音
(0x1100, 0x11FF), # 韩文字母
(0x3130, 0x318F), # 韩文兼容字母
(0x1D300, 0x1D35F), # 太玄经符号
(0x4DC0, 0x4DFF), # 易经六十四卦象
(0xA000, 0xA48F), # 彝文音节
(0xA490, 0xA4CF), # 彝文部首
(0x2800, 0x28FF), # 盲文符号
(0x3200, 0x32FF), # CJK字母及月份
(0x3300, 0x33FF), # CJK特殊符号(日期合并)
(0x2700, 0x27BF), # 装饰符号(非CJK专用)
(0x2600, 0x26FF), # 杂项符号(非CJK专用)
(0xFE10, 0xFE1F), # 中文竖排标点
(0xFE30, 0xFE4F), # CJK兼容符号(竖排变体、下划线、顿号)
]
CJK_CHARACTERS.sort()
CJK_CHARACTERS_LIST = [a for tup in CJK_CHARACTERS for a in tup]
def char_width(char):
'''按一个 CJK 占两个宽度算,返回字符宽度'''
unicode = ord(char)
if unicode < CJK_CHARACTERS_LIST[0]:
return 1
for index, item in enumerate(CJK_CHARACTERS_LIST):
if unicode < item: break
if index % 2:
return 2
return 1
def calculate(string):
'''字符串总宽度'''
return sum([char_width(char) for char in string])
import re
csi_pattern = re.compile("(?:\x9b|\033\[)\d*(?:;\d*)*[A-Za-z]") # 用于匹配转义序列
# 重新定义 str 的三个方法:
def center(self: str, width, *args, **kwargs):
width += sum([len(csi) for csi in csi_pattern.findall(self)]) # 加上转义序列的补偿
if len(self) < width:
width -= (calculate(self) - len(self))
return getattr(self, '_c_'+'center')(width, *args, **kwargs)
def ljust(self: str, width, *args, **kwargs):
if len(self) < width:
width -= (calculate(self) - len(self))
return getattr(self, '_c_'+'ljust')(width, *args, **kwargs)
def rjust(self: str, width, *args, **kwargs):
if len(self) < width:
width -= (calculate(self) - len(self))
return getattr(self, '_c_'+'rjust')(width, *args, **kwargs)
curse(str, 'center', center)
curse(str, 'ljust', ljust)
curse(str, 'rjust', rjust)
modify_str()
print('这是中文字符'.center(30, '*'))
print('这是\x9b42m绿色背景\x9b0m字符'.center(30, '*'))
print('English Words'.center(30, '*'))
print('Привет! Как дела?'.center(30, '*'))
方法二:先用 gbk 编码,调整后,再解码。局限性较大,不能准确判断 CJK 符号,不易兼容其它国家的语言。
# 一般中文宽度是英文的两倍,带有中文的字符串使用 center ljust rjust 会出现宽度非常不一致
# 我们希望中文可以按两个宽度计算
# 可以利用 gbk 是双字节编码,中文字符占2字节,英文字符占1字节
# 将字符串用 gbk 编码后,再用 center ljust rjust,最后用 gbk 解码,就可以得到视觉上中英文一致的宽度
# 需要注意的是,有一些偏僻字使用 gbk 是无法编码的,例如:
print('\x9b42m 展示 \x9b0m')
print('这是中文字符'.encode('gbk').center(30, b'*').decode('gbk'))
print('English Words'.encode('gbk').center(30, b'*').decode('gbk'))
解决 Python 的字符串 center ljust rjust 在面对中文时的 bug的更多相关文章
- 解决python中write()函数向文件中写中文时出现乱码的问题
今天看<python编程从入门到实践>的第10章文件.异常,在做练习的时候,向文件中写内容,但是写中文就不行,后来在百度上查了众多资料,解决方法如下: 解决:在open()函数中添加一个e ...
- python center, ljust, rjust
例子 >>> s = "jihite" >>> s.center(, "*") '**jihite**' >>& ...
- 【python】 字符串转小写(含汉字等时仍work)
def mylower(str): outstr = ""; strlen = len(str); idx = 0; while idx < strlen: if ord(s ...
- Python: ljust()|rjust()|center()字符串对齐
通过某种对齐方式来格式化字符串 ①对于基本的操作,可以使用字符串的ljust(),rjust(),center() ②函数format()同样可以用来很容易的对齐字符串,使用<,>,~
- python之字符串
字符串与文本操作 字符串: Python 2和Python 3最大的差别就在于字符串 Python 2中字符串是byte的有序序列 Python 3中字符串是unicode的有序序列 字符串是不可变的 ...
- Python数据类型——字符串
概论 字符串顾名思义就是一串字符,由于Python中没有“字符”这种数据类型,所以单个的字符也依然是字符串类型的.字符串可以包含一切数据,无论是能从键盘上找到的,还是你根本都不认识的.与数一样,字符串 ...
- python基础-字符串(str)类型及内置方法
字符串-str 用途:多用于记录描述性的内容 定义方法: # 可用'','''''',"","""""" 都可以用于定义 ...
- python中字符串内置方法
字符串类型 作用:定义姓名.性别等 定义方式: s='lzs' #\n换行 \t缩进4个空格 \r回退上一个打印结果,覆盖上一个打印结果 加上一个\让后面的\变得无意义 内置方法: (优先掌握) 1. ...
- python之字符串,列表,字典,元组,集合内置方法总结
目录 数字类型的内置方法 整型/浮点型 字符串类型的内置方法 列表的内置方法 字典的内置方法 元组的内置方法 集合类型内置方法 布尔类型 数据类型总结 数字类型的内置方法 整型/浮点型 加 + 减 - ...
- Python格式化字符串~转
Python格式化字符串 在编写程序的过程中,经常需要进行格式化输出,每次用每次查.干脆就在这里整理一下,以便索引. 格式化操作符(%) "%"是Python风格的字符串格式化操作 ...
随机推荐
- 应用和 IPv6
应用和 IPv6 前言 在数据中心网络IPv6协议改造时,我们通常更关注路由交换的部分.对于应用系统适配IPv6 网络确缺少关注,本文旨在更多的讨论应用和IPv6 的关系,帮助个人.公司和组织能够更改 ...
- autossh 使用
Table of Contents 1. centos7下配置为服务 2. 命令式使用 2.1. 映射远程主机防火墙之后的端口到本机 2.2. 映射本机端口到远程主机 centos7下配置为服务 编辑 ...
- debian 系统中安装 broadcom 无线网卡驱动
首先要修改 apt 的配置文件,允许安装 non-free 软件.即在 /etc/apt/sources.list 中生效的行的最后加上 contrib non-free,再使用 apt-get up ...
- SpringBoot笔记--配置->profile的配置
profile--动态配置切换 profile配置方式: 使用spring.profile.active=进行激活.properties文件 直接使用一个.yml文件代替多文件配置 使用---分隔符分 ...
- Python学习笔记--循环的知识以及应用
while循环 代码: 结果: 案例:求1-100的和 实现: 案例:while循环猜数字 实现: while循环的嵌套使用 案例:打印九九乘法表 (注意:要是想要输出不换行,代码可以这样写:prin ...
- RHEL8使用NMCLI管理网络
使用 NMCLI 配置静态以太网连接 要在命令行上配置以太网连接,请使用 nmcli 工具. 例如,以下流程使用以下设置为 enp7s0 设备创建 NetworkManager 连接配置文件: 静态 ...
- MyBatisPlus-------id生成策略
不同的表对应不同的id生成策略 日志:自增 购物订单:特殊规则(FQ23324AK443) 外卖单:关联地区日期等信息( 10 04 20200314 34 91) 关系表:可省略id ....... ...
- 源码解读之FutureTask如何实现最大等待时间
预备知识:Java 线程挂起的常用方式有以下几种 Thread.sleep(long millis):这个方法可以让线程挂起一段时间,并释放 CPU 时间片,等待一段时间后自动恢复执行.这种方式可以用 ...
- react中类组件、函数组件、state、单层遍历、多层遍历、先遍历后渲染、if-else、三目运算符
1.回顾 module.exports = { entry: {}, output: {}, plugins: [], module: {}, resolve: {}, devServe: {} } ...
- 必知必会的 WebSocket 协议
文章介绍 WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议,它的出现使客户端和服务器之间的数据交换变得更加简单.WebSocket 通常被应用在实时性要求较高的场景,例如赛事数据. ...