猿人学python爬虫第一题
打开网站。F12,开启devtools。发现有段代码阻止了我们调试
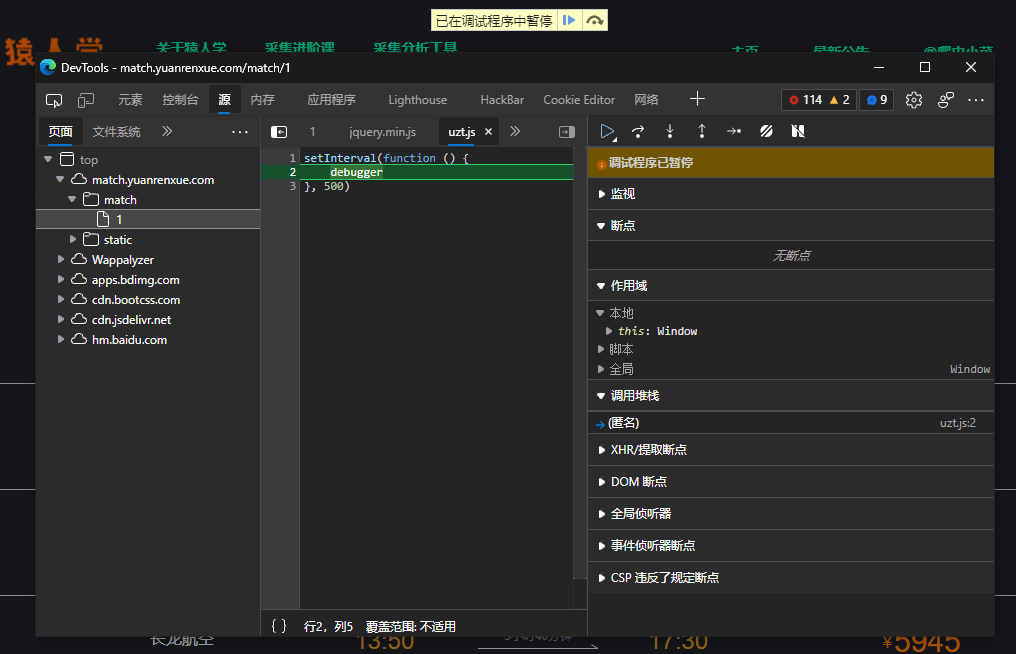
好的。接下来有几种解决方法
1- 绕过阻止调试方法
方法1(推荐)
鼠标放在debugger该行,左边数字行号那一列。右键选择不在永不在此处暂停
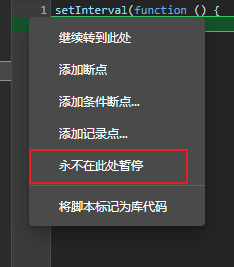
再次点击恢复,就跳出该debbug了
方法2 (抓包改返回)
我用的抓包软件是burp,burp默认不拦截js请求。需要更改成拦截js请求。更改教程
拦截对应代码的文件,将其中内容去掉,保证它发挥不出原本的功能就行

2- 反混淆包含数据的请求代码
经过上一步,我们可以正常调试代码了。这一步我们要找到包含价格数据的请求,然后爬取它。最后就大功告成!可是这个过程似乎并不顺利
- 找到含有数据的请求
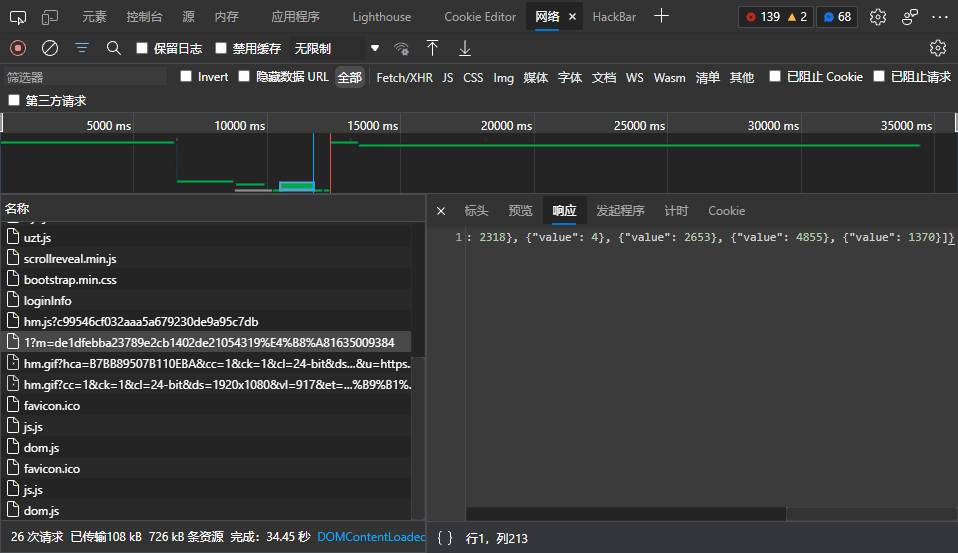
所以,只要传入m,还有page,就可以返回数据。关于m的生成,在后面
查看该请求调用堆栈

进入eval方法
因为eval是除主程序外最先开始调用的。所以要找的代码在这里
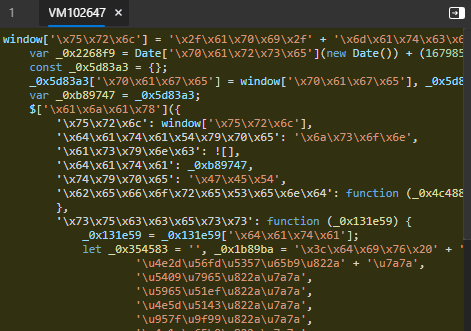
关于VM102647该文件:我认为这个文件就是传入eval的内容,然后调试器帮我们代码美化了下,就成为了这个文件。
4. 代码反混淆
官方js反混淆网址
记得复制所有代码进去。不要漏掉底下下的request()。

这是图片,拖动条拖不得
3-分析m的生成

抛开其中无关代码,只找有关m生成的
var _0x2268f9 = Date.parse(new Date()) + 100000000, _0x57feae = oo0O0(_0x2268f9.toString()) + window.f;_
0x5d83a3.m = oo0O0(_0x2268f9.toString()) + window.f + '丨' + _0x2268f9 / 1000;
不难发现,需要找到oo0O0 函数的实现方法。其他要么就是系统自带,要么就是变量。我们先关注该函数是怎么实现的
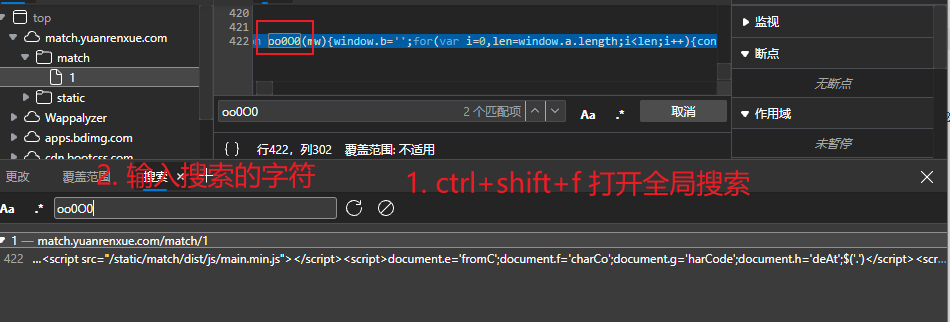
找到该代码位置,复制该行下来。
丢进之前的反混淆网站上去,里面有代码美化功能

这个网站解密要把一些其他的js标签,如<script>..<script> 将它们删除,只留下包含目标函数的js标签。然后去解密才可以代码美化。
分析该函数代码,最后一行有个eval。
● atop 将base64代码解密
● window['b'] 包含base64代码,里面经过atop解密出一些js代码
● J('0x0', ']dQW') 一个混淆,拿到调试器控制台去运行发现是 "replacee" 这个字符串
● J('0x1', 'GTu!') 一个混淆,解密发现是 "mwqqppz" 这个字符串
● '\x27' + mw + '\x27' 就拿单引号包着这个变量。
该代码的意思是,将字符串mwqqppz替换为 '\x27' + mw + '\x27'
运行 atob(window['b']
运行atob(window['b'])[J('0x0', ']dQW')](J('0x1', 'GTu!'), '\x27' + '123456' + '\x27')
不难看出,这就是一个简单替换。即
windows.f = hex_md5(mv)
将相关加密代码copy到本地
在同文件中编写生成m的函数,以便于python调用该函数
function get_m_value() {
var _date = Date.parse(new Date()) + 100000000;
var f = hex_md5(_date.toString());
var m = f + '丨' + _date / 1000;
return m;
}
编写python代码
import requests
import execjs
import time
requests.packages.urllib3.disable_warnings()
def get_res(page_num, parm):
url = f'https://match.yuanrenxue.com/api/match/1?page={page_num}&m={parm}'
headers = {
'Host': 'match.yuanrenxue.com',
'Referer': 'http://match.yuanrenxue.com/match/1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'Hm_lvt_c99546cf032aaa5a679230de9a95c7db=1634894322; qpfccr=true; no-alert3=true; Hm_lvt_9bcbda9cbf86757998a2339a0437208e=1634894331; vaptchaNetway=cn; Hm_lvt_0362c7a08a9a04ccf3a8463c590e1e2f=1634894320,1634894605; Hm_lpvt_0362c7a08a9a04ccf3a8463c590e1e2f=1634894656; tk=2886305154209229651; Hm_lpvt_9bcbda9cbf86757998a2339a0437208e=1634900896; Hm_lpvt_c99546cf032aaa5a679230de9a95c7db=1634902874'
}
proxies = {
'http' : 'http://127.0.0.1:8888',
'https' : 'http://127.0.0.1:8888',
}
if page_num > 3:
headers['Cookie'] = headers['Cookie'] + ';sessionid=1;'
headers['User-Agent'] = 'yuanrenxue.project'
resp = requests.get(url=url, headers=headers, verify=False, timeout=5, proxies='')
if resp.status_code < 400:
return resp.json()
else:
print("Error!!")
def calc_m_value():
with open('get_m.js', mode='r', encoding='utf-8') as f:
jsdata = f.read()
m_value = execjs.compile(jsdata).call('get_m_value')
result = m_value.replace("丨", "%E4%B8%A8")
return result
def calc_result(res_data):
global _sum
for item in res_data['data']:
_sum += item['value']
if __name__ == '__main__':
_sum = 0
m = calc_m_value()
for page in range(1,6):
res_data = get_res(page, m)
calc_result(res_data)
time.sleep(1)
print(_sum)
print(_sum/50)
猿人学python爬虫第一题的更多相关文章
- python爬虫第一天
python爬虫第一天 太久没折腾爬虫 又要重头开始了....感谢虫师大牛的文章. 接下来的是我的随笔 0x01 获取整个页面 我要爬的是百度贴吧的图,当然也是跟着虫师大牛的思路. 代码如下: #co ...
- Python爬虫第一步
这只是记录一下自己学习爬虫的过程,可能少了些章法.我使用过的是Python3.x版本,IDE为Pycharm. 这里贴出代码集合,这一份代码也是以防自己以后忘记了什么,方便查阅. import req ...
- #000 Python 入门第一题通过扩展,学到了更多的知识
#1写在前面的话 我觉得这样学习或许能够在学习的过程中事半功倍 第一道简单的python编写代码输出10行带标号的“Hello,world.”,具体效果参阅输入输出示例 1:Hello,world. ...
- Python爬虫第一个成功版
爬取http://www.mzitu.com/all里面的图片 import urllib.request import re import os url = 'http://www.mzitu.co ...
- Python爬虫第一集
import urllib2 response = urllib2.urlopen("http://www.baidu.com") print response.read() 简单 ...
- 如何让Python爬虫一天抓取100万张网页
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 王平 源自:猿人学Python PS:如有需要Python学习资料的 ...
- 我用Python爬虫挣钱的那点事
在下写了10年Python,期间写了各种奇葩爬虫,挣各种奇葩的钱,写这篇文章总结下几种爬虫挣钱的方式. 1.最典型的就是找爬虫外包活儿.这个真是体力活,最早是在国外各个freelancer网站上找适合 ...
- Python爬虫入门教程 12-100 半次元COS图爬取
半次元COS图爬取-写在前面 今天在浏览网站的时候,忽然一个莫名的链接指引着我跳转到了半次元网站 https://bcy.net/ 打开之后,发现也没有什么有意思的内容,职业的敏感让我瞬间联想到了 c ...
- Python爬虫入门教程: 半次元COS图爬取
半次元COS图爬取-写在前面 今天在浏览网站的时候,忽然一个莫名的链接指引着我跳转到了半次元网站 https://bcy.net/ 打开之后,发现也没有什么有意思的内容,职业的敏感让我瞬间联想到了 c ...
随机推荐
- BM 学习笔记
两个 BM 哟 1.Bostan-Mori 常系数其次线性递推. 实际上这个算法是用来计算 \([x^n]\frac {F(x)}{G(x)}\) 的... 我们考虑一个神奇的多项式:\(F(x)F( ...
- Oracle在存储过程中建表、建索引权限不足
修改存储过程,在存储过程名称后面添加 Authid Current_User 后执行通过. CREATE OR REPLACE PROCEDURE p_test Authid Current_User ...
- bitsadmin windwos自带下载命令
bitsadmin的四种下载文件的方法 一. bitsadmin /rawreturn /transfer getfile http://qianxiao996.cn/1.txt c:\1.txt 二 ...
- Windows&Linux文件传输方式总结
在渗透过程中,通常会需要向目标主机传送一些文件,来达到权限提升.权限维持等目的,本篇文章主要介绍一些windows和Linux下常用的文件传输方式. Windows 利用FTP协议上传 在本地或者VP ...
- volatile 有什么用?能否用一句话说明下 volatile 的应用场景?
volatile 保证内存可见性和禁止指令重排. volatile 用于多线程环境下的单次操作(单次读或者单次写).
- spring-boot-learning-监听事件
Springboot扩展了Spring的ApplicatoionContextEvent,提供了事件: ApplicationStartingEvent:框架启动事件 ApplicationEnvir ...
- git-learningmeiy
什么是版本控制-版本迭代: 版本控制(Revision control)是一种在开发的过程中用于管理我们对文件.目录或工程等内容的修改历史,方便查看更改历史记录,备份以便恢复以前的版本的软件工程技术. ...
- 什么是基于 Java 的 Spring 注解配置?
基于 Java 的配置,允许你在少量的 Java 注解的帮助下,进行你的大部分 Spring 配置而非通过 XML 文件. 以@Configuration 注解为例,它用来标记类可以当做一个 bean ...
- 列举 Spring Framework 的优点?
由于 Spring Frameworks 的分层架构,用户可以自由选择自己需要的组件. Spring Framework 支持 POJO(Plain Old Java Object) 编程,从而具备持 ...
- resin服务之三---独立resin的配置
独立resin的配置 关掉httpd服务: [root@data-1-1 ~]# killall httpd [root@data-1-1 ~]# lsof -i :80 ------>h ...