Eureka高可用集群服务端和客户端配置
微服务应用中,生产环境一般都需要保障服务注册中心的高可用!高可用也分好几个等级,例如:同数据中心(可用Zone区)高可用——》同地域(Region)跨数据中心(可用Zone区)高可用——》全国跨地域(Region)跨数据中心(可用Zone区)高可用——全球跨地域(Region)跨数据中心(可用Zone区)高可用,常规应用基本上中间两种就能满足了!当然也会有国际型应用要进行全球部署。不同部署要求,如果是自己搭建部署环境,那么服务器的选购就要做好规划。下面的截图是阿里云ECS的选购界面,切它出来不是为了打广告,是借用它的数据中心分布来说明本文的主角Eureka的高可用集群部署(我们这里演示Eureka的 同地域(Region)跨数据中心(可用Zone区)高可用 部署;全国版也是类似的,只是将全国范围看成一个region,再在华北、华东、华南等各选一个zone,然后每个zone内部再做多一层 同数据中心(可用Zone区)高可用 部署即可,全国版需要考虑成本和远距离服务注册列表数据同步延迟的问题!),截图可以放大来看:
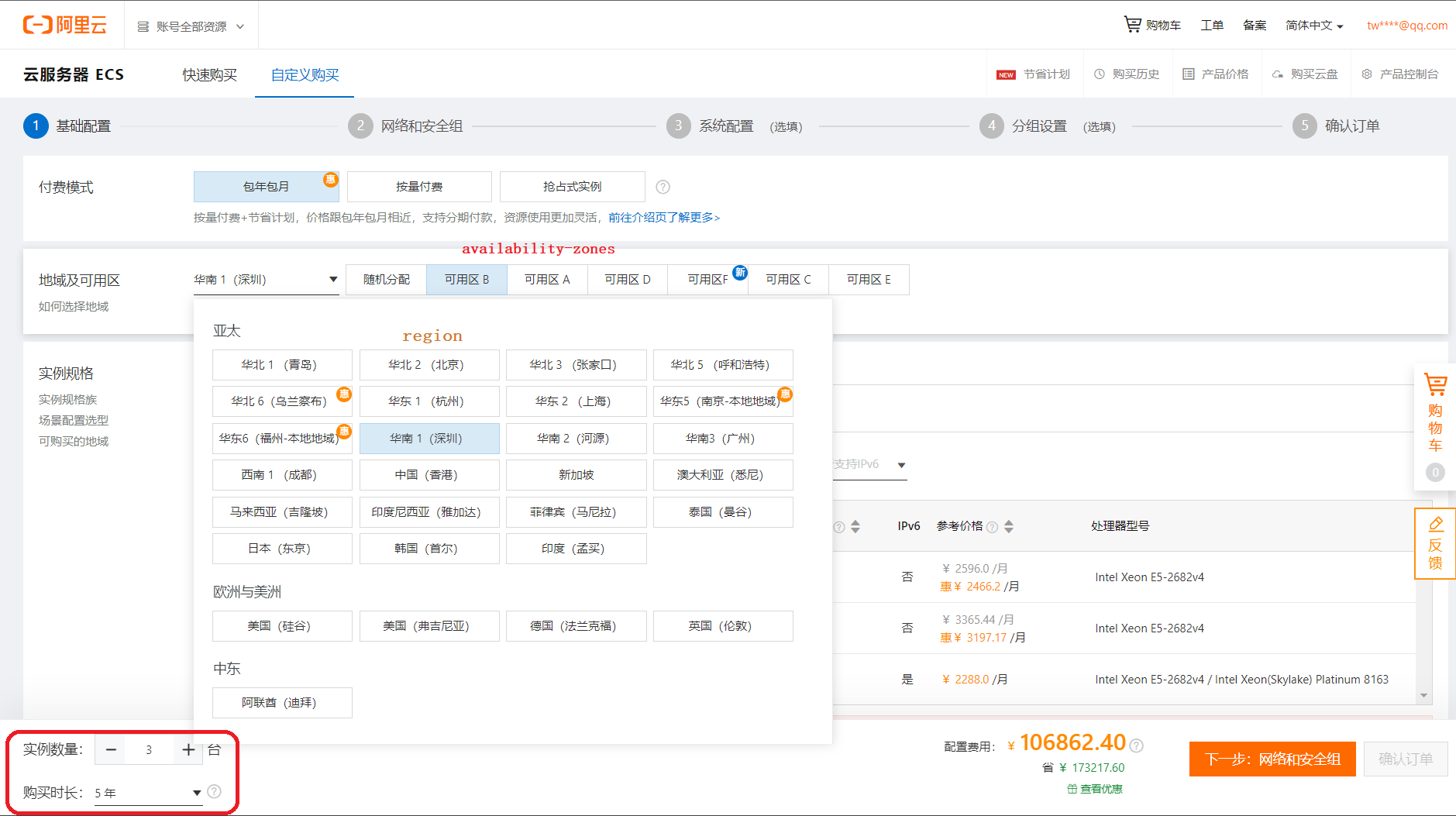
从阿里云的服务器选购界面我们可以看到:有点实力的服务器供应商一般都会从全球范围内建设数据中心(机房)。但打包这些服务器供用户选择购买时,使用两级标签就能唯一确定服务器的位置——地域(region)和可用区(zone),这个分配标准是与国际接轨的!
我们在Spring官网Eureka主题下高可用一节也看到了region和zone的概念,另外,在Eureka的Github仓库Eureka架构图上也看到区(zone)的概念,为了防止连接失效,我把相关内容截图过来了:
{kind=link}
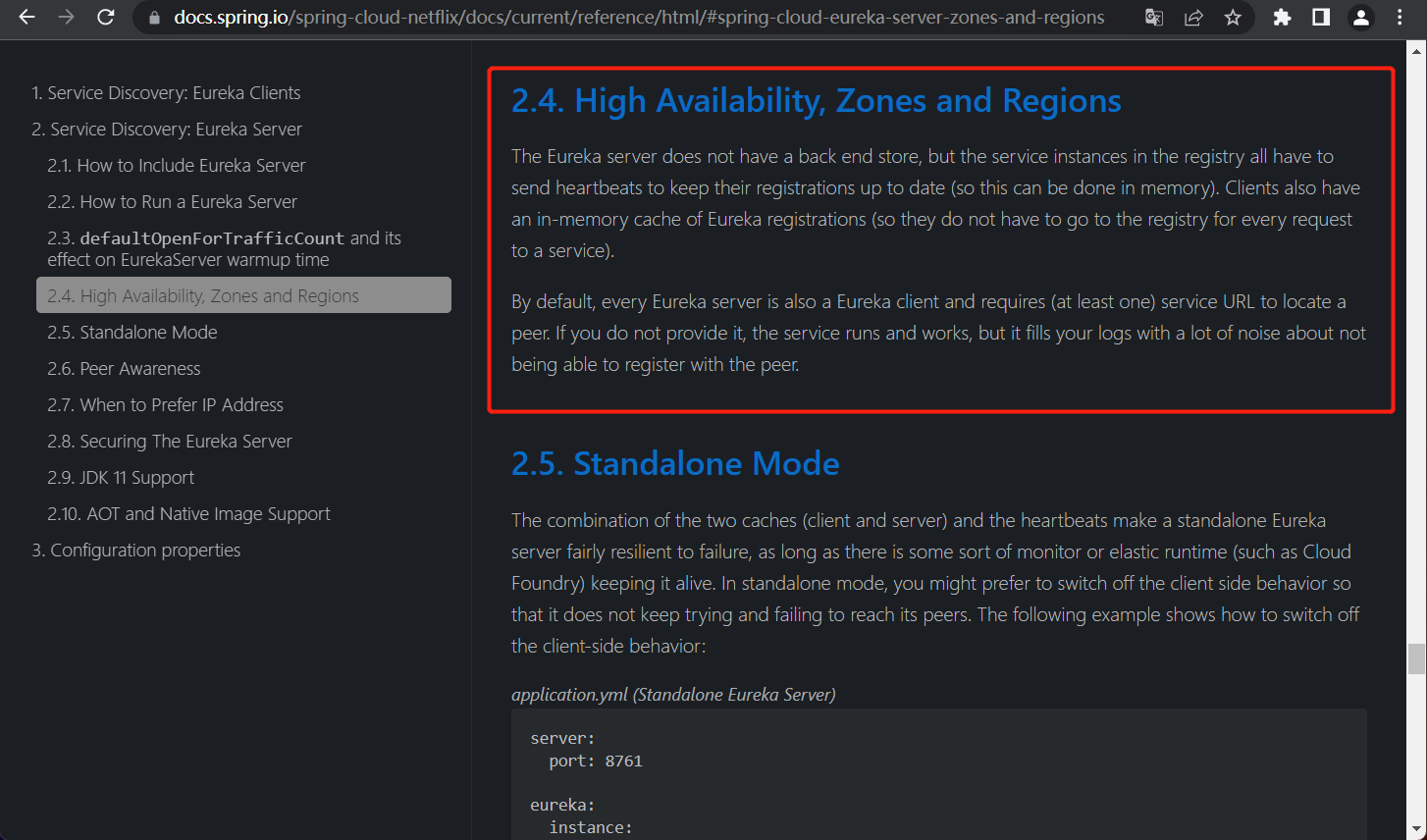
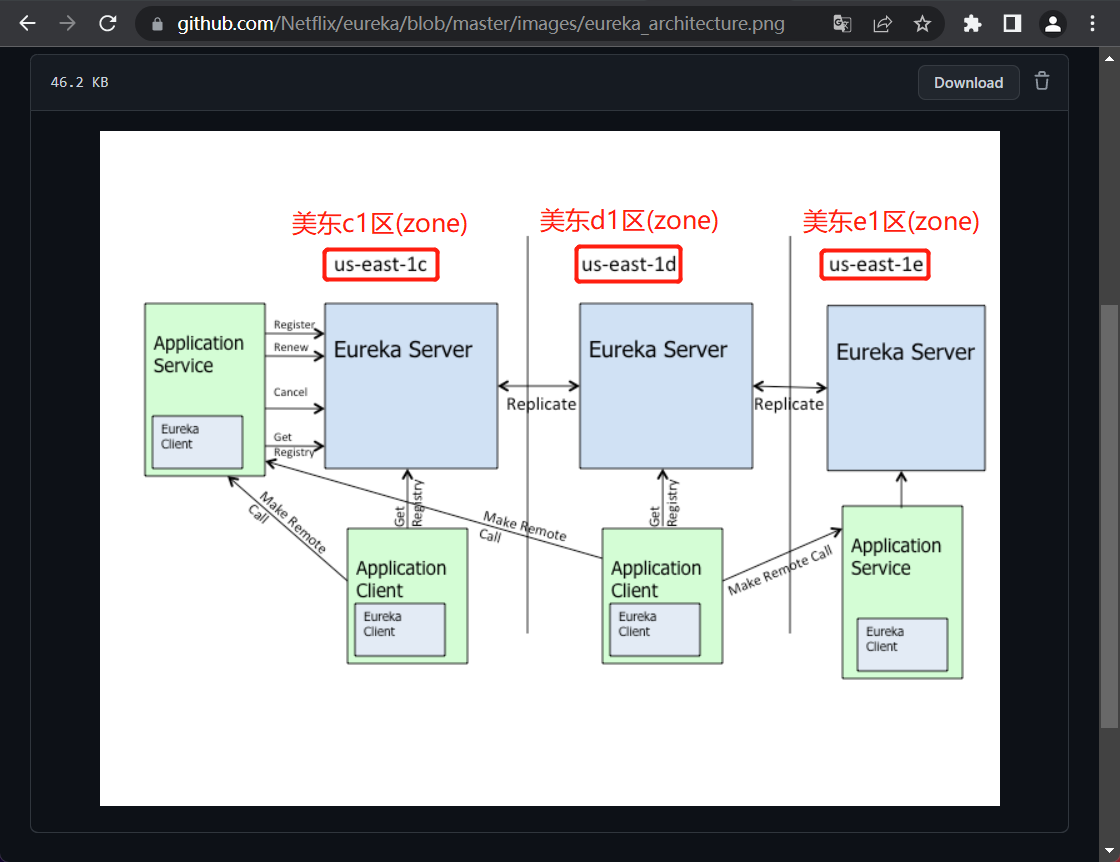
Eureka的高可用部署架构图官方已经给出来了,而且跟阿里云上可用区(zone)的划分是一样的,那么该怎么来配置和使用呢?接下来我们就来实操一下!
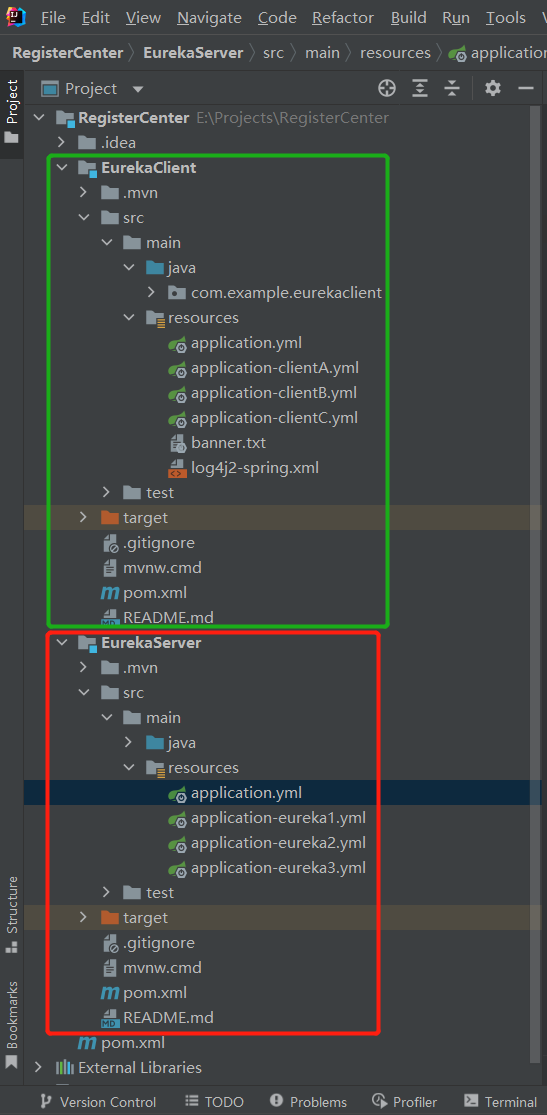
首先用IDEA创建好Eureka工程,我这里采用Maven多模块(module)的结构,将Eureka Server和Eureka Client端放在一个主工程下了:
这里要用到IDEA多实例运行的功能来模拟多区(zone)部署的情况(用端口的不同来模拟分区),该功能默认是关闭的,按下面截图方法打开它:
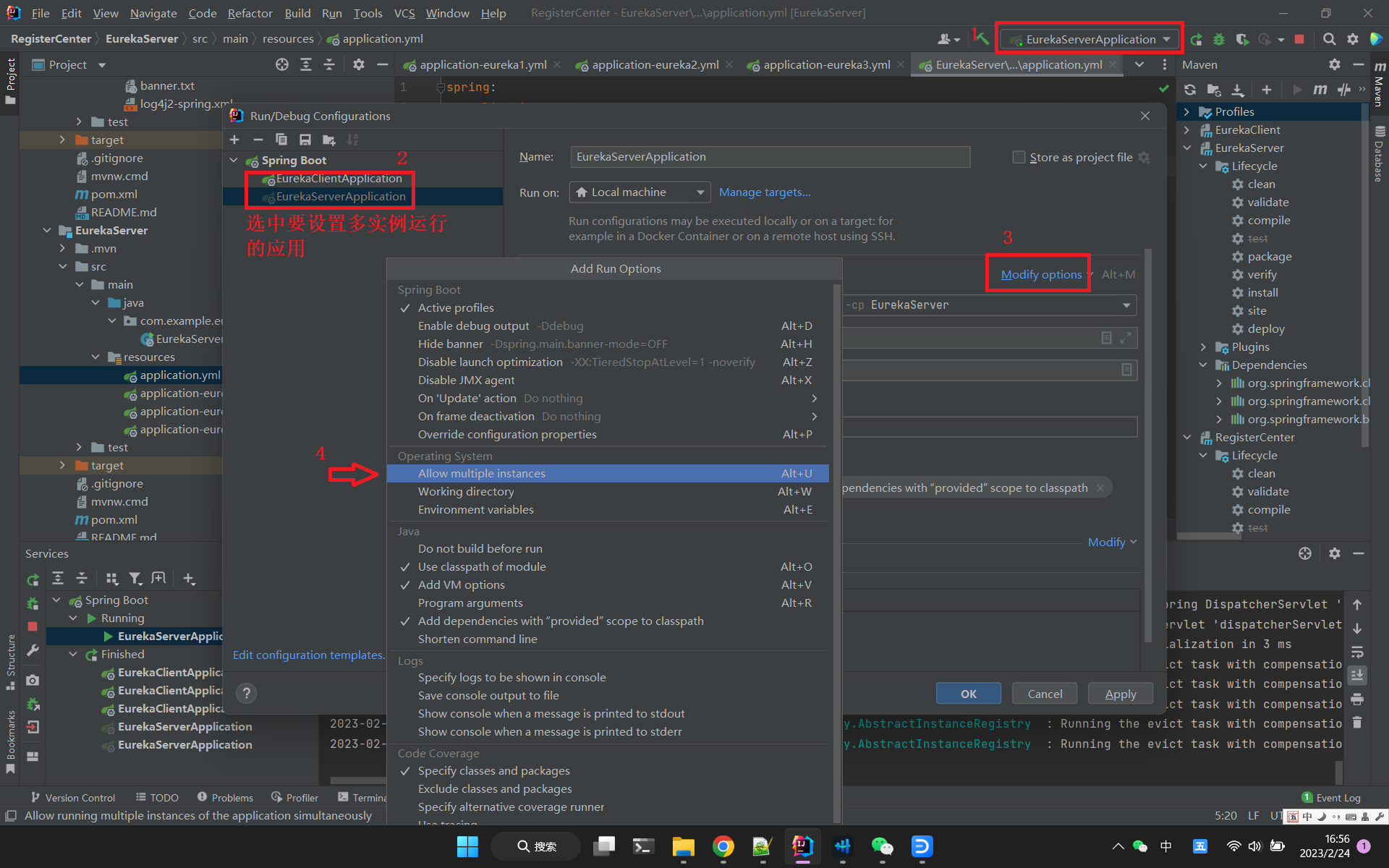
然后我们在相应应用的主配置文件application.yml里修改 spring:profiles:active: <目标配置> 并启动应用就可以了,每个目标配置里的端口不一样,用于模拟多机器的情况(真实环境是端口一样,IP不一样),先看一下效果截图,然后我会在后面贴出所有配置文件,配置文件里会有详细的说明,就不在正文说怎么配置了:


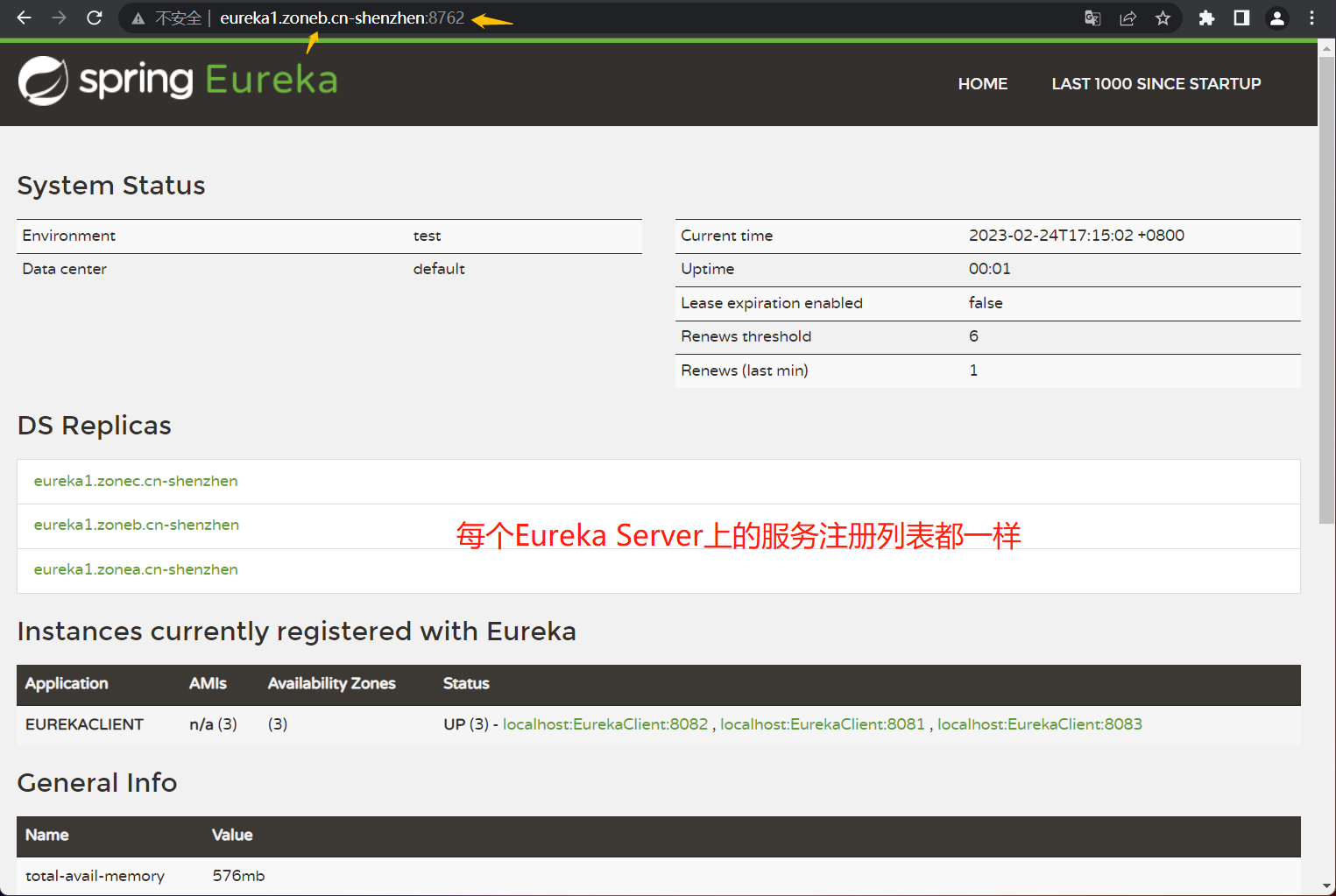
以下是重点内容,Eureka Server端的配置文件:
#Eureka Server的application.yml内容
spring:
application:
name: EurekaServer
profiles:
#多实例启动就改下这里(分别切换为eureka1、eureka2、eureka3)
active: eureka1
#Eureka Server的application-eureka1.yml内容
server:
port: 8761
#Eureka专用配置Begin
eureka:
instance:
metadata-map:
#声明自己所属的区
zone: zoneA
#自己是zoneA区的Eureka Server节点(取个容易识别的hostname)
hostname: eureka1.zonea.cn-shenzhen
#自己的IP,多块网卡时最好指定,多网卡自动绑定很容易出错(例如装了VMWare虚拟机的情况)
ip-address: 127.0.0.1
#优先使用IP
prefer-ip-address: true
client:
#声明自己所属的地区Region
region: cn-shenzhen
#列明可用的区Zone(注意顺序,优先将自己的区排前面)
availability-zones:
cn-shenzhen: zoneA,zoneB,zoneC
service-url:
#设置可用区Zone地址
zoneA: http://eureka1.zonea.cn-shenzhen:8761/eureka/
zoneB: http://eureka1.zoneb.cn-shenzhen:8762/eureka/
zoneC: http://eureka1.zonec.cn-shenzhen:8763/eureka/
#显示设置优先考虑请求同区Zone注册中心
prefer-same-zone-eureka: true
#自己作为服务端的客户端不需要像普通客户端一样去fetch服务列表,也不需要向任何服务端注册自己
fetch-registry: false
register-with-eureka: false
#Eureka Server的application-eureka2.yml内容
server:
port: 8762
#Eureka专用配置Begin
eureka:
instance:
metadata-map:
#声明自己所属的区
zone: zoneB
#自己是zoneB区的Eureka Server节点(取个容易识别的hostname)
hostname: eureka1.zoneb.cn-shenzhen
#自己的IP,多块网卡时最好指定,多网卡自动绑定很容易出错(例如装了VMWare虚拟机的情况)
ip-address: 127.0.0.1
#优先使用IP
prefer-ip-address: true
client:
#声明自己所属的地区Region
region: cn-shenzhen
#列明可用的区Zone(注意顺序,优先将自己的区排前面)
availability-zones:
cn-shenzhen: zoneB,zoneA,zoneC
service-url:
#设置可用区Zone地址
zoneA: http://eureka1.zonea.cn-shenzhen:8761/eureka/
zoneB: http://eureka1.zoneb.cn-shenzhen:8762/eureka/
zoneC: http://eureka1.zonec.cn-shenzhen:8763/eureka/
#显示设置优先考虑请求同区Zone注册中心
prefer-same-zone-eureka: true
#自己作为服务端的客户端不需要像普通客户端一样去fetch服务列表,也不需要向任何服务端注册自己
fetch-registry: false
register-with-eureka: false
#Eureka Server的application-eureka3.yml内容
server:
port: 8763
#Eureka专用配置Begin
eureka:
instance:
metadata-map:
#声明自己所属的区
zone: zoneC
#自己是zoneC区的Eureka Server节点(取个容易识别的hostname)
hostname: eureka1.zonec.cn-shenzhen
#自己的IP,多块网卡时最好指定,多网卡自动绑定很容易出错(例如装了VMWare虚拟机的情况)
ip-address: 127.0.0.1
#优先使用IP
prefer-ip-address: true
client:
#声明自己所属的地区Region
region: cn-shenzhen
#列明可用的区Zone(注意顺序,优先将自己的区排前面)
availability-zones:
cn-shenzhen: zoneC,zoneA,zoneB
service-url:
#设置可用区Zone地址
zoneA: http://eureka1.zonea.cn-shenzhen:8761/eureka/
zoneB: http://eureka1.zoneb.cn-shenzhen:8762/eureka/
zoneC: http://eureka1.zonec.cn-shenzhen:8763/eureka/
#显示设置优先考虑请求同区Zone注册中心
prefer-same-zone-eureka: true
#自己作为服务端的客户端不需要像普通客户端一样去fetch服务列表,也不需要向任何服务端注册自己
fetch-registry: false
register-with-eureka: false
以下是重点内容,Eureka Client端的配置文件:
#Eureka Client的application.yml内容
spring:
application:
name: EurekaClient
profiles:
#多实例启动就改下这里(分别切换为clientA、client2、client3)
active: clientA
main:
banner-mode: console #配置SpringBoot Actuator,开启服务信息和健康汇报接口(方便从Eureka Server界面直接点进相应服务查看服务信息)
management:
endpoints:
web:
exposure:
include: "*"
endpoint:
health:
show-details: always
shutdown:
enabled: true
#Eureka Client的application-clientA.yml内容
server:
port: 8081 #Eureka专用配置Begin
eureka:
instance:
metadata-map:
#声明自己所属的区Zone
zone: zoneA
client:
#声明自己所属的地区Region
region: cn-shenzhen
#列明可用的区Zone(注意顺序)
availability-zones:
cn-shenzhen: zoneA,zoneB,zoneC
service-url:
#设置可用区Zone地址
zoneA: http://eureka1.zonea.cn-shenzhen:8761/eureka/
zoneB: http://eureka1.zoneb.cn-shenzhen:8762/eureka/
zoneC: http://eureka1.zonec.cn-shenzhen:8763/eureka/
#显示设置优先考虑请求同区Zone注册中心
prefer-same-zone-eureka: true
#Eureka Client的application-clientB.yml内容
server:
port: 8082 #Eureka专用配置Begin
eureka:
instance:
metadata-map:
#声明自己所属的区Zone
zone: zoneB
client:
#声明自己所属的地区Region
region: cn-shenzhen
#列明可用的区Zone(注意顺序)
availability-zones:
cn-shenzhen: zoneB,zoneA,zoneC
service-url:
#设置可用区Zone地址
zoneA: http://eureka1.zonea.cn-shenzhen:8761/eureka/
zoneB: http://eureka1.zoneb.cn-shenzhen:8762/eureka/
zoneC: http://eureka1.zonec.cn-shenzhen:8763/eureka/
#显示设置优先考虑请求同区Zone注册中心
prefer-same-zone-eureka: true
#Eureka Client的application-clientC.yml内容
server:
port: 8083 #Eureka专用配置Begin
eureka:
instance:
metadata-map:
#声明自己所属的区Zone
zone: zoneC
client:
#声明自己所属的地区Region
region: cn-shenzhen
#列明可用的区Zone(注意顺序)
availability-zones:
cn-shenzhen: zoneC,zoneA,zoneB
service-url:
#设置可用区Zone地址
zoneA: http://eureka1.zonea.cn-shenzhen:8761/eureka/
zoneB: http://eureka1.zoneb.cn-shenzhen:8762/eureka/
zoneC: http://eureka1.zonec.cn-shenzhen:8763/eureka/
#显示设置优先考虑请求同区Zone注册中心
prefer-same-zone-eureka: true
客户端配置 availability-zones 时一定要注意顺序,要优先将自己所属的区(zone)排在前面,这样Eureka Client在发起续约(Renew)请求时,从所有可用区(zone)里第一个拿到的就是自己所在区(zone)的目标Eureka Server,否则就变成在其他服务器上续约,会导至自己区(zone)里的Eureka Server的Renews (last min)值永远达不到要求而报出以下错误(这个错误是由于前来本Eureka Server续约的服务低于指定的自我保证阈值(默认85%)了,触发了Eureka自我保护机制,Eureka Server不再剔除服务注册表里的条目):
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.
附上几张我自己画的Eureka Server常用部署架构图:
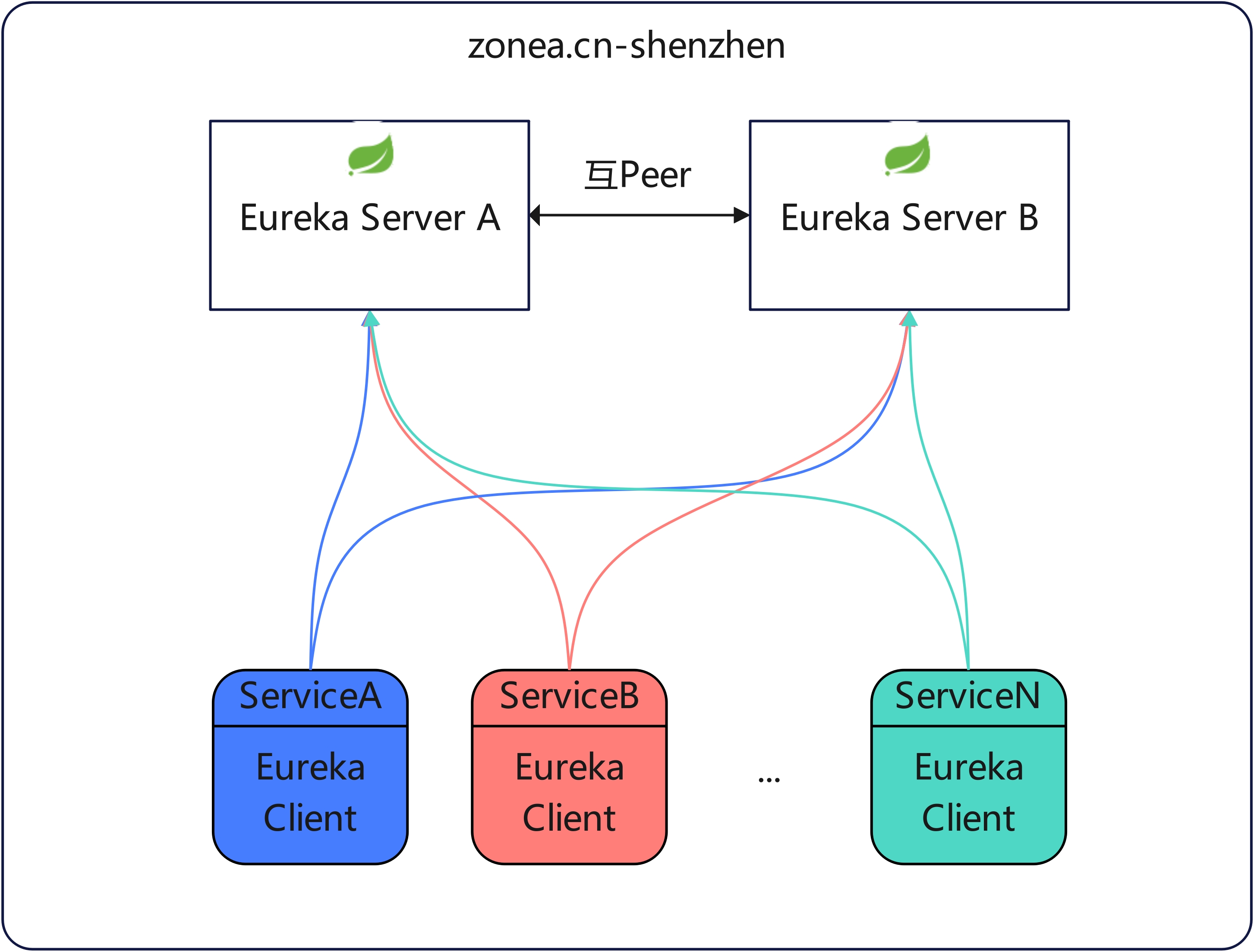
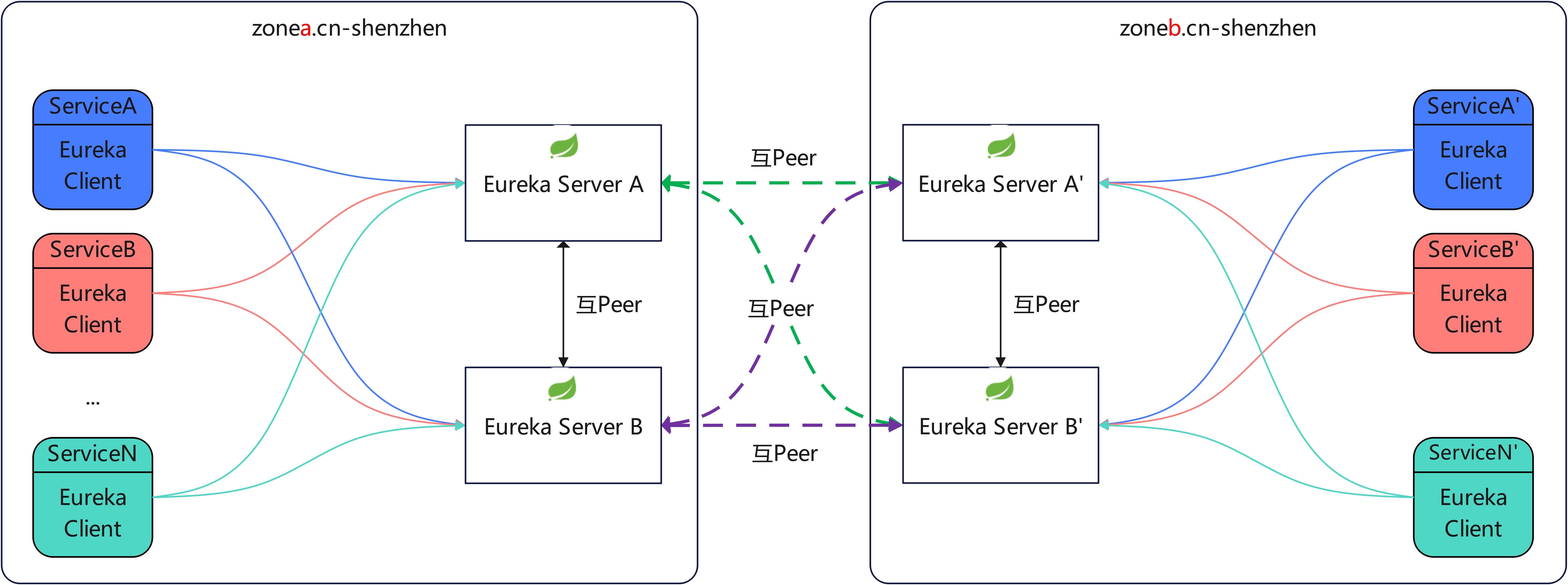
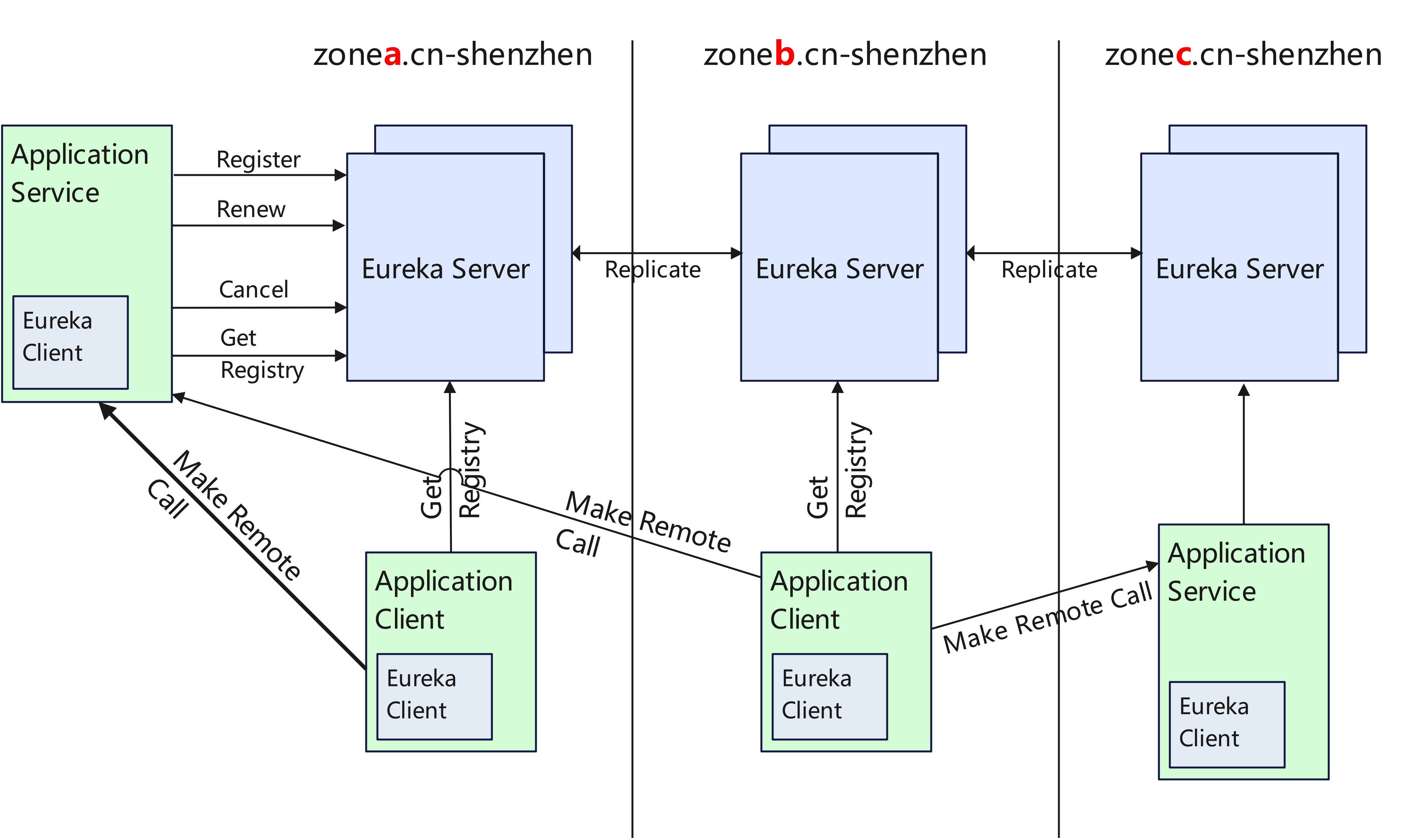
最后一张是针对官方的改进版,自己想一下这几张图服务端和客户端要怎么配!!!
Eureka高可用集群服务端和客户端配置的更多相关文章
- spring cloud 服务注册中心eureka高可用集群搭建
spring cloud 服务注册中心eureka高可用集群搭建 一,准备工作 eureka可以类比zookeeper,本文用三台机器搭建集群,也就是说要启动三个eureka注册中心 1 本文三台eu ...
- SpringCloud全家桶学习之服务注册与发现及Eureka高可用集群搭建(二)
一.Eureka服务注册与发现 (1)Eureka是什么? Eureka是NetFlix的一个子模块,也是核心模块之一.Eureka是一个基于REST的服务,用于定位服务,以实现云端中间层服务发现和故 ...
- SpringCloud(四):服务注册中心Eureka Eureka高可用集群搭建 Eureka自我保护机制
第四章:服务注册中心 Eureka 4-1. Eureka 注册中心高可用集群概述在微服务架构的这种分布式系统中,我们要充分考虑各个微服务组件的高可用性 问题,不能有单点故障,由于注册中心 eurek ...
- SpringCloud之Eureka高可用集群环境搭建
注册中心集群 在微服务中,注册中心非常核心,可以实现服务治理,如果一旦注册出现故障的时候,可能会导致整个微服务无法访问,在这时候就需要对注册中心实现高可用集群模式. Eureka集群相当简单:相互注册 ...
- 分布式架构高可用架构篇_02_activemq高可用集群(zookeeper+leveldb)安装、配置、高可用测试
参考: 龙果学院http://www.roncoo.com/share.html?hamc=hLPG8QsaaWVOl2Z76wpJHp3JBbZZF%2Bywm5vEfPp9LbLkAjAnB%2B ...
- 分布式架构高可用架构篇_activemq高可用集群(zookeeper+leveldb)安装、配置、高可用测试
原文:http://www.iteye.com/topic/1145651 从 ActiveMQ 5.9 开始,ActiveMQ 的集群实现方式取消了传统的Master-Slave 方式,增加了基于Z ...
- 服务注册组件——Eureka高可用集群搭建
服务注册组件--Eureka高可用集群搭建 什么是Eureka? 服务注册组件:将微服务注册到Eureka中. 为什么需要服务注册? 微服务开发重点在一个"微"字,大型应用拆分成微 ...
- openstack高可用集群15-后端存储技术—GlusterFS(分布式存储)
- Eureka高可用集群搭建
就是搭建Eureka的集群. 每个Eureka Server需要相互注册,确保数据一致. 我这里准备两个Eureka Server 他两的POM文件配置是一样的 <dependencies&g ...
- 高可用集群(HA)之Keeplived原理+配置过程
原理--> 通过vrrp协议,定义虚拟路由,在多个服务节点上进行转移. 通过节点优先级,将初始虚拟路由到优先级高的节点上,checker工作进程检测到主节点出问题时,则降低此节点优先级,从而实现 ...
随机推荐
- javaweb string
今天遇到一个跨域请求jsonp格式报错,其原因是其中一个参数过从我方数据库取出就带有换行格式的,类似于: 这条数据竟然自带格式换行. 而我们现常用的trim()只能去掉字符串的头部和尾部的空格, 而要 ...
- pyftpdlib中文乱码问题解决方案
python实现简易的FTP服务器 from pyftpdlib.authorizers import DummyAuthorizer from pyftpdlib.handlers import F ...
- 【sqoop】简介、原理、安装配置测试、导入导出案例、脚本打包、常见命令及参数介绍、常用命令举例
一.sqoop简介 用于在Hadoop(Hive)与传统的数据库(mysql.oracle...)之间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等 ...
- 乐观锁思想在JAVA中的实现——CAS
更多技术干活尽在个人公众号--JAVA旭阳 前言 生活中我们看待一个事物总有不同的态度,比如半瓶水,悲观的人会觉得只有半瓶水了,而乐观的人则会认为还有半瓶水呢.很多技术思想往往源于生活,因此在多个线程 ...
- snprintf拼接字符串
例如编辑一个txt文档,不断将字符输入,最终形成一个长句子.可以看成是字符串的不断拼接.snprintf函数具有这个功能. #include<stdio.h> void main(void ...
- 低代码开发平台YonBuilder移动开发,开发阅读APP教程
设计实现效果如下图: 主要包括书架,阅读,收藏功能. 经过分析,我们可以先实现底部导航功能,和书架列表页面. 1. 使用 tabLayout 高级窗口实现底部导航 . 使用tabLayout 有两 ...
- 【c#】分享一个简易的基于时间轮调度的延迟任务实现
在很多.net开发体系中开发者在面对调度作业需求的时候一般会选择三方开源成熟的作业调度框架来满足业务需求,比如Hangfire.Quartz.NET这样的框架.但是有些时候可能我们只是需要一个简易的延 ...
- 控制台运行java
控制台执行java 新建java代码 新建一个记事本文件,将文件名改为HelloWorld.java,注意:后缀是.java. 若没有显示文件后缀,可以在资源管理器打开显示后缀,然后再次修改文件名,一 ...
- [深度学习]DEEP LEARNING(深度学习)学习笔记整理
转载于博客http://blog.csdn.net/zouxy09 一.概述 Artificial Intelligence,也就是人工智能,就像长生不老和星际漫游一样,是人类最美好的梦想之中的一个. ...
- 使用SQL4Automation让CodeSYS连接数据库
摘要:本文旨在说明面向CodeSYS的数据库连接方案SQL4Automation的使用方法. 1.SQL4Automation简介 1.1.什么是SQL4Automation SQL4Auto ...