基础分类算法_KNN算法
KNN(K-NearestNeighbor)算法
KNN算法是有监督学习中的分类算法.
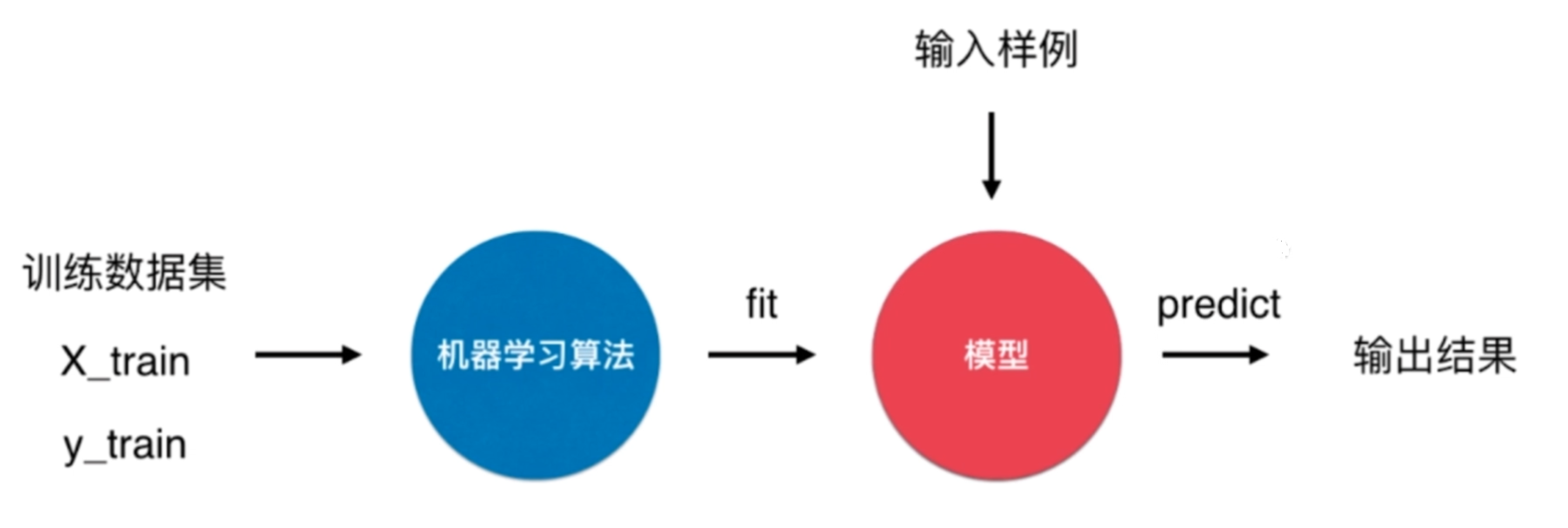
KNN算法很特殊,可以被认为是没有模型的算法,也可以认为其训练数据集就是模型本身。
KNN算法的原理
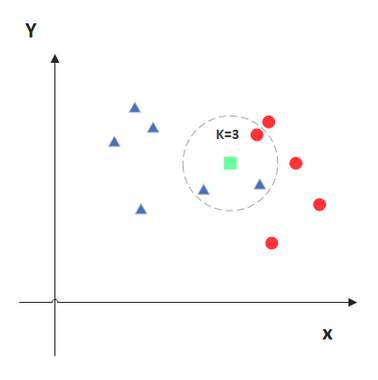
KNN的原理就是当预测一个新的值\(x\)的时候,根据它距离最近的\(K\)个点是什么类别来判断\(x\)属于哪个类别。
KNN算法的实现
实现knn算法需要计算两个点之前的距离,计算距离常用的有直线距离(欧拉距离)和曼哈顿距离。(这里使用欧拉距离来进行计算)
- 欧拉距离
\]
- 曼哈顿距离
\]
- 明可夫斯基距离
- \(p\)为超参数
- 默认值为\(2\)的时候取的为欧拉距离
\]
- 向量空间余弦相似度
一个向量空间中两个向量夹角间的余弦值作为衡量两个个体之间差异的大小,余弦值接近1,夹角趋于0,表明两个向量越相似,余弦值接近于0,夹角趋于90度,表明两个向量越不相似。
\]
- 皮尔森相关系数
两个变量之间的协方差和标准差的商
\frac{\mathrm{cov}(X,Y)}{\sigma_{X}\sigma_{Y}}
= \frac{E[(X-\mu_{x})(Y-\mu_{y})]}{\sigma_{X}\sigma_{Y}}
\]
import numpy as np
from math import sqrt
from collections import Counter
class KNN_Classifier:
def __init__(self, k):
# 初始化分类器
assert k >= 1, "k must be valid"
self.k = k
self._x_train = None
self._y_train = None
def fit(self, x_train, y_train):
# 根据训练集来训练
assert x_train.shape[0] == y_train.shape[0], \
"the size of x_train and y_train must be common"
assert self.k <= x_train.shape[0], \
"the size of train can't less than k"
self._x_train = x_train
self._y_train = y_train
return self
# 传入的需要预测的数据
def predict(self, x_predict):
assert self._x_train is not None and self._y_train is not None, \
"must fit it before predict"
assert x_predict.shape[1] == self._x_train.shape[1], \
"the feature number of x_predict must be equal to x_train"
y_predict = [self._predict(x) for x in x_predict]
return np.array(y_predict)
# 进行单个数据的预测
def _predict(self, x):
# 单个待测数据 返回预测结果
assert x.shape[0] == self._x_train.shape[1], \
"the feature number of x must be equal to x_train"
dis = [sqrt(np.sum((x_tem - x) ** 2)) for x_tem in self._x_train]
near = np.argsort(dis)
top_k = [self._y_train[i] for i in near[:self.k]]
return Counter(top_k).most_common(1)[0][0]
def __repr__(self):
return "KNN(k=%d)" % self.k
数据测试
- 测试数据
# 数据集
raw_data_x = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]]
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
x_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
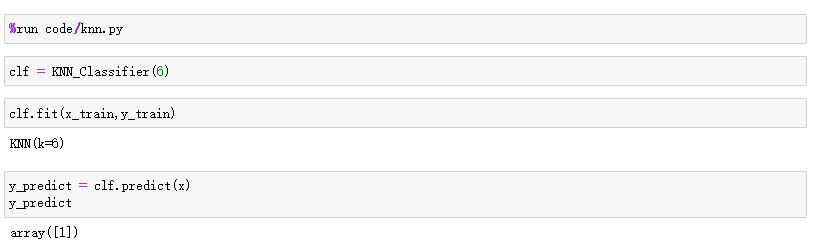
# 预测数据 (需要以矩阵的方式传入)
x = np.array([8.093607318, 3.365731514]).reshape(1,-1)
- 测试结果
KNN算法的优点
- 效果好
- 思想简单
- 对异常值不敏感。
- 需要的数学知识较少
- 直观完整的刻画机器学习应用的流程
KNN算法的缺点
- 计算复杂性高;空间复杂性高。
- 样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)
- 一般数值很大的时候不用这个,计算量太大。但是单个样本又不能太少,否则容易发生误分。
- 最大的缺点是无法给出数据的内在含义。
基础分类算法_KNN算法的更多相关文章
- 01--STL算法(算法基础)
一:算法概述 算法部分主要由头文件<algorithm>,<numeric>和<functional>组成. <algorithm>是所有STL头文件中 ...
- 数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列教程(二)之分类问题OneR算法 数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html 项目地址:G ...
- 【Java基础】数组和算法
数组和算法 查找算法 线性查找 ... 二分查找 二分查找要求数据结构是有序的. package com.parzulpan.java.ch03; /** * @Author : parzulpan ...
- 【java基础 8】垃圾收集算法及内存分配策略
本篇博客,主要介绍GC的收集算法以及根据算法要求所得的内存分配策略! 一.收集算法 收集算法,主要包括四种,分别是:Mark-Sweep(标记-清除).Copying(复制).Mark-Compact ...
- 最短路径算法-Dijkstra算法的应用之单词转换(词梯问题)(转)
一,问题描述 在英文单词表中,有一些单词非常相似,它们可以通过只变换一个字符而得到另一个单词.比如:hive-->five:wine-->line:line-->nine:nine- ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- 理解Liang-Barsky裁剪算法的算法原理
0.补充知识向量点积:结果等于0, 两向量垂直; 结果大于0, 两向量夹角小于90度; 结果小于0, 两向量夹角大于90度.直线的参数方程:(x1, y1)和(x2, y2)两点确定的直线, 其参数方 ...
- 网络流入门--最大流算法Dicnic 算法
感谢WHD的大力支持 最早知道网络流的内容便是最大流问题,最大流问题很好理解: 解释一定要通俗! 如右图所示,有一个管道系统,节点{1,2,3,4},有向管道{A,B,C,D,E},即有向图一张. ...
- 数据聚类算法-K-means算法
深入浅出K-Means算法 摘要: 在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. K-Mea ...
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
随机推荐
- 利用xtrabackup8完全,增量备份及还原MySQL8
利用xtrabackup8完全,增量备份及还原MySQL8 1.环境准备 服务器 作用 数据库版本 xtrabackup版本 10.0.0.8 数据备份 mysql8.0.26 8.0.28 10.0 ...
- 抓包分析 TCP 握手和挥手
前言 首先需要明确的是 TCP 是一个可靠传输协议,它的所有特点最终都是为了这个可靠传输服务.在网上看到过很多文章讲 TCP 连接的三次握手和断开连接的四次挥手,但是都太过于理论,看完感觉总是似懂非懂 ...
- nginx安装及相关操作
工作中经常用到nginx,今天写个自动部署nginx的脚本.nginx版本选用:1.20.2 1.创建nginx安装脚本(nginx.sh) [root@iZ2ze7uphtapcv51egcm7rZ ...
- vue 使用vuex 刷新时保存数据
created () { this.$store.replaceState(Object.assign(this.$store.state,JSON.parse(localStorage.getIte ...
- 思维分析逻辑 1 DAY
数据分析原则:坚决不做提数机器. 数据分析工作模块 日报 了解业务现状 提升数据敏感性 数据波动解释 周报 了解数据的短期趋势 版本迭代分析 为结论型报告背书 月报 梳理业务的流程 为决策提供部分建议 ...
- SpringBoot启动流程源码分析
前言 SpringBoot项目的启动流程是很多面试官面试中高级Java程序员喜欢问的问题.这个问题的答案涉及到了SpringBoot工程中的源码,也许我们之前看过别的大牛写过的有关SpringBoot ...
- day18-web工程路径
web工程路径 配置tomcat运行快捷键 tomcat启动的默认快捷键时shift+f10,可以自定义配置:file-setting-keymap-搜索run,找到右边写有shift+f10的选项, ...
- C++ 一个简洁的CHECK宏
#define CHECK2(condition, message) \ (!(condition)) ? (std::cerr << "Assertion failed: (& ...
- Centos安装Nodejs简单方式
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时.本文主要讲的是如何在Linux即Centos上安装Nodejs的简单方式,有比设置环境变量更加简单的方式,那就是设 ...
- Springboot自动装配源码及启动原理理解
Springboot自动装配源码及启动原理理解 springboot版本:2.2.2 传统的Spring框架实现一个Web服务,需要导入各种依赖JAR包,然后编写对应的XML配置文件 等,相较而言,S ...